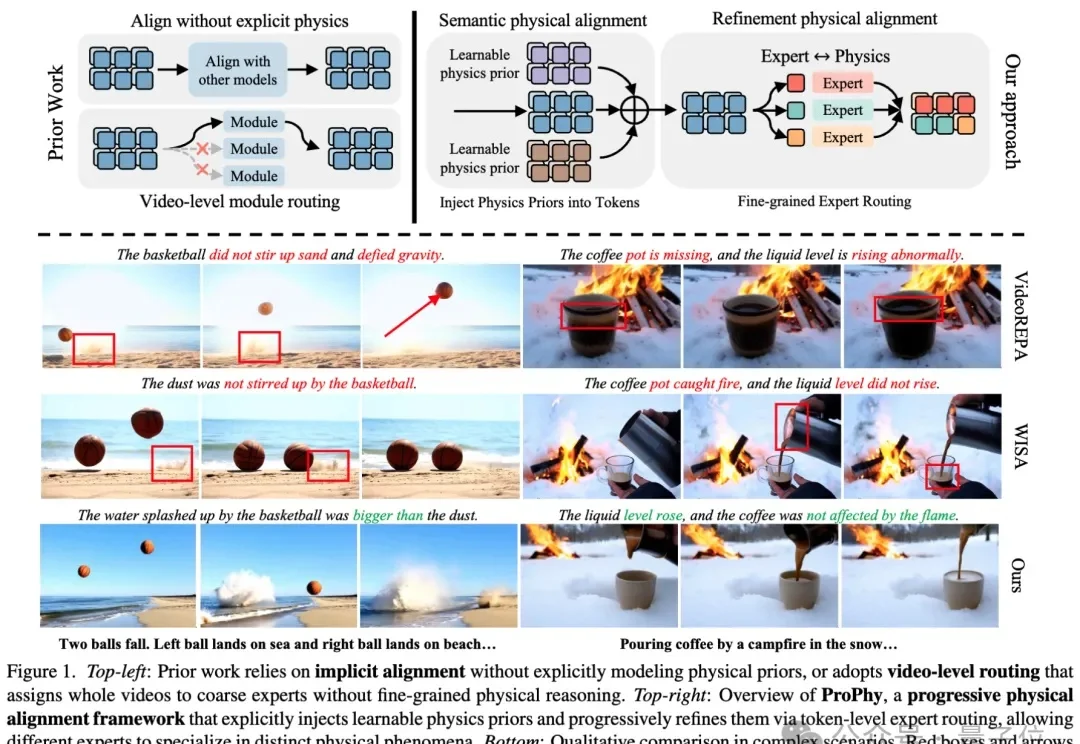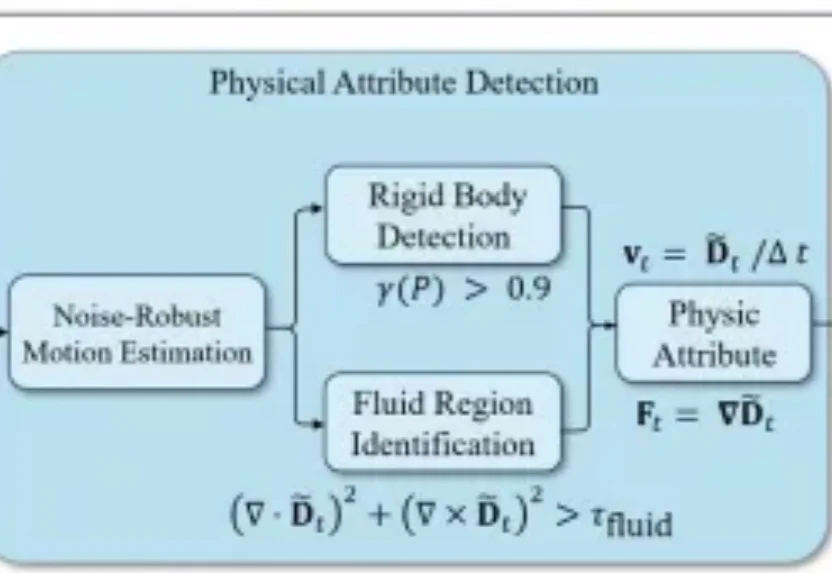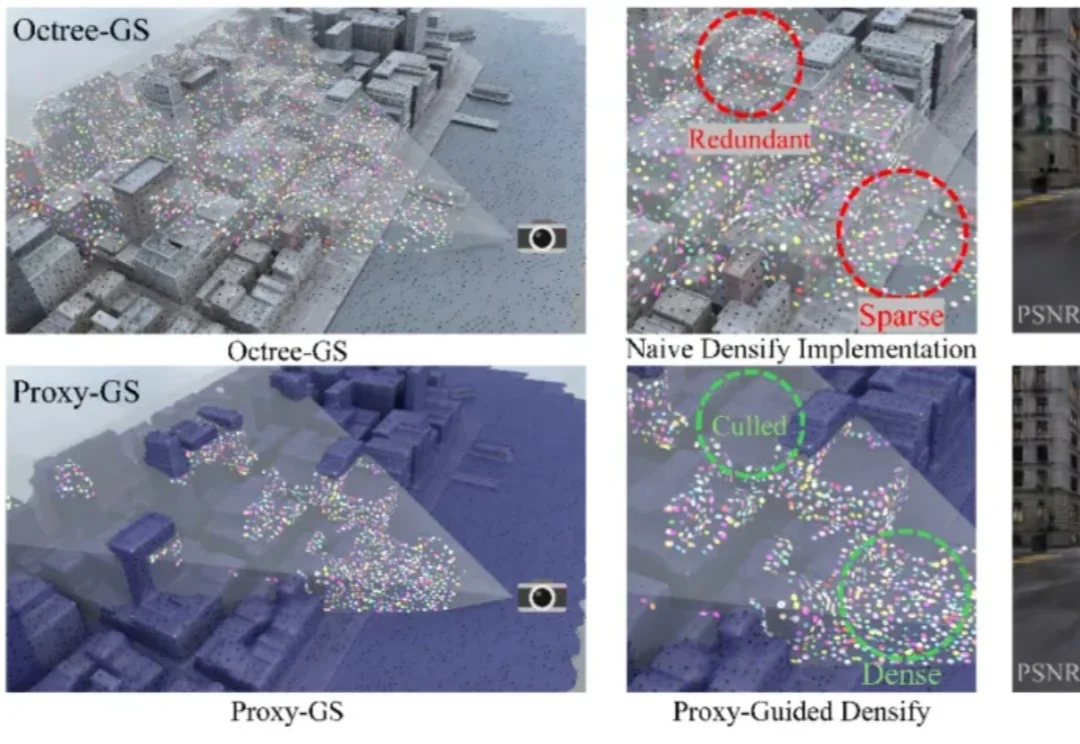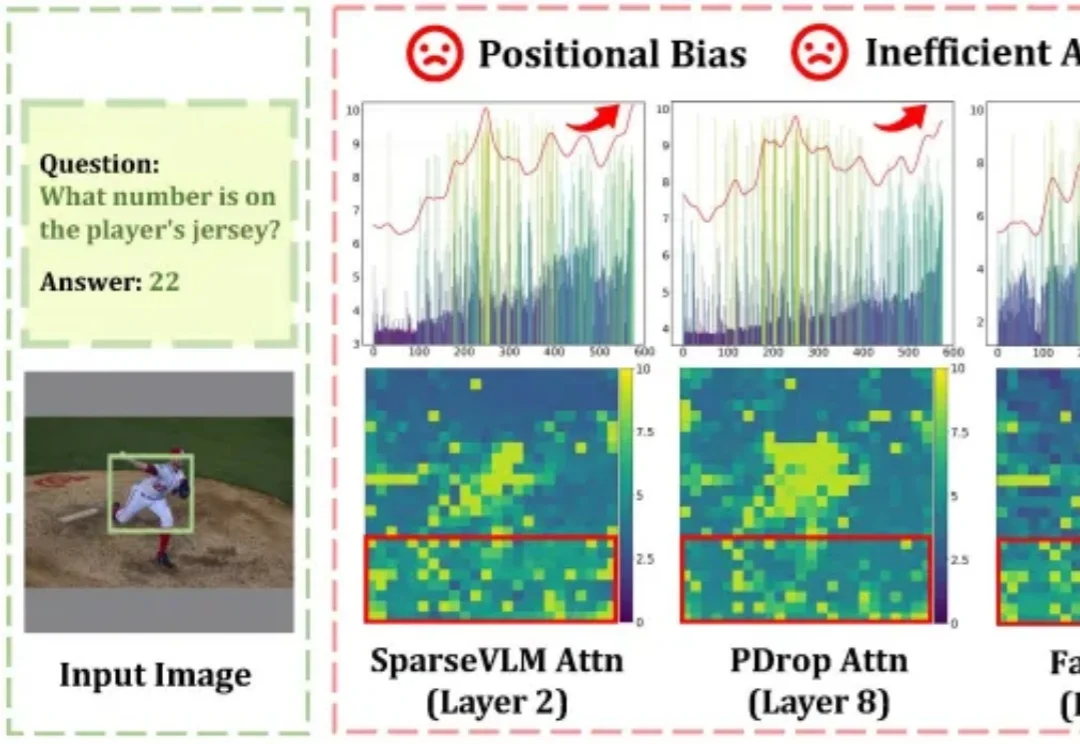
CVPR 2026 | EmoStyle:情感也能“风格化”?深大VCC带你见证魔法!
CVPR 2026 | EmoStyle:情感也能“风格化”?深大VCC带你见证魔法!EmoStyle 由深圳大学可视计算研究中心黄惠教授课题组独立完成,第一作者为杨景媛助理教授,第二作者为研二硕士生柏梓桓。深圳大学可视计算研究中心(VCC)以计算机图形学、计算机视觉、人机交互、机器学习、具身智能、可视化和可视分析为学科基础,致力前沿探索与跨学科创新。
来自主题: AI技术研报
7671 点击 2026-03-20 10:18