
字节AI版小李子一开口:黄风岭,八百里
字节AI版小李子一开口:黄风岭,八百里字节和浙大联合研发的项目Loopy火了!
来自主题: AI技术研报
9114 点击 2024-09-13 21:22
 搜索
搜索
字节和浙大联合研发的项目Loopy火了!
“技术扼杀了人的创造力!” “摄影机剥夺了人们用眼睛体验那些独一无二的时刻的能力!” “在广告中使用AI创作的作品是对人类设计师的侮辱!是审美降级!” 尤其是AI应用井喷,且出现了一些“滥用”的情况之后,创意和技术似乎被推向了对立的两极。

“那张照片,会跟着我一辈子吗?”

你的脸也可以被“偷走”!
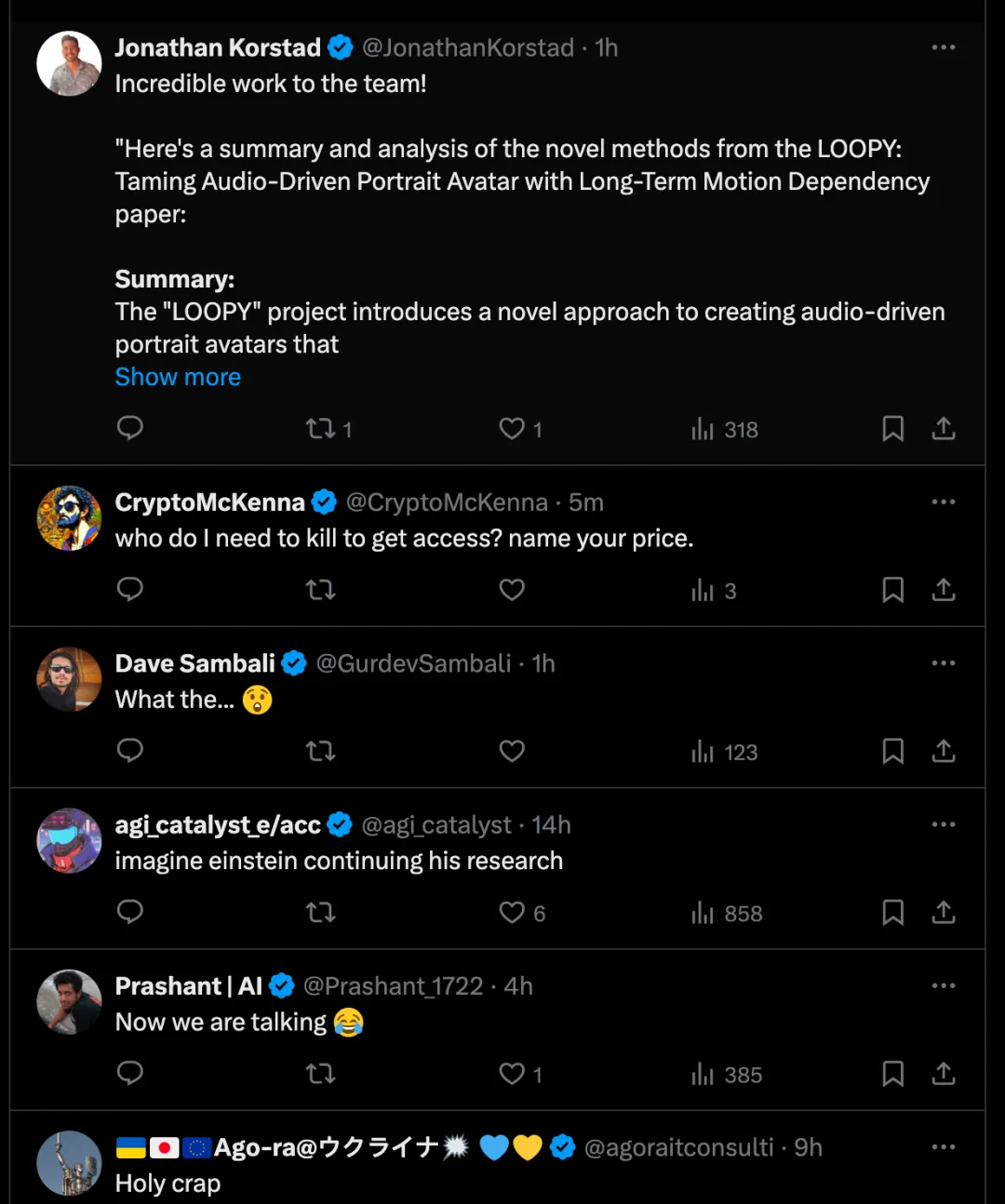
近期,来自字节跳动的视频生成模型 Loopy,一经发布就在 X 上引起了广泛的讨论。Loopy 可以仅仅通过一张图片和一段音频生成逼真的肖像视频,对声音中呼吸,叹气,挑眉等细节都能生成的非常自然,让网友直呼哈利波特的魔法也不过如此。

7 月份正式上线的国产视频大模型 Vidu,在今天发布大版本更新。

让AI视频中任意主体保持一致!就在刚刚,人人都可轻松做到了。

现在,中国的电影导演们开始尝试使用国产视频生成大模型技术制作电影级内容。

老黄预言AI生成游戏的未来,很快就要实现了!在一年一度Roblox开发者大会上,CEO官宣了3D基础模型,仅用文本提示便可生成3D物体。未来目标,便要瞄准10亿玩家,AI视频游戏大爆发时代不远了。

看过了 AI 视频生成工具清影的试用体验,今次我们来测试什么产品呢?就是此前上线的号称“首个国产纯自研视频大模型”的 Vidu (https://www.vidu.studio/)。该平台目前开放了文生视频、图生视频两大核心功能,提供 4 秒和 8 秒两种时长选择。