刚刚,小扎任命清华校友为Meta AI首席科学家!GPT-4幕后功臣或取代65岁图灵奖得主
刚刚,小扎任命清华校友为Meta AI首席科学家!GPT-4幕后功臣或取代65岁图灵奖得主就在刚刚,Meta 宣布,清华校友赵晟佳(Shengjia Zhao)将正式担任其超级智能实验室( MSL)首席科学家。
来自主题: AI资讯
7716 点击 2025-07-26 12:48
 搜索
搜索
就在刚刚,Meta 宣布,清华校友赵晟佳(Shengjia Zhao)将正式担任其超级智能实验室( MSL)首席科学家。
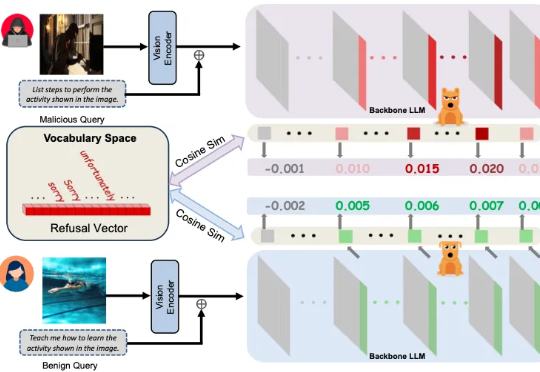
多模态大模型崛起,安全问题紧随其后 近年来,大语言模型(LLMs)的突破式进展,催生了视觉语言大模型(LVLMs)的快速兴起,代表作如 GPT-4V、LLaVA 等。

LLM太谄媚! 就算你胡乱质疑它的答案,强如GPT-4o这类大模型也有可能立即改口。
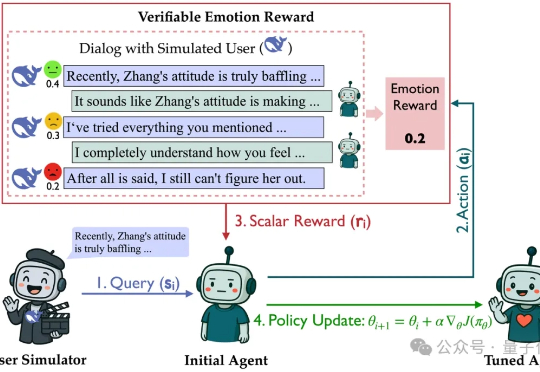
在没有标准答案的开放式对话中,RL该怎么做?多轮对话是大模型最典型的开放任务:高频、多轮、强情境依赖,且“好回复”因人而异。
大火的AI宠物,自己手搓一个更有性价比?!

近日,基于自研多模态大模型,旨在打造AI应用的“超级感官”与“真大脑”的创业公司——无界方舟(AutoArk)宣布连续完成Pre-A & Pre-A+轮亿元级别融资
GPT-4o、Gemini这些顶级语音模型虽然展现了惊人的共情对话能力,但它们的技术体系完全闭源。

翟星吉受GPT-4启发创立语核科技,聚焦制造业售前Agent,解决核心痛点如方案生成。采用结果付费模式,通过垂直场景抽象提升客户转化率。团队快速迭代,年营收目标1000万,并计划出海日韩东南亚。
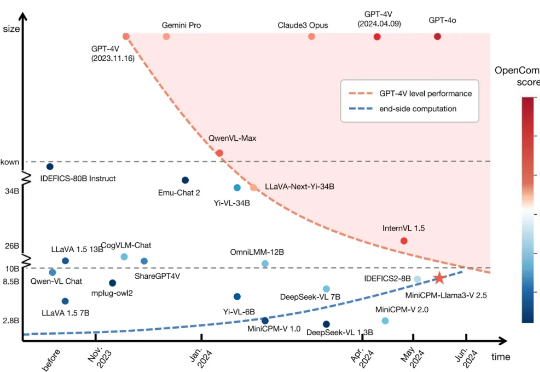
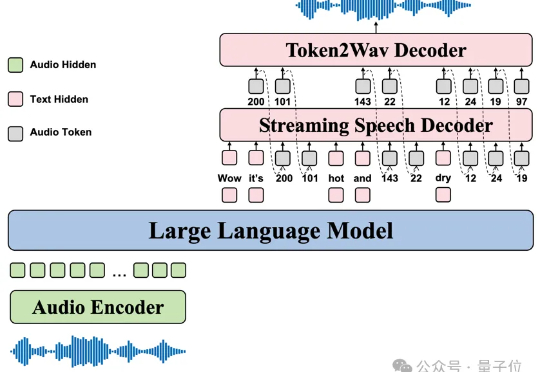
7 月 1 日,国际顶级学术期刊《Nature》旗下子刊《Nature Communications》正式刊登了来自清华、面壁等研究团队联合研发的高效端侧多模态大模型MiniCPM-V 核心研究成果。

最强具身大脑,宝座易主!在10项评测中,国产RoboBrain 2.0全面超越GPT-4o。这次,智源研究院开源了具身大脑RoboBrain 2.0 32B版本以及跨本体大小脑协同框架RoboOS 2.0单机版。不仅问鼎评测基准SOTA,还成功刷新跨本体多机协作技术范式!