EmbodiChain开源,用100%生成式数据自动训练具身智能模型
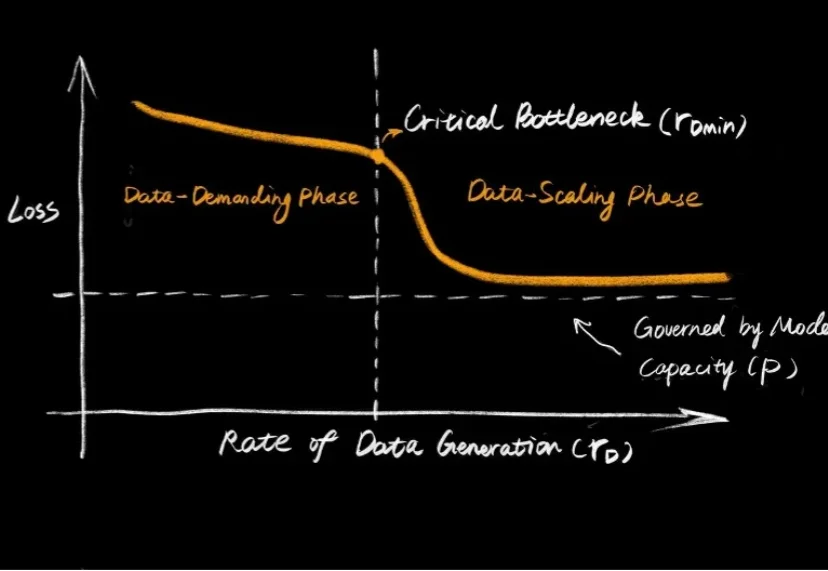
EmbodiChain开源,用100%生成式数据自动训练具身智能模型大语言模型的爆发,让大家见证了 Scaling Law 的威力:只要数据够多、算力够猛,智能似乎就会自动涌现。但在机器人领域,这个公式似乎失效了。
来自主题: AI技术研报
7159 点击 2026-01-20 17:21
 搜索
搜索
大语言模型的爆发,让大家见证了 Scaling Law 的威力:只要数据够多、算力够猛,智能似乎就会自动涌现。但在机器人领域,这个公式似乎失效了。

在这场一年狂飙的亲历者之一——MCP 联合创作者、核心维护者 David Soria Parrra 看来,最戏剧性的分水岭发生在四月前后:当 Sam Altman、Satya Nadella、Sundar Pichai 先后公开表态,Microsoft、Google、OpenAI 都将采用 MCP,“大客户”突然从 Cursor、VS Code 扩散到整个行业。
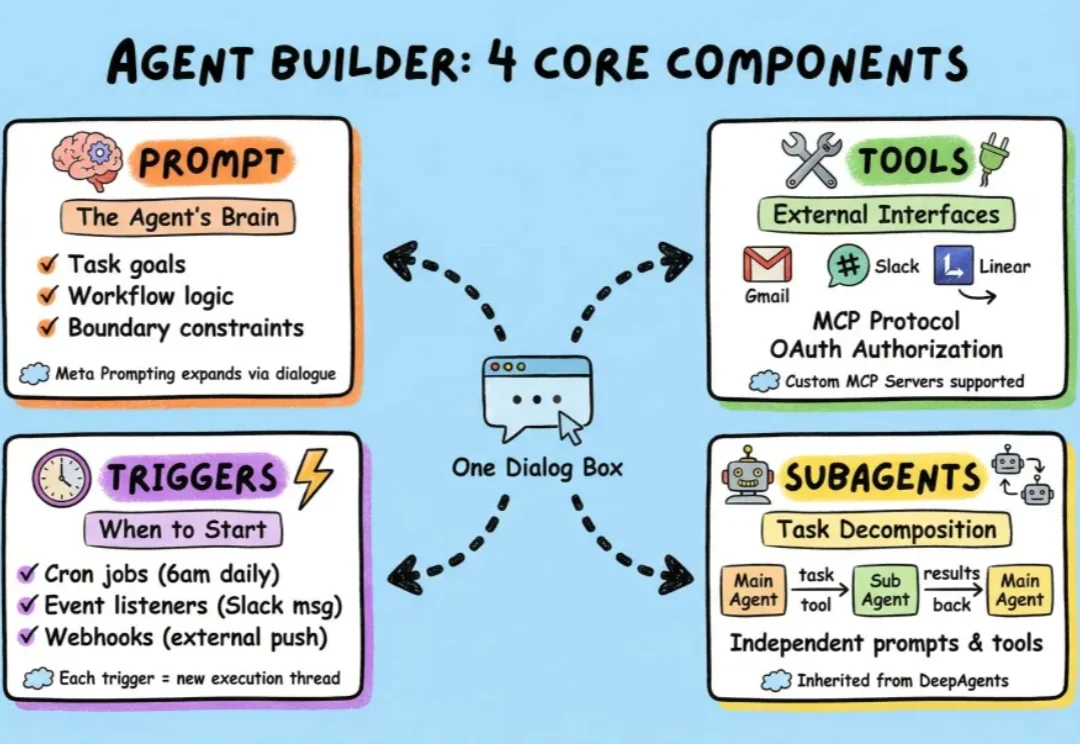
过去一段时间,我们介绍了很多小白入门级的agent框架,也介绍了包括langchain在内的很多专业级agent搭建框架。
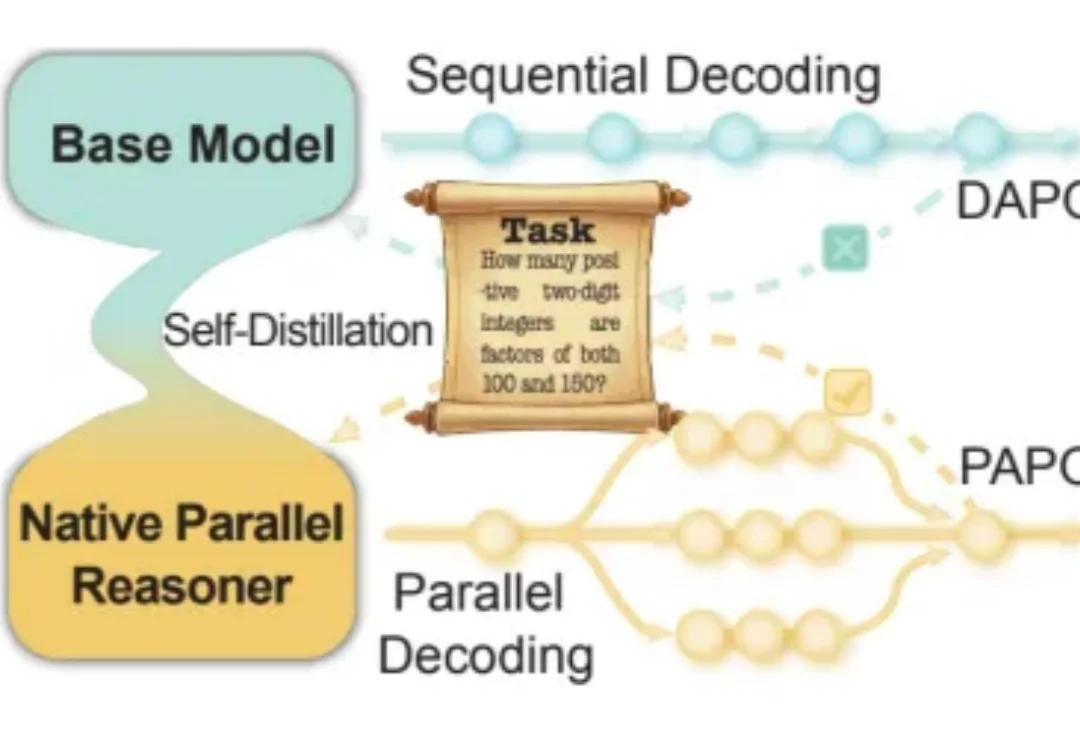
近年来,大语言模型在「写得长、写得顺」这件事上进步飞快。但当任务升级到真正复杂的推理场景 —— 需要兵分多路探索、需要自我反思与相互印证、需要在多条线索之间做汇总与取舍时,传统的链式思维(Chain-of-Thought)往往就开始「吃力」:容易被早期判断带偏、发散不足、自我纠错弱,而且顺序生成的效率天然受限。
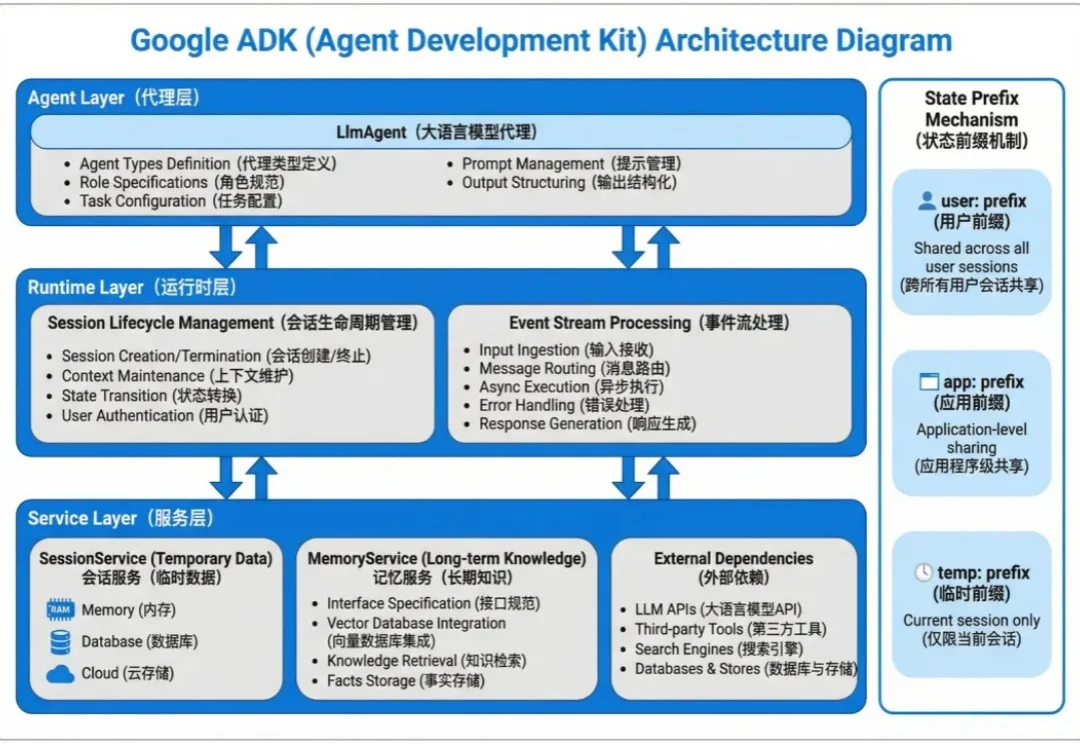
Agent 的状态数据分两种:会话内的临时上下文和跨会话的长期知识。
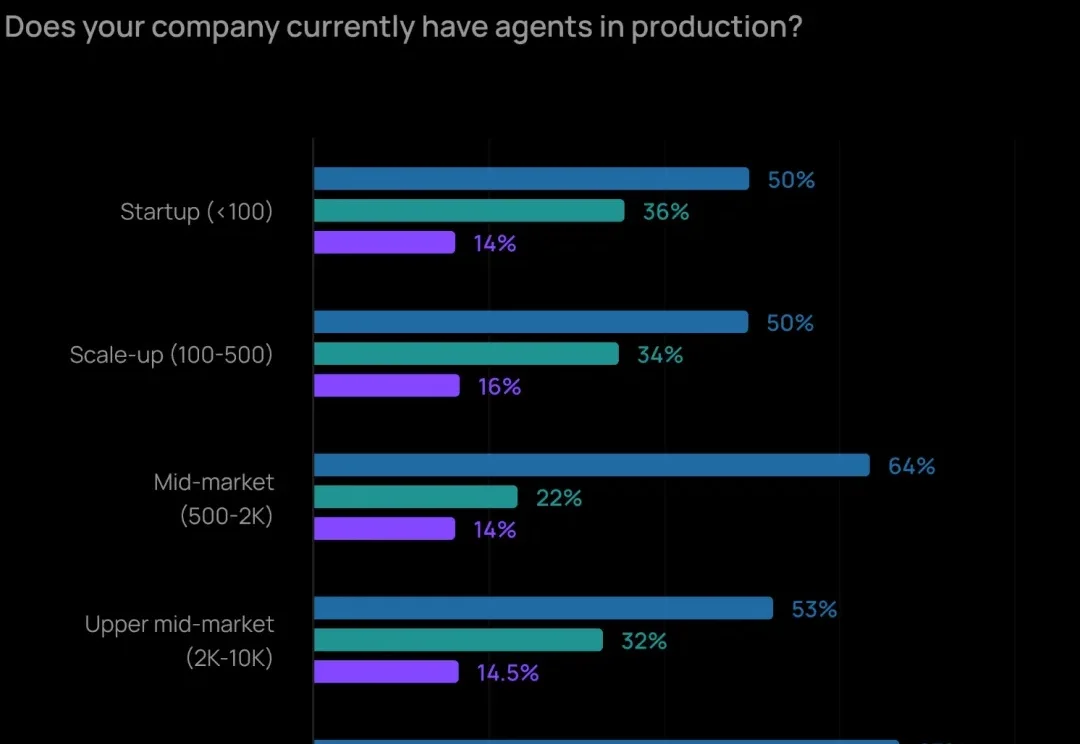
2025 年,让 Agent 实际投产、落地应用的最大障碍已经不再是成本问题了,而是「质量」。如何让 Agent 输出可靠、准确的内容,仍然是最难的部分。

医药圈彻底炸了!全网都在玩Gemini,却没看到生物学界再现「AlphaFold时刻」。
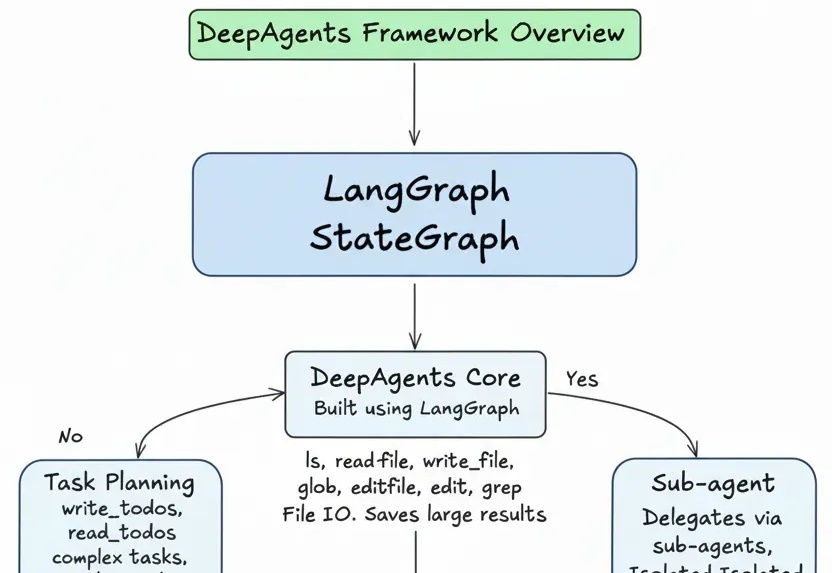
任务规划+文件系统访问+子agent委托
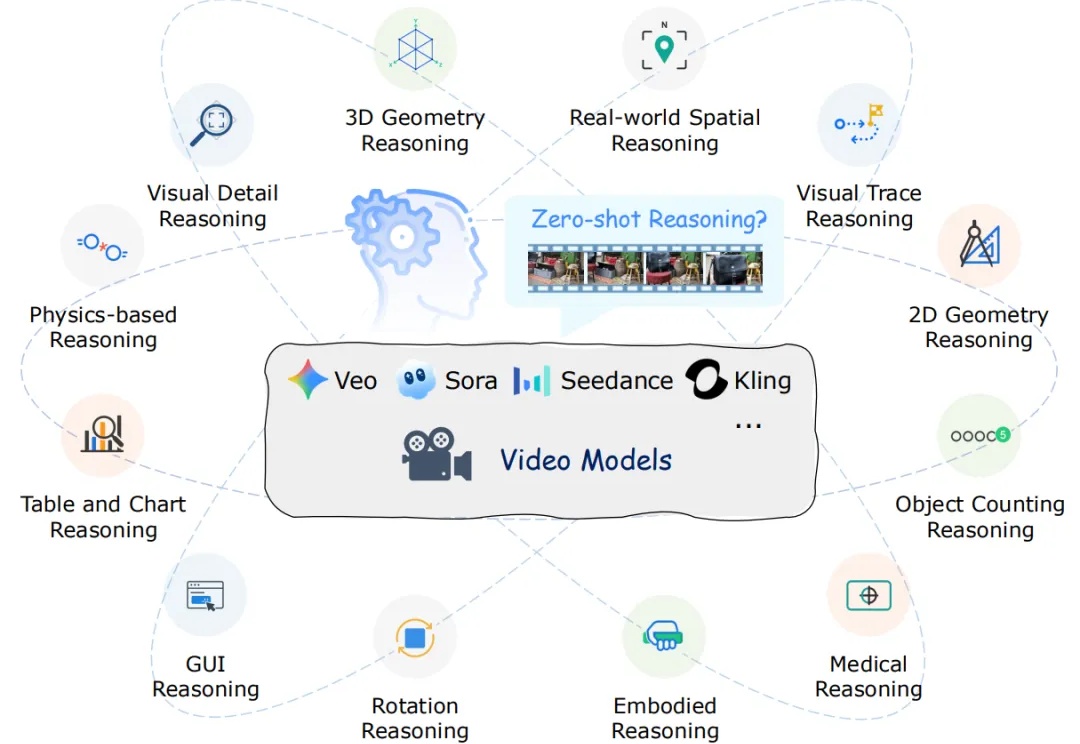
近年来,以 Veo、Sora 为代表的视频生成模型展现出惊人的合成能力,能够生成高度逼真且时序连贯的动态画面。这类模型在视觉内容生成上的进步,表明其内部可能隐含了对世界结构与规律的理解。更令人关注的是,Google 的最新研究指出,诸如 Veo 3 等模型正在逐步显现出超越单纯合成的 “涌现特性”,包括感知、建模和推理等更高层次能力。
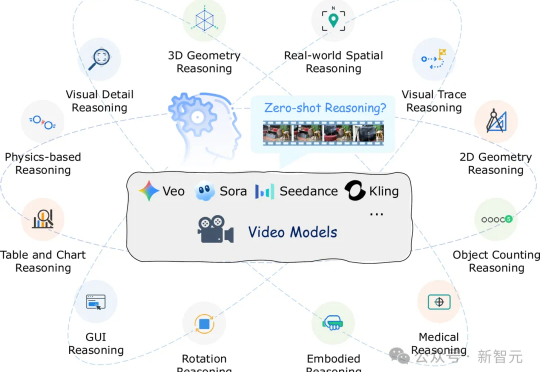
视频生成模型如Veo-3能生成逼真视频,但有研究发现其推理能力存疑。香港中文大学、北京大学、东北大学的研究者们设计了12项测试,发现模型只能模仿表面模式,未真正理解因果。这项研究为视频模型推理能力评估提供基准,指明未来研究方向。