
第二属性大于 AI 能力,像编剧一样做产品 |对话美图AKA小白
第二属性大于 AI 能力,像编剧一样做产品 |对话美图AKA小白聊了一个小时,美图CPO——首席产品官陈剑毅(花名小白)几乎没提过「参数」两个字。
来自主题: AI资讯
9575 点击 2026-06-23 15:02
 搜索
搜索
聊了一个小时,美图CPO——首席产品官陈剑毅(花名小白)几乎没提过「参数」两个字。
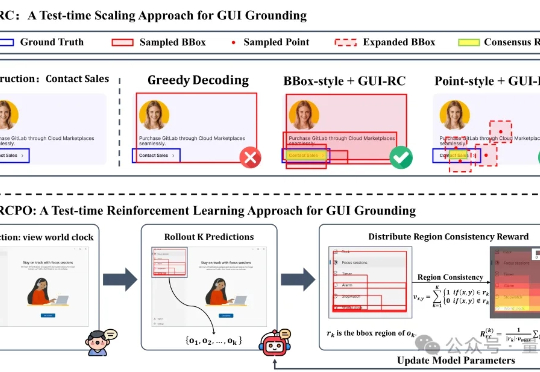
无需海量数据标注,智能体也能精确识别定位目标元素了! 来自浙大等机构的研究人员提出GUI-RCPO——一种自我监督的强化学习方法,可以让模型在没有标注的数据上自主提升GUI grounding(图形界面定位)能力。
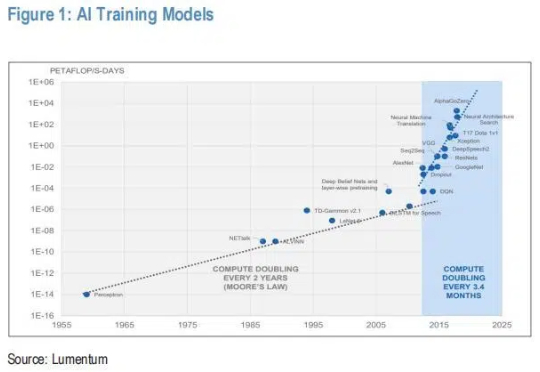
CPO:来得更快,但颠覆性远低于恐慌预期 摩根大通指出CPO(共封装光学)产业链接近爆发临界点,2025年下半年即将量产。
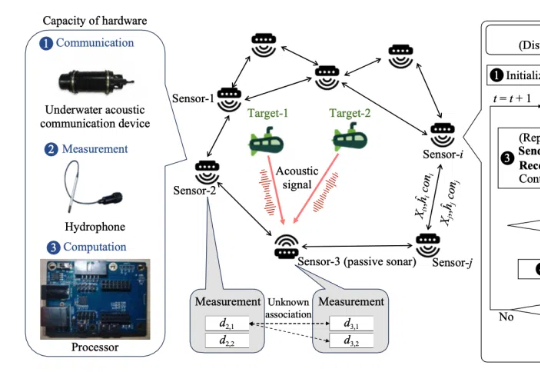
多智能体系统分布式共识优化的一系列研究来了!

今天凌晨,OpenAI 发布了新模型 GPT-4.1,相对比 4o,GPT-4.1 在编程和指令遵循方面的能力显著提升,同时还宣布 GPT-4.5 将会在几个月后下线。不少人吐槽 OpenAI 让人迷惑的产品发布逻辑——GPT-4.1 晚于 4.5 发布,以及混乱的模型命名,这些问题,都能在 OpenAI CPO Kevin Weil 最近的一期播客访谈中得到解答。

AI 与 SaaS 的结合,有哪些可能性?

在GTC2025大会上,NVIDIA依旧延续着“算力的故事”。如果AI的发展依旧遵循着scaling law(规模定律),那么这个故事还能继续讲下去。

CMU团队用LCPO训练了一个15亿参数的L1模型,结果令人震惊:在数学推理任务中,它比S1相对提升100%以上,在逻辑推理和MMLU等非训练任务上也能稳定发挥。更厉害的是,要求短推理时,甚至击败了GPT-4o——用的还是相同的token预算!

Anthropic 最近动作不断。

传统的训练方法通常依赖于大量人工标注的数据和外部奖励模型,这些方法往往受到成本、质量控制和泛化能力的限制。因此,如何减少对人工标注的依赖,并提高模型在复杂推理任务中的表现,成为了当前的主要挑战之一。