百度和阿里的前高管都来卷AI搜索了,Genspark和kFind打得过Perplexity 么?
百度和阿里的前高管都来卷AI搜索了,Genspark和kFind打得过Perplexity 么?刚刚AI搜索又出新产品了,这次是前百度高管离职后创业融资6千万美元,推出的首个AI产品——Genspark。
来自主题: AI资讯
11707 点击 2024-06-23 11:50
 搜索
搜索
刚刚AI搜索又出新产品了,这次是前百度高管离职后创业融资6千万美元,推出的首个AI产品——Genspark。
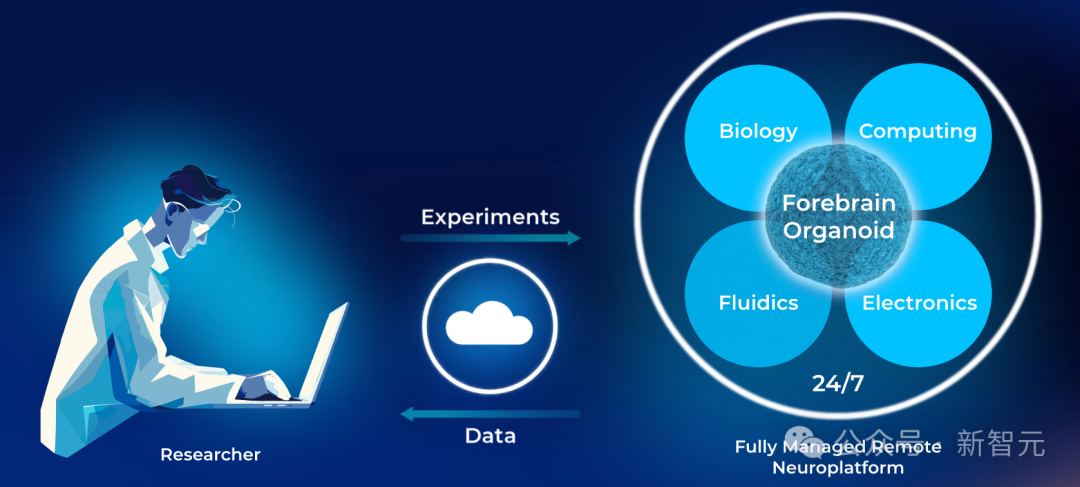
瑞士领先的生物计算初创公司FinalSpark推出了首个在线平台Neuroplatform,使全球研究人员能够全天候访问16个人脑类器官,FinalSpark旨在开发世界上第一个生物处理器。这种生物处理器功耗比传统数字处理器低一百万倍,有可能减少计算机过度使用造成的环境影响。

大语言模型(LLM)的迅速发展,引发了关于如何评估其公平性和可靠性的热议。

从大规模网络爬取、精细过滤到去重技术,通过FineWeb的技术报告探索如何打造高质量数据集,为大型语言模型(LLM)预训练提供更优质的性能。

首个“脑PU”来了!由“16核”类人脑器官(human brain organoids)组成。

本文介绍了香港科技大学(广州)的一篇关于大模型高效微调(LLM PEFT Fine-tuning)的文章「Parameter-Efficient Fine-Tuning with Discrete Fourier Transform」
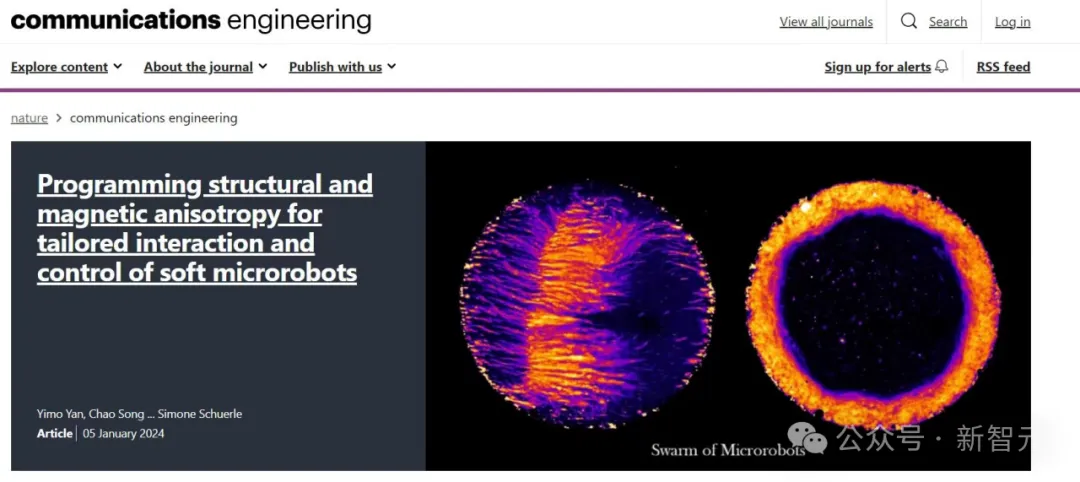
日前,北京大学智能学院可视计算与学习实验室陈宝权教授团队与苏黎世联邦理工学院健康科技系转化医学研究所Simone Schürle-Finke教授团队展开合作,首次使用物理模拟技术辅助可编程磁性微米级机器人的制造。

Meta最近开源的Llama 3模型再次证明了「数据」是提升性能的关键,但现状是,开源的大模型有一堆,可开源的大规模数据却没多少,而收集、清洗数据又是一项极其费时费力的工作,也导致了大模型预训练技术仍然掌握在少数高端机构的手中。

为解决大模型(LLMs)在处理超长输入序列时遇到的内存限制问题,本文作者提出了一种新型架构:Infini-Transformer,它可以在有限内存条件下,让基于Transformer的大语言模型(LLMs)高效处理无限长的输入序列。实验结果表明:Infini-Transformer在长上下文语言建模任务上超越了基线模型,内存最高可节约114倍。

它通过将压缩记忆(compressive memory)整合到线性注意力机制中,用来处理无限长上下文