综合RLHF、DPO、KTO优势,统一对齐框架UNA来了
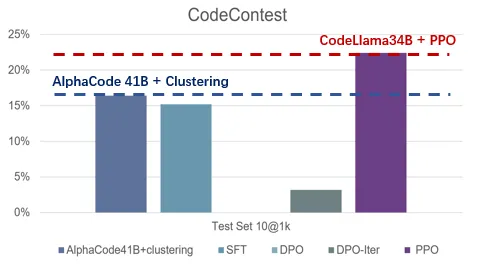
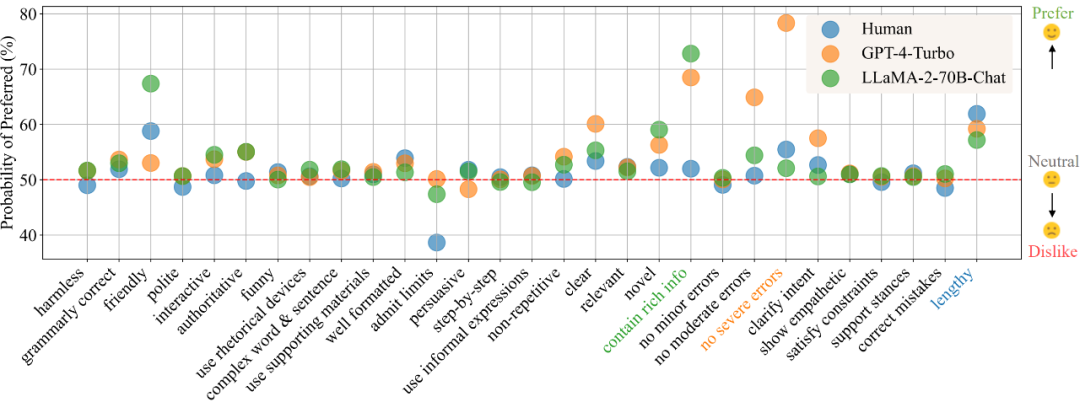
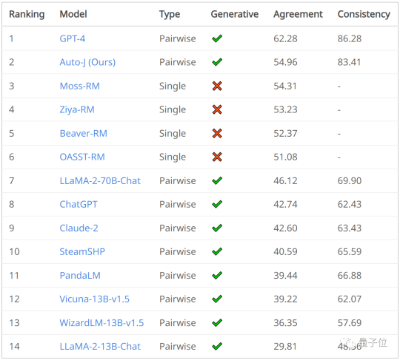
综合RLHF、DPO、KTO优势,统一对齐框架UNA来了随着大规模语言模型的快速发展,如 GPT、Claude 等,LLM 通过预训练海量的文本数据展现了惊人的语言生成能力。然而,即便如此,LLM 仍然存在生成不当或偏离预期的结果。这种现象在推理过程中尤为突出,常常导致不准确、不符合语境或不合伦理的回答。为了解决这一问题,学术界和工业界提出了一系列对齐(Alignment)技术,旨在优化模型的输出,使其更加符合人类的价值观和期望。
来自主题: AI技术研报
10232 点击 2024-10-10 12:21