# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在教育科技领域,题库是核心资产,更是连接学生、教师与知识体系的关键入口。
而随着题目规模从百万级迈向千万级甚至亿级,传统全文检索在语义理解、精准过滤、相似推荐、高并发稳定上的短板日益突出。
有时甚至会出现题越来越多,搜索质量反而下滑的问题。
本文将分享一套可直接复用、经过生产验证的语义 + 关键词 + 标量过滤三位一体搜题引擎架构,彻底解决传统检索痛点。
在早期的题库系统中,我们主要依赖 Elasticsearch(ES)进行全文检索。虽然 ES 在处理倒排索引和关键词匹配方面表现非常稳定可靠,但在实际业务中学生不会总是输入标准知识点。老师也不是只按关键词找题。
这就导致,如果要找的是同一个知识点下,解法相近但题面不同的题,靠关键词处理,就会面临三大问题:
语义鸿沟:ES 基于词频统计(如 BM25 算法),无法理解"F=ma"与"牛顿第二定律"之间的语义等价性。如果用户搜索"力的公式",而题目中只写了"F=ma",传统搜索引擎往往会漏掉。
专有名词脆弱性:对于特定的课程编号或生僻的知识点名称,一旦用户输入有细微偏差,或者题目表述使用了同义词,检索效果就会大幅下降。
缺乏向量空间:无法支持"以题搜题"或"相似题推荐"等基于语义相似度的高级功能。
为了解决这些问题,我们经历了从多字段合并 HNSW 检索再到多字段混合检索的过渡:
过渡阶段(HNSP ANN 检索):最初,我们尝试将题目内容、知识点、课程名等所有文本信息拼接成一个长字符串,统一进行向量化,然后使用 HNSW 算法进行近似最近邻检索。
这种方式虽然解决了语义问题,但牺牲了精确度。例如,用户想搜"高一数学",向量检索可能会因为"高二数学"在语义上极度相似而将其召回,导致标量过滤失效或权重难以控制。
最终我们选择引入Milvus作为我们的底层检索支撑,并重点使用其混合检索能力,将语义理解交给稠密向量(Dense Vector),将精确过滤交给标量字段(Scalar Field)或关键词检索(Sparse Vector/BM25)。这种双管齐下的策略,既保留了向量检索的泛化能力,又确保了元数据过滤的绝对精准。
接下来的问题,就是怎么基于这一需求,完成整体的技术架构搭建。
我们最终的整体架构设计如下:
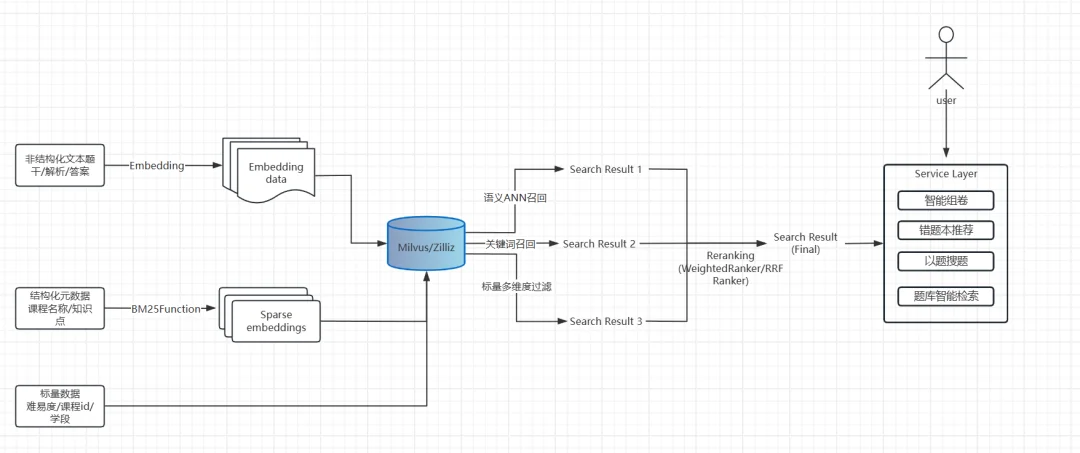
系统从原始题目到智能检索的全链路,一共分为五个环节:
第一步,数据采集与清洗:从多渠道获取非结构化的题目文本(题干、解析)及结构化元数据(课程、学段、题型、知识点、难度),统一字段格式,为混合检索打好基础。
第二步,向量化处理:使用教育领域微调 Embedding 模型将题目文本转化为高维(768/1024 维)稠密向量捕捉深层语义;通过 Milvus 内置 BM25Function 自动生成稀疏向量(支撑关键词精确匹配),无需外部依赖。
第三步,混合索引构建:针对 Milvus 数据库,我们为不同特征的数据建立了多维度索引体系:为题干等长文本构建基于 HNSW 的稠密向量索引(索引 HNSW,度量 COSINE。),为支持 BM25 全文搜索的稀疏向量构建 SPARSE_FLOAT_VECTOR 索引,同时为高频过滤字段建立标量索引,以此实现高效的多路径召回。
第四步,混合检索服务:稠密向量语义召回 + 稀疏向量关键词召回 + 标量精确过滤,通过 Milvus 原生Rerankers 策略对 ANN 搜索结果集进行合并和重新排序,无需应用层复杂逻辑。这里,我们会对学科、学段、知识点、难度建立标量索引,通过 expr 表达式精准剪枝,先过滤后检索,避免无效计算。
第五步,精排与输出:通过 Cross-Encoder 对召回结果重排序,输出最终题目列表,支撑智能组卷、错题本、以题搜题等上层业务。
借助Milvus,我们不仅提升了题库内容的检索效率,也重点将其用在了题库内容去重,以及数据的按需分区分片。
题库大到一定规模后,重复题会变成一个很实际的问题。
同一道题可能来自不同试卷,也可能被不同老师录入过。题面稍微换几个字,传统规则就很难识别。重复题多了,影响的不只是存储成本。搜题时,结果页里连续出现几道几乎一样的题,体验会变差。组卷时,如果系统推荐的都是相似变体,试卷质量会下降。检验学生学习的知识点覆盖情况,重复题会污染统计结果。
针对这个问题,我们采用了教育行业通用、Milvus 官方推荐的两级去重:
离线阶段 ETL 去重,系统对全量题目生成向量,计算相似度。如果两道题相似度很高>0.99 ,并且学科、知识点、题型等元数据一致,就进入合并或剔除流程。
实时写入去重,新题入库前,先在 Milvus 里通过低阈值向量检索 + 元数据校验做一次相似检索,找出可能重复的题,再结合元数据判断是否写入。
这种做法能把重复题挡在入库前,也能定期清理历史数据里的近似题,最终实现了题目去重效率提升50%+,存储成本显著下降。
题库检索还有一个行业特点:流量不均匀。晚上作业时间,搜题请求会集中出现。考试前,练习和组卷请求会上升。寒暑假课程开始后,某些年级和学科会突然变热。
如果系统只在平均流量下表现不错,并不够。与此同时,千万级乃至亿级数据下,单 Collection 检索与维护成本激增。
借助 Milvus,我们可以按学段和学科做数据分区,比如高中数学、初中物理、小学英语。查询时划分为不同Partition,检索时指定 partition_names,可以将搜索范围限定在目标分区,扫描量减少 90%+。
对于更大的数据规模,我们会引入水平分片(Sharding):对超大规模集合启用分片,分散查询压力,支撑高并发访问,适配教育场景高峰期(如作业、考试前)流量突增。
文章来自于"Zilliz",作者 "王海龙"。


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
