别再信“LRM无需优化提示词”了,你至少输掉23%的性能,以R1为例
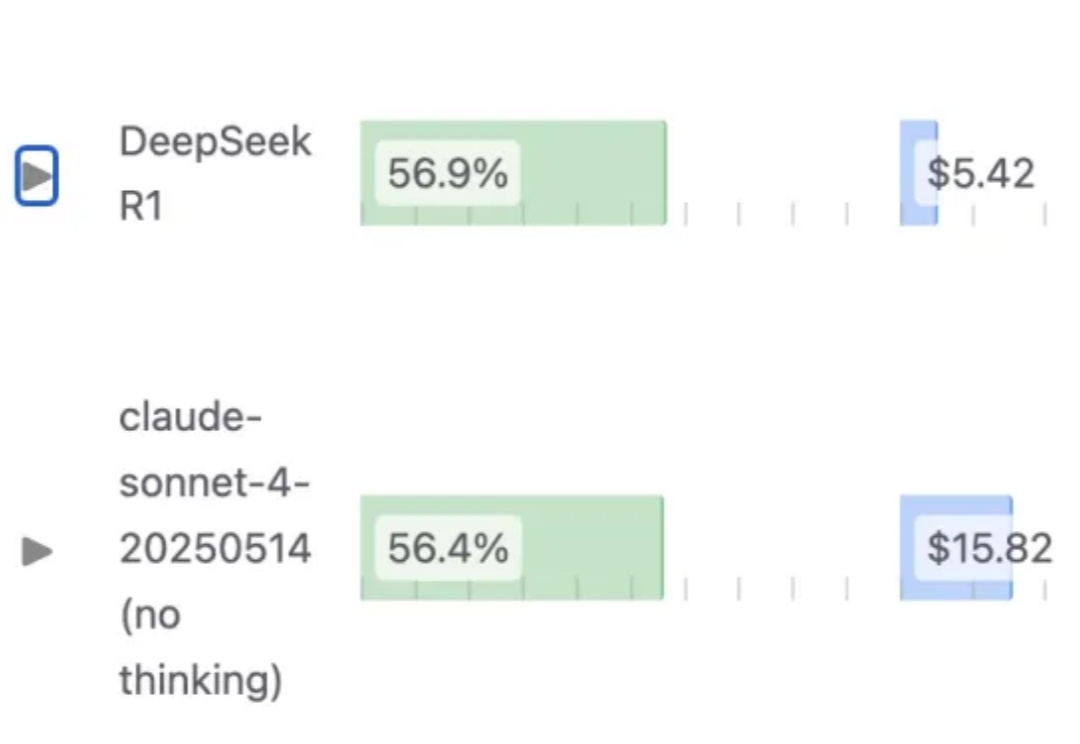
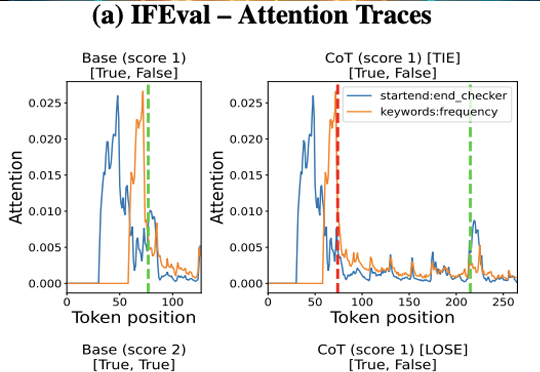
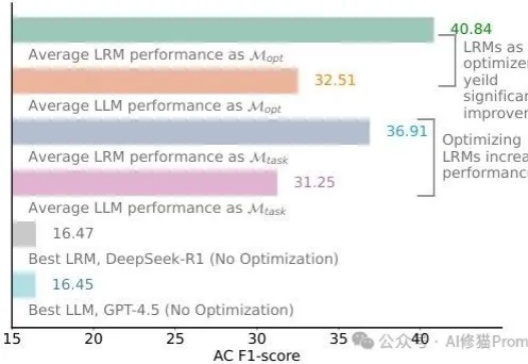
别再信“LRM无需优化提示词”了,你至少输掉23%的性能,以R1为例还记得DeepSeek-R1发布时AI圈的那波狂欢吗?"提示工程已死"、"再也不用费心写复杂提示了"、"推理模型已经聪明到不再需要学习提示词了"......这些观点在社交媒体上刷屏,连不少技术大佬都在转发。再到最近,“提示词写死了”......现实总是来得这么快——乔治梅森大学的研究者们用一个严谨得让人无法反驳的实验,狠狠打了所有人的脸!
来自主题: AI技术研报
9771 点击 2025-06-12 11:59