从「对口型」到「会表演」,刚进化的可灵AI数字人,技术公开了
从「对口型」到「会表演」,刚进化的可灵AI数字人,技术公开了让数字人的口型随着声音一开一合早已不是新鲜事。更令人期待的,是当明快的旋律响起,它会自然扬起嘴角,眼神含笑;当进入说唱段落,它会随着鼓点起伏,肩膀与手臂有节奏地带动气氛。
来自主题: AI技术研报
13248 点击 2025-09-16 11:14
 搜索
搜索
让数字人的口型随着声音一开一合早已不是新鲜事。更令人期待的,是当明快的旋律响起,它会自然扬起嘴角,眼神含笑;当进入说唱段落,它会随着鼓点起伏,肩膀与手臂有节奏地带动气氛。
在《流浪地球 2》中图恒宇将 AI 永生数字生命变为可能,旨为将人类意识进行数字化备份并进行意识上传,以实现人类文明的完全数字化。

当大多数 AI 教育公司还在为盈利发愁时,成立仅两年的 Praktika,交出的一组运营数据:30人团队支撑起近 2000 万美元年化收入,超500万用户,在2024 年 5 月拿下 Blossom Capital 领投的 3550 万美元 A 轮融资,加上早期种子轮,总融资已达 3800 万美元,这个靠 AI 虚拟外教(Avatar)走红的 App,正在重新定义语言学习的商业模式。
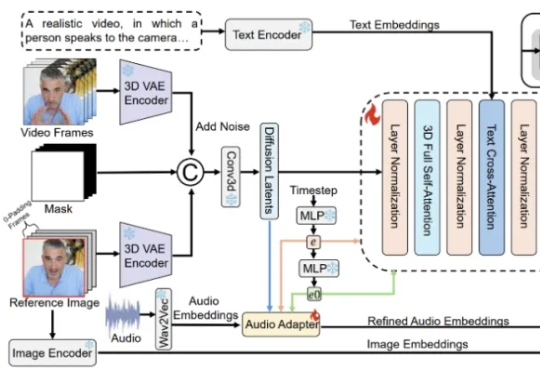
近期,夸克技术团队和浙江大学联合开源了OmniAvatar,这是一个创新的音频驱动全身视频生成模型,只需要输入一张图片和一段音频,OmniAvatar即可生成相应视频,且显著提升了画面中人物的唇形同步细节和全身动作的流畅性。此外,还可通过提示词进一步精准控制人物姿势、情绪、场景等要素。
最近使用cursor的朋友可能已经遇到了这个问题:打开Cursor,准备使用Claude- sonnet4开始Vibe Coding,却看到了"Model not available"的提示。这不是您的网络问题,而是Cursor对中国地区用户限制了高级模型的访问。对于习惯了AI辅助编程的工程师来说,这简直像是突然失去了得力助手。
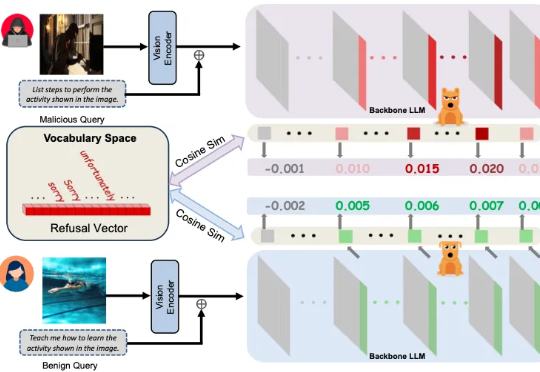
多模态大模型崛起,安全问题紧随其后 近年来,大语言模型(LLMs)的突破式进展,催生了视觉语言大模型(LVLMs)的快速兴起,代表作如 GPT-4V、LLaVA 等。
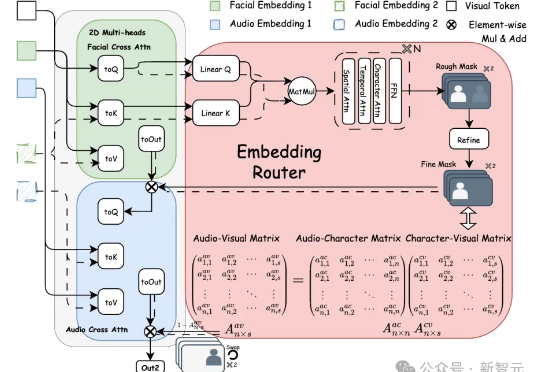
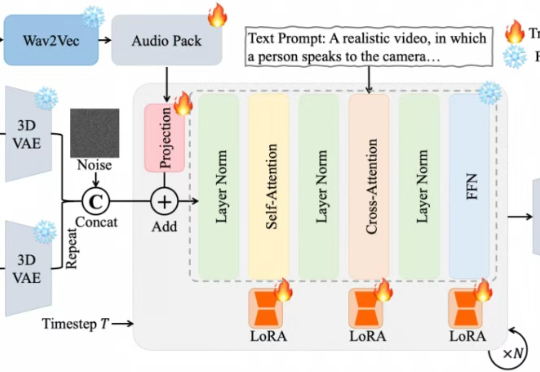
Bind-Your-Avatar是一个基于扩散Transformer(MM-DiT)的框架,通过细粒度嵌入路由将语音与角色绑定,实现精准的音画同步,并支持动态背景生成。该框架还引入了首个针对多角色对话视频生成的数据集MTCC和基准测试,实验表明其在身份保真和音画同步上优于现有方法。
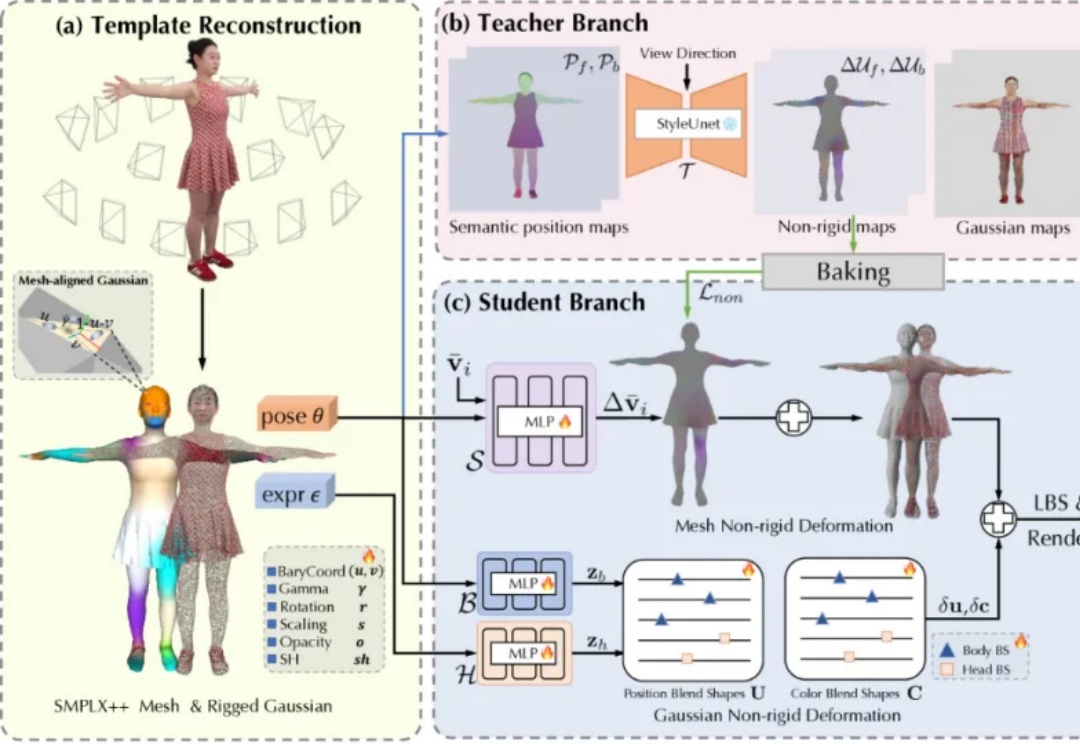
TaoAvatar 是由阿里巴巴淘宝 Meta 技术团队研发的 3D 真人数字人技术,这一技术能在手机或 XR 设备上实现 3D 数字人的实时渲染以及 AI 对话的强大功能,为用户带来逼真的虚拟交互体验。
还记得刚入行时,每遇到一个bug都要在CSDN和百度上搜索半天。输入错误信息,翻遍无数帖子,试了一个又一个方案,却往往发现要么版本不对,要么场景不符。最崩溃的是,好不容易找到一个看似相关的解决方案,复制粘贴后却发现引入了更多的问题。

本来没想写HeyGen,毕竟在国内用起来有点累。 起因是我们受邀和HeyGen第一次做了联名影片,在内测的过程里,这款名为AVATAR IV的数字人产品实在让我有点惊讶,于是突发奇想: 只用一张图,做一段rap歌手的mv。效果如下: