中国AI开源16强,最新出炉
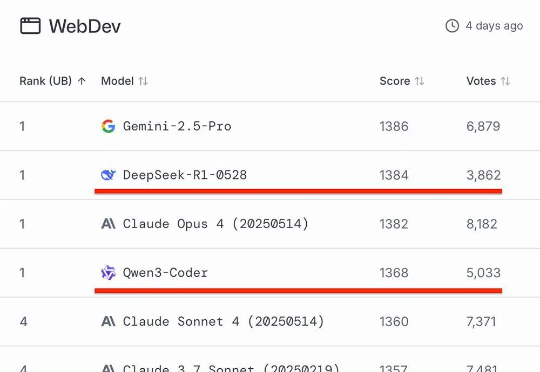
中国AI开源16强,最新出炉知名AI大模型评测Chatbot Arena放榜!阿里Qwen3-235B-A22B-Instruct-2507位列大语言模型总榜第三,月之暗面Kimi-K2-0711-preview、深度求索DeepSeek-R1-0528并列为总榜第五,以开源之姿超越Claude 4、GPT-4.1等顶尖闭源模型。
来自主题: AI资讯
11438 点击 2025-08-05 10:47
 搜索
搜索
知名AI大模型评测Chatbot Arena放榜!阿里Qwen3-235B-A22B-Instruct-2507位列大语言模型总榜第三,月之暗面Kimi-K2-0711-preview、深度求索DeepSeek-R1-0528并列为总榜第五,以开源之姿超越Claude 4、GPT-4.1等顶尖闭源模型。

近期,随着OpenAI-o1/o3和Deepseek-R1的成功,基于强化学习的微调方法(R1-Style)在AI领域引起广泛关注。这些方法在数学推理和代码智能方面展现出色表现,但在通用多模态数据上的应用研究仍有待深入。
近年来,OpenAI o1 和 DeepSeek-R1 等模型的成功证明了强化学习能够显著提升语言模型的推理能力。通过基于结果的奖励机制,强化学习使模型能够发展出可泛化的推理策略,在复杂问题上取得了监督微调难以企及的进展。
当人工智能已经能下围棋、写代码,如何让机器理解并证明数学定理,仍是横亘在科研界的重大难题。
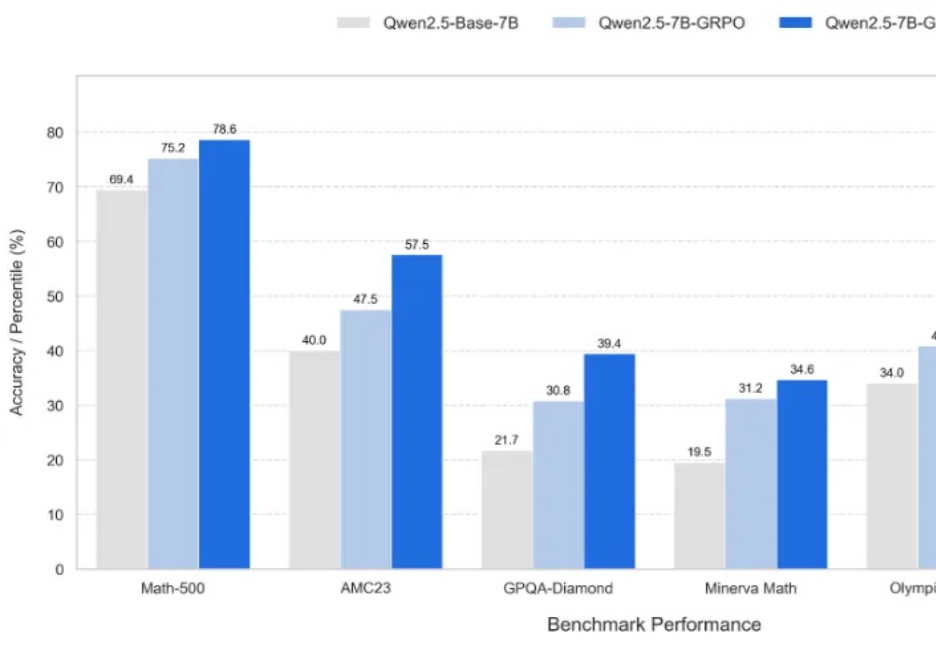
新一代大型推理模型,如 OpenAI-o3、DeepSeek-R1 和 Kimi-1.5,在复杂推理方面取得了显著进展。该方向核心是一种名为 ZERO-RL 的训练方法,即采用可验证奖励强化学习(RLVR)逐步提升大模型在强推理场景 (math, coding) 的 pass@1 能力。

基于Qwen2.5架构,采用DeepSeek-R1-0528生成数据,英伟达推出的OpenReasoning-Nemotron模型,以超强推理能力突破数学、科学、代码任务,在多个基准测试中创下新纪录!数学上,更是超越了o3!
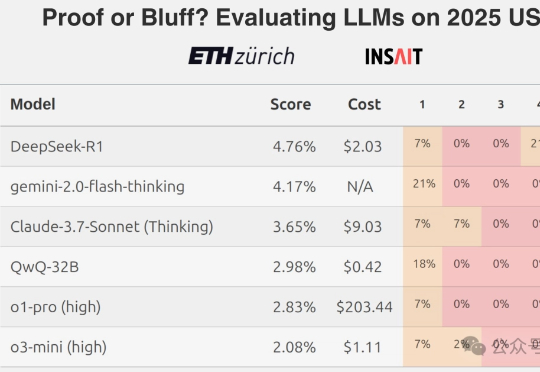
AI做奥数的神话,刚刚被戳破了!最新出炉的2025 IMO数学竞赛中,全球顶尖AI模型无一例外翻车了。即便是冠军Gemini也只拿下可怜的31分,连铜牌都摸不到。Grok-4更是摆烂到底,连DeepSeek-R1都令人失望。看来,AI想挑战人类奥数大神,还为时尚早。
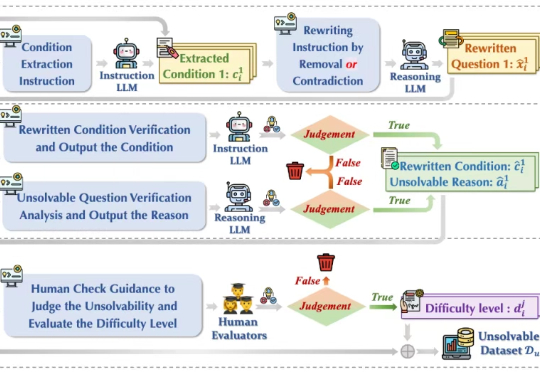
今年初以 DeepSeek-r1 为代表的大模型在推理任务上展现强大的性能,引起广泛的热度。然而在面对一些无法回答或本身无解的问题时,这些模型竟试图去虚构不存在的信息去推理解答,生成了大量的事实错误、无意义思考过程和虚构答案,也被称为模型「幻觉」 问题,如下图(a)所示,造成严重资源浪费且会误导用户,严重损害了模型的可靠性(Reliability)。
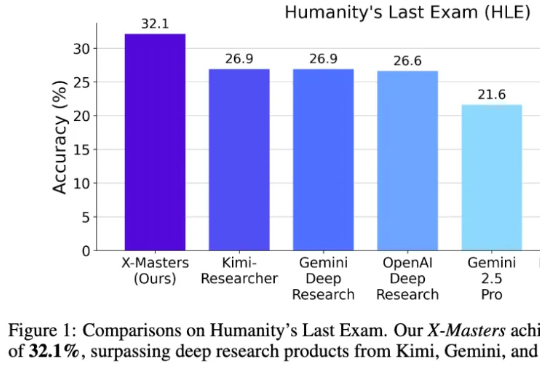
“人类最后的考试”首次突破30分,还是咱国内团队干的! 该测试集是出了名的超难,刚推出时无模型得分能超过10分。
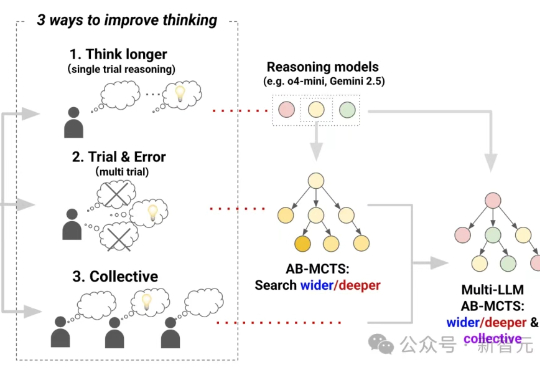
三个前沿AI能融合成AGI吗?Sakana AI提出Multi-LLM AB-MCTS方法,整合o4-mini、Gemini-2.5-Pro与DeepSeek-R1-0528模型,在推理过程中动态协作,通过试错优化生成过程,有效融合群体AI智慧。