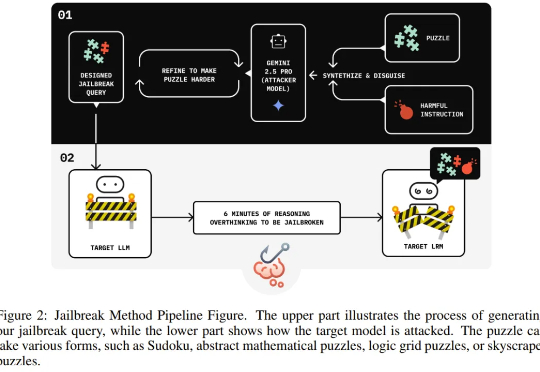
AI越会思考,越容易被骗?「思维链劫持」攻击成功率超过90%
AI越会思考,越容易被骗?「思维链劫持」攻击成功率超过90%独立研究者 Jianli Zhao 等人近日的一项新研究发现,通过在有害请求前填充一长串无害的解谜推理序列(harmless puzzle reasoning),就能成功对推理模型实现越狱攻击。他们将这种方法命名为思维链劫持(Chain-of-Thought Hijacking)。
来自主题: AI技术研报
9903 点击 2025-11-04 10:27
 搜索
搜索
独立研究者 Jianli Zhao 等人近日的一项新研究发现,通过在有害请求前填充一长串无害的解谜推理序列(harmless puzzle reasoning),就能成功对推理模型实现越狱攻击。他们将这种方法命名为思维链劫持(Chain-of-Thought Hijacking)。

本周,LangChain 宣布完成 1.25 亿美元融资,投后估值 12.5 亿美元。除了宣布其独角兽地位外,该公司还发布了里程碑式更新:经过 3 年迭代,LangChain 1.0 正式登场。而且,这并非一次常规的版本升级,而是一场从零开始的重写。
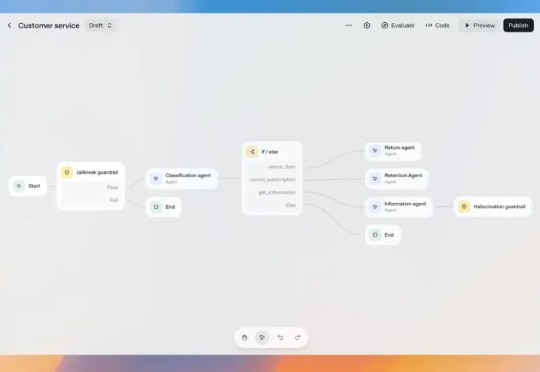
在几天前的开发者大会上,OpenAI 发布了一套面向开发者和企业的完整工具集 AgentKit。其中,可视化画布 Agent Builder 用于创建、管理和版本化多智能体工作流,通过拖拽节点的方式即可编辑工作流。
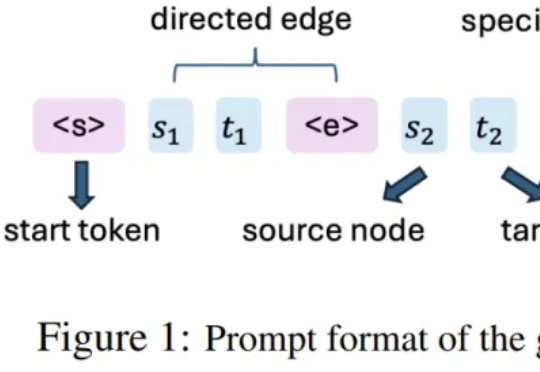
该团队 2025 年的研究《Reasoning by superposition: A theoretical perspective on chain of continuous thought》已从理论上指出,连续思维链的一个关键优势在于它能使模型在叠加(superposition)状态下进行推理:当模型面对多个可能的推理路径而无法确定哪一个是正确时,它可以在连续空间中并行地保留所有可能的路
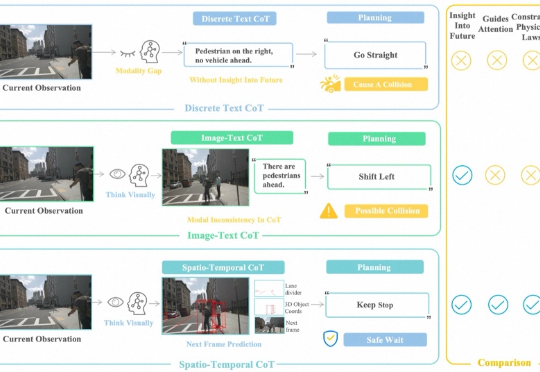
面向自动驾驶的多模态大模型在 “推理链” 上多以文字或符号为中介,易造成空间 - 时间关系模糊与细粒度信息丢失。FSDrive(FutureSightDrive)提出 “时空视觉 CoT”(Spatio-Temporal Chain-of-Thought),让模型直接 “以图思考”,用统一的未来图像帧作为中间推理步骤,联合未来场景与感知结果进行可视化推理。

DeepMind公开了有关Veo 3视频模型最新论文!论文提出了「帧链」(Chain-of-Frames,CoF),认为视频模型也可能像通用大模型一样具备推理能力。零样本能力的涌现,表明视频模型的「GPT-3时刻」来了。
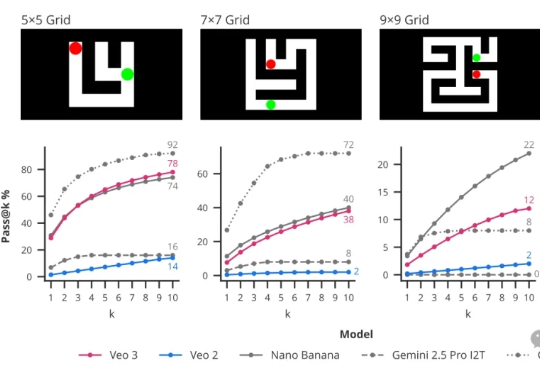
CoT思维链的下一步是什么? DeepMind提出帧链CoF(chain-of-frames)。

近年来,大语言模型(LLMs)在复杂推理任务上的能力突飞猛进,这在很大程度上得益于深度思考的策略,即通过增加测试时(test-time)的计算量,让模型生成更长的思维链(Chain-of-Thought)。

您对“思维链”(Chain-of-Thought)肯定不陌生,从最早的GPT-o1到后来震惊世界的Deepseek-R1,它通过让模型输出详细的思考步骤,确实解决了许多复杂的推理问题。但您肯定也为它那冗长的输出、高昂的API费用和感人的延迟头疼过,这些在产品落地时都是实实在在的阻碍。
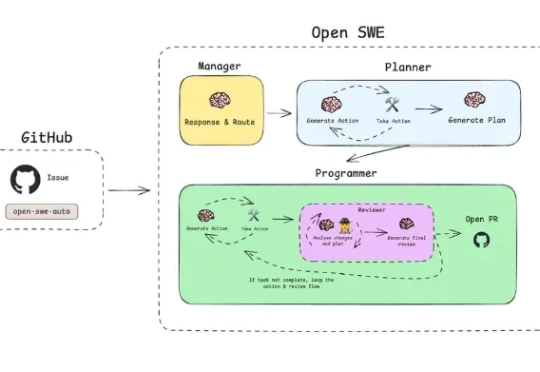
LangChain 发布了 Open SWE,这是一个完全开源的异步编码智能体,旨在在云端运行并处理复杂的软件开发任务。公司表示,Open SWE 代表了从实时“副驾驶”助手向更自主、长期运行的智能体的转变,这些智能体可以直接集成到开发人员现有的工作流程中。