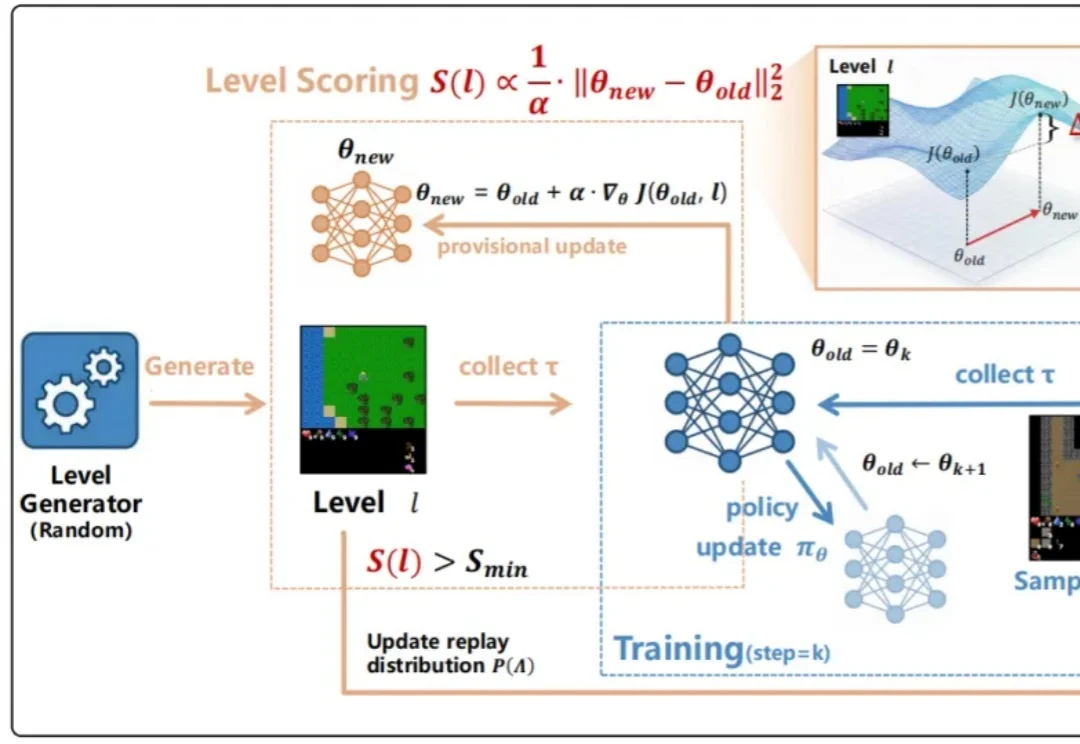
ICML 2026|传统UED瓶颈被打破,强化学习也能精准定位「最近发展区」
ICML 2026|传统UED瓶颈被打破,强化学习也能精准定位「最近发展区」训练强化学习智能体时,一个常见问题是:有些 level 太简单,智能体跑几遍就会;有些 level 又太难,智能体几乎得不到有效反馈。前者只是在重复已有能力,后者则会把训练预算消耗在无效探索上。真正有价值的训练环境,往往位于二者之间。
来自主题: AI技术研报
8962 点击 2026-05-22 08:45
 搜索
搜索
训练强化学习智能体时,一个常见问题是:有些 level 太简单,智能体跑几遍就会;有些 level 又太难,智能体几乎得不到有效反馈。前者只是在重复已有能力,后者则会把训练预算消耗在无效探索上。真正有价值的训练环境,往往位于二者之间。

如果把现在最热门的几条 3D 生成技术线放在一起看,你会发现它们正在遇到一个很像的问题。
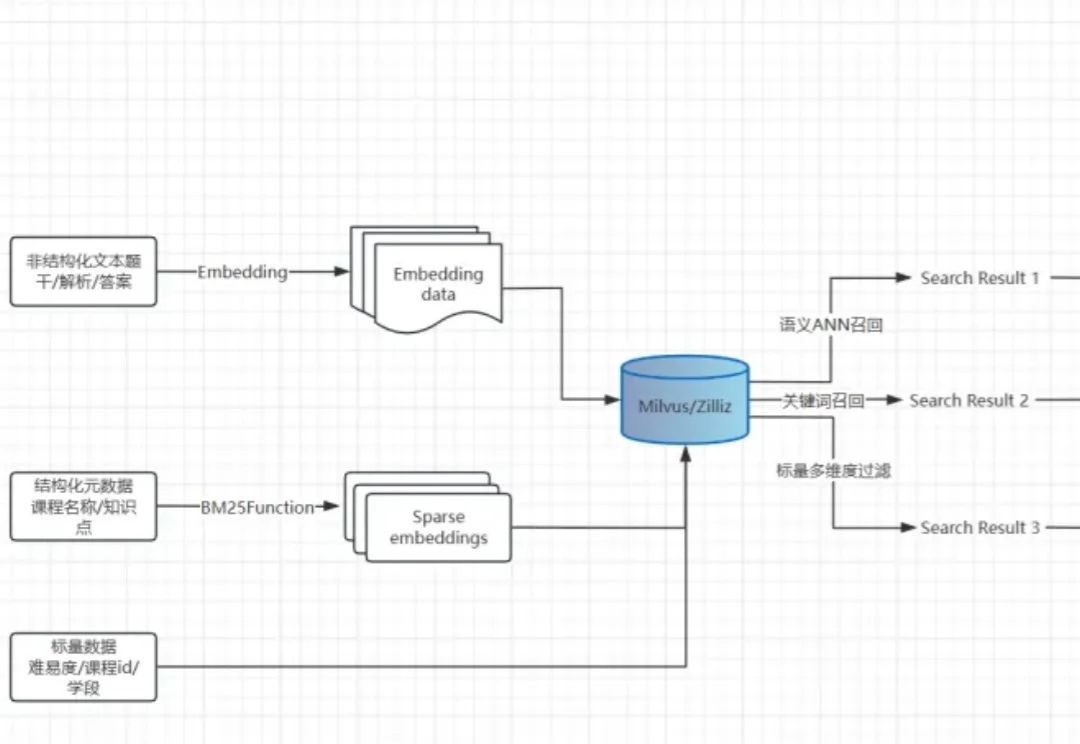
在教育科技领域,题库是核心资产,更是连接学生、教师与知识体系的关键入口。

不出所料,之前爆料的 Gemini Omni 正式发布了。

刚刚 Anthropic 又给他们的官方 Managed Agents 加了俩功能:自托管沙箱 self-hosted sandboxes 和 MCP 隧道 MCP tunnels
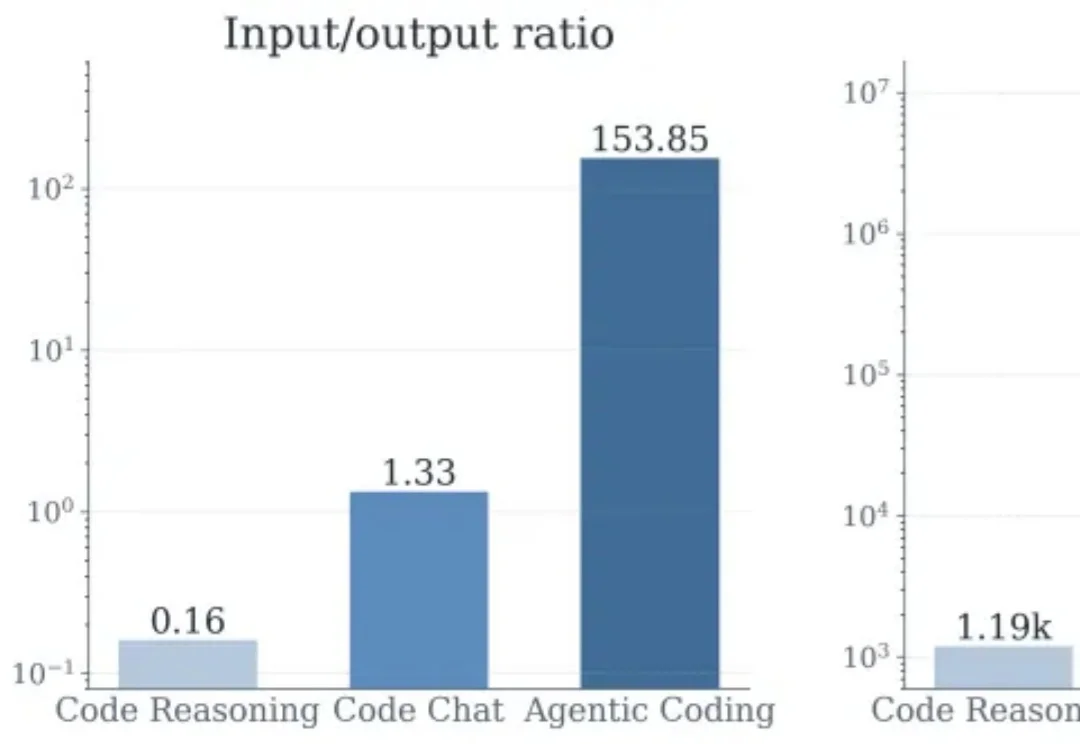
如今的 AI Agent 正在大规模落地,其中应用最广且最受关注的当数 Claude Code,Codex,Cursor 这类 coding agent。过去的一年里,这类 coding agent 产品迭代迅速,在一年内将在 swe-bench- verified 的准确率提高到了 78%+。
TRAE Editor for Unity 是一款专为 TRAE IDE 开发的,并内嵌于 Unity 编辑器的插件。它打通了 TRAE IDE 与 Unity 编辑器之间的协作链路,将 TRAE IDE 的基础功能、AI 辅助编码能力以及对 Unity 项目的深度理解融为一体,让你能够通过 Unity 编辑器直接唤起 TRAE IDE 编写代码,并便捷地回到 Unity 编辑器进行预览与调试。
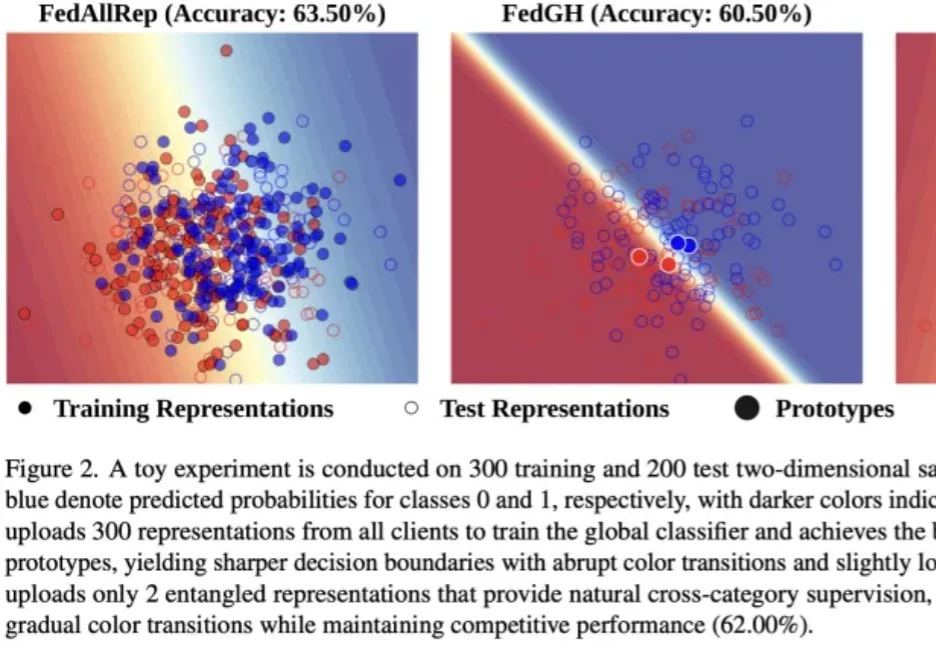
在联邦学习中,如何同时兼顾模型性能、数据隐私和通信开销,是一个亟需解决的挑战。
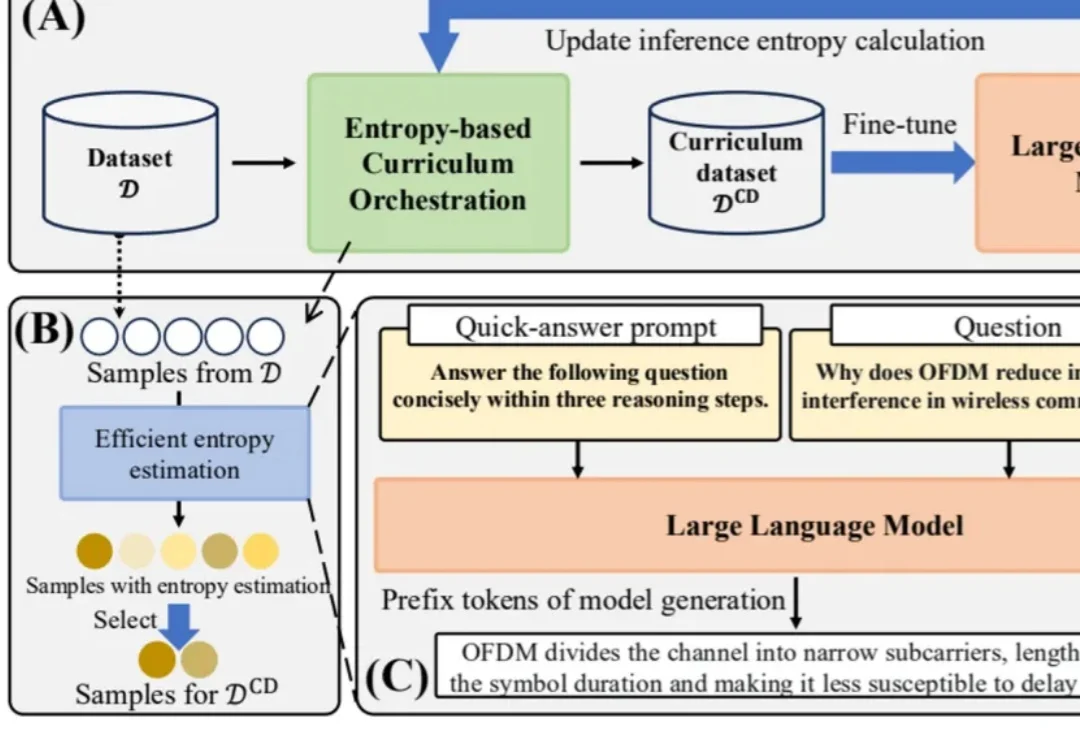
在大模型后训练中,数据不再只是 “越多越好”,而是要像人类学习一样,动态选择最合适难度的样本。华为提出的 EDCO 方法,将样本难度估计与动态课程编排引入领域大模型微调;数月后,由 Rutgers、Amazon、Google 等作者参与的 DARE 论文即引用 EDCO,并将其作为难度感知强化学习训练的重要对比基线。
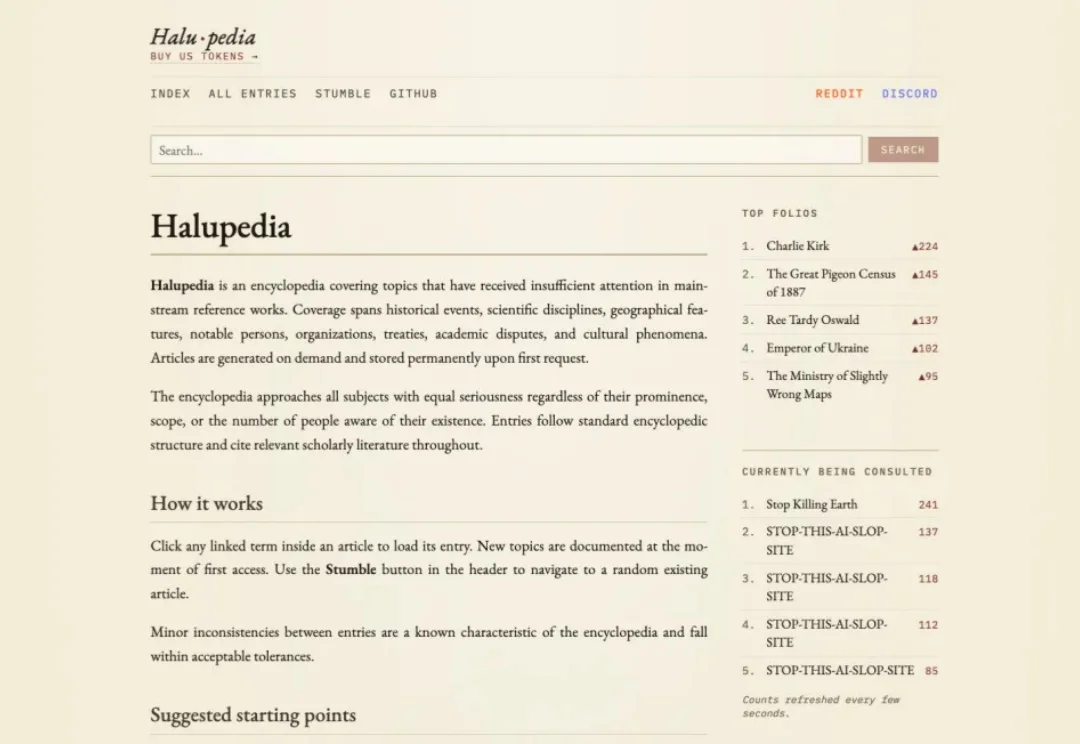
当我们在维基百科搜索一个词条时,你期待的是真相,至少在AI时代,总得有一个地方能(大概率)给我点真东西吧。可以,但在 Halupedia 搜索一个词条时,得到的也是真相——一个三秒钟前刚被发明出来的真相。