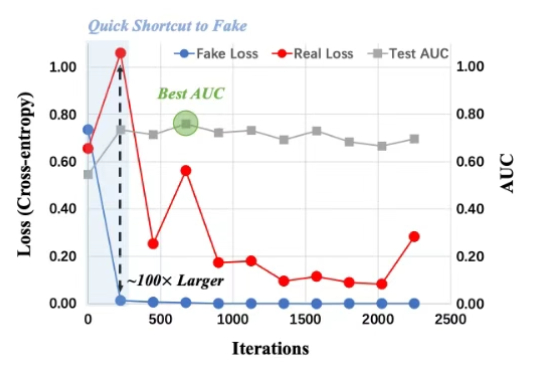
ICML 2025 Oral!北大和腾讯优图破解AI生成图像检测泛化难题:正交子空间分解
ICML 2025 Oral!北大和腾讯优图破解AI生成图像检测泛化难题:正交子空间分解随着 OpenAI 推出 GPT-4o 的图像生成功能,AI 生图能力被拉上了一个新的高度,但你有没有想过,这光鲜亮丽的背后也隐藏着严峻的安全挑战:如何区分生成图像和真实图像?
来自主题: AI技术研报
7673 点击 2025-07-13 11:30
 搜索
搜索
随着 OpenAI 推出 GPT-4o 的图像生成功能,AI 生图能力被拉上了一个新的高度,但你有没有想过,这光鲜亮丽的背后也隐藏着严峻的安全挑战:如何区分生成图像和真实图像?

GPT-4o引爆全球「吉卜力风格」风潮后,其核心成员——华南理工学霸Lu Liu与伯克利博士Allan Jabri——双双跳槽Meta,两人曾在OpenAI主导多模态AI研究,与奥特曼同台展示关键功能。此次挖角再次凸显OpenAI内部动荡后的人才流失危机。

自适应语言模型框架SEAL,让大模型通过生成自己的微调数据和更新指令来适应新任务。SEAL在少样本学习和知识整合任务上表现优异,显著提升了模型的适应性和性能,为大模型的自主学习和优化提供了新的思路。
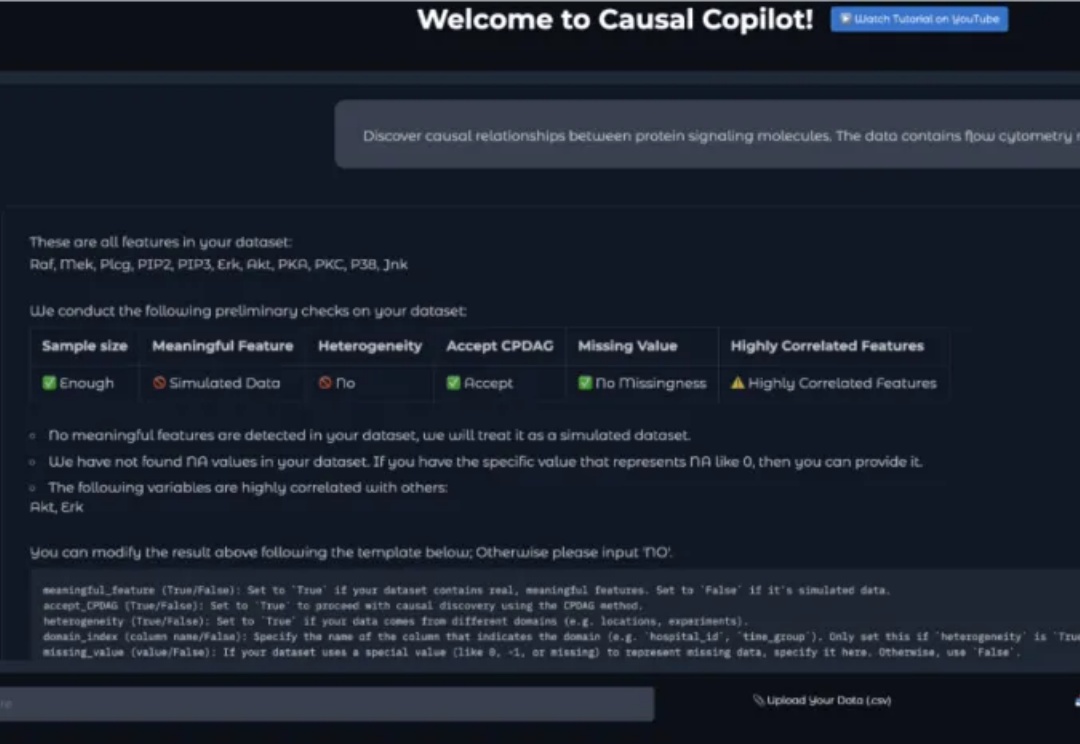
想象这样一个场景:你是一位生物学家,手握基因表达数据,直觉告诉你某些基因之间存在调控关系,但如何科学地验证这种关系?你听说过 "因果发现" 这个词,但对于具体算法如 PC、GES 就连名字都非常陌生。

谁会第一个到达ASI?SemiAnalysis大佬Dylan Patel脱口而出:OpenAI!最近,这位圈内最懂AI和芯片的大佬,毫不留情地戳穿了GPT-4.5惨败的原因,还揭露了Meta仓促模仿DeepSeek结果大翻车的内幕。

图像模型开源还得是FLUX!Black Forest Labs刚刚宣布开源旗舰图像模型FLUX.1 Kontext[dev],专为图像编辑打造,还能直接在消费级芯片上运行。
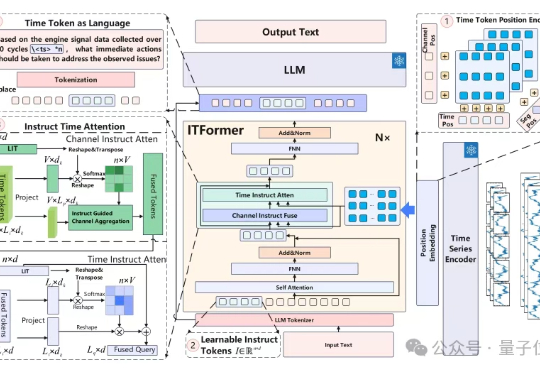
时序数据分析在工业监控、医疗诊断等领域至关重要。比如航空发动机监控这个复杂工业场景中,工程师需分析海量多通道传感器数据,以判断设备状态并制定维护决策。
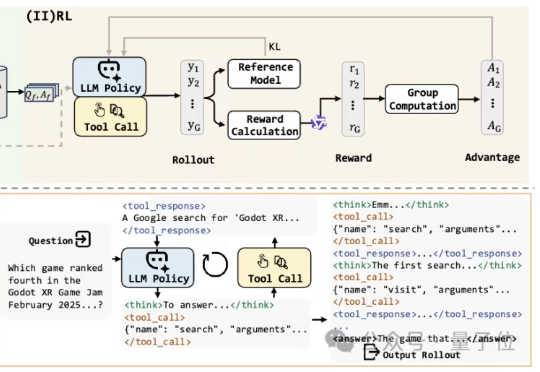
Agent能“看懂网页”,像人类一样上网?阿里发布WebDancer,就像它的名字一样,为“网络舞台”而生。
![Black Forest震撼开源FLUX.1 Kontext [dev]:媲美GPT-4o的图像编辑](https://www.aitntnews.com/pictures/2025/6/27/49d75709-5310-11f0-82be-fa163e47d677.jpg)
前段时间,沉寂了很久的Flux官方团队Black Forest Labs发布了新模型:FLUX.1 Kontext,这是一套支持生成与编辑图像的流匹配(flow matching)模型。FLUX.1 Kontext不仅支持文生图,还实现了上下文图像生成功能,可以同时使用文本和图像作为提示词,并能无缝提取修改视觉元素,生成全新且协调一致的画面。
总是“死记硬背”“知其然不知其所以然”?