魔改RNN挑战Transformer,RWKV上新:推出2种新架构模型
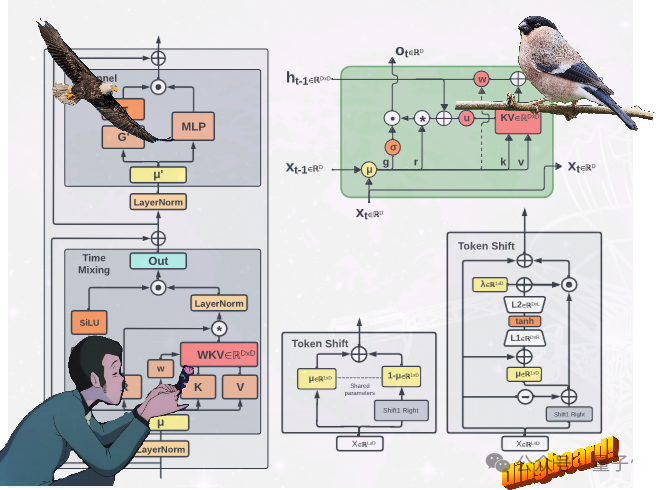
魔改RNN挑战Transformer,RWKV上新:推出2种新架构模型不走Transformer寻常路,魔改RNN的国产新架构RWKV,有了新进展: 提出了两种新的RWKV架构,即Eagle (RWKV-5) 和Finch(RWKV-6)。
来自主题: AI资讯
9559 点击 2024-04-13 18:06
 搜索
搜索
不走Transformer寻常路,魔改RNN的国产新架构RWKV,有了新进展: 提出了两种新的RWKV架构,即Eagle (RWKV-5) 和Finch(RWKV-6)。
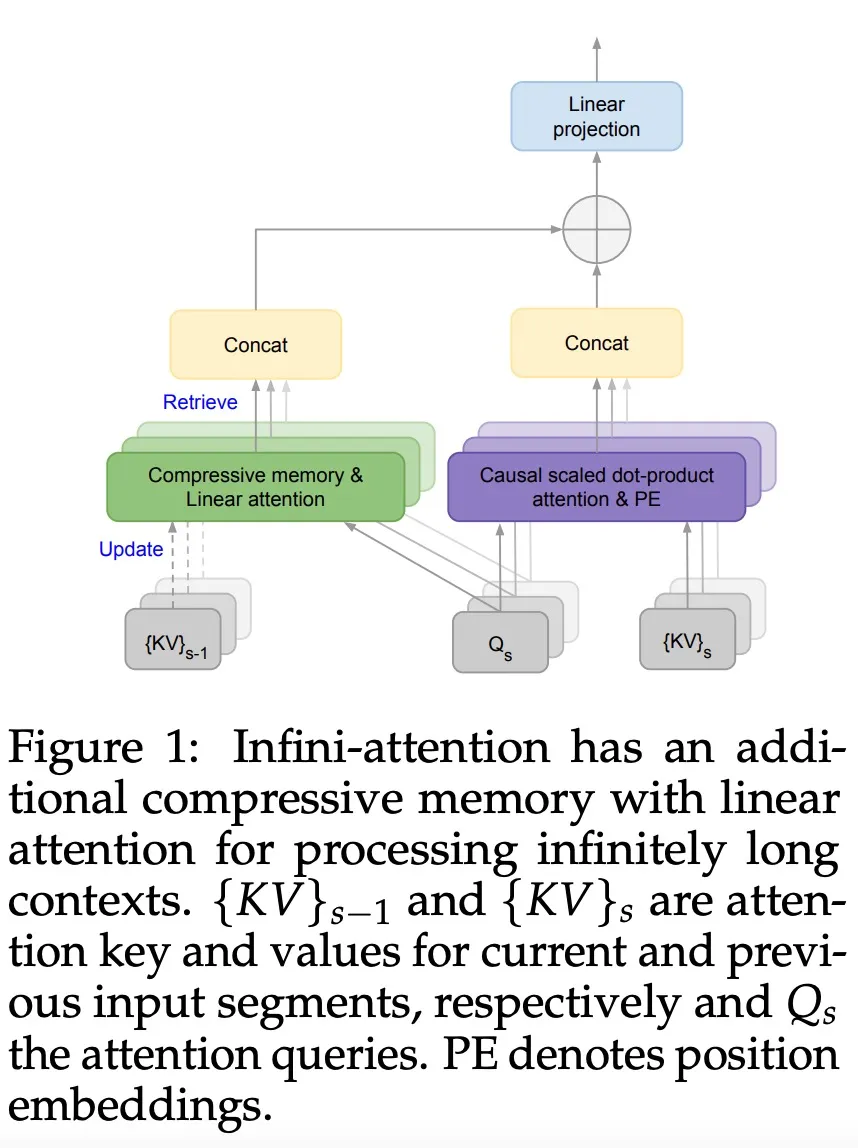
谷歌又放大招了,发布下一代 Transformer 模型 Infini-Transformer。

【新智元导读】大模型落地并不缺场景,却往往因算力不够遇难题。这家国产平台从今日起,免费送百万token。开发者们不仅可以对20多种开源模型精调,还能用上极具性价比的多元算力。

百亿token补贴,4月起免费!这次的羊毛来自清华系AI公司无问芯穹,企业与个人皆可薅~这家公司成立于2023年5月,目标是打造大模型软硬件一体化最佳算力解决方案。

PreFLMR模型是一个通用的预训练多模态知识检索器,可用于搭建多模态RAG应用。模型基于发表于 NeurIPS 2023 的 Fine-grained Late-interaction Multi-modal Retriever (FLMR) 并进行了模型改进和 M2KR 上的大规模预训练。

最近一段时间,AI 与大模型技术突飞猛进。春节刚过,前沿方向上就迎来了新一轮突破。

去年 12 月,新架构 Mamba 引爆了 AI 圈,向屹立不倒的 Transformer 发起了挑战。如今,谷歌 DeepMind「Hawk 」和「Griffin 」的推出为 AI 圈提供了新的选择。
而早在一年前,ChatGPT横空出世,由此我对AI+教育格外感兴趣,我认为ChatGPT的出现会重塑整个教育行业。

检索增强生成(RAG)和微调(Fine-tuning)是提升大语言模型性能的两种常用方法,那么到底哪种方法更好?在建设特定领域的应用时哪种更高效?微软的这篇论文供你选择时进行参考。
进入现今的大模型 (LLM) 时代,又有研究者发现了左右互搏的精妙用法!近日,加利福尼亚大学洛杉矶分校的顾全全团队提出了一种新方法 SPIN(Self-Play Fine-Tuning),可不使用额外微调数据,仅靠自我博弈就能大幅提升 LLM 的能力。