GPU训Llama 3.1疯狂崩溃,竟有大厂用CPU服务器跑千亿参数大模型?
GPU训Llama 3.1疯狂崩溃,竟有大厂用CPU服务器跑千亿参数大模型?是时候用CPU通用服务器跑千亿参数大模型了!
来自主题: AI资讯
9197 点击 2024-08-01 16:19
 搜索
搜索
是时候用CPU通用服务器跑千亿参数大模型了!

千亿参数规模的大模型推理,服务器仅用4颗CPU就能实现!

埃隆·马斯克掌控的那几家公司——包括SpaceX、特斯拉、xAI乃至X(原Twitter)——都需要大量的GPU,而且也都是为自己的特定AI或者高性能计算(HPC)项目服务。

苹果AI首登iPhone!47页论文曝自研模型,多项测评超GPT-4。
了解以色列的读者应该知道,以色列只是一个面积仅为重庆三分之一,人口不到1000万的“弹丸小国”。以色列没石油、没淡水,资源贫瘠到除了沙子一无所有,并且常年来战争不断。
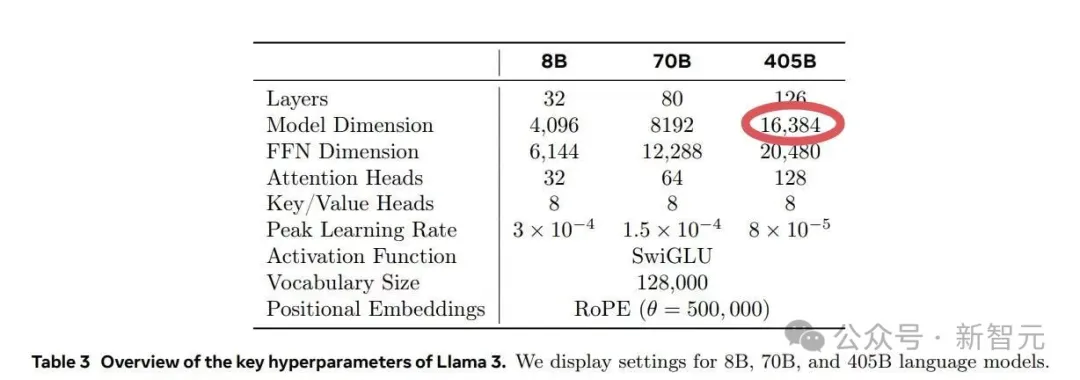
在Meta的Llama 3.1训练过程中,其运行的1.6万个GPU训练集群每3小时就会出现一次故障,意外故障中的半数都是由英伟达H100 GPU和HBM3内存故障造成的。

一半以上的故障都归因于 GPU 及其高带宽内存。

英特尔用“光”,突破了大模型时代棘手的算力难题—— 推出业界首款全集成OCI(光学计算互连)芯片。
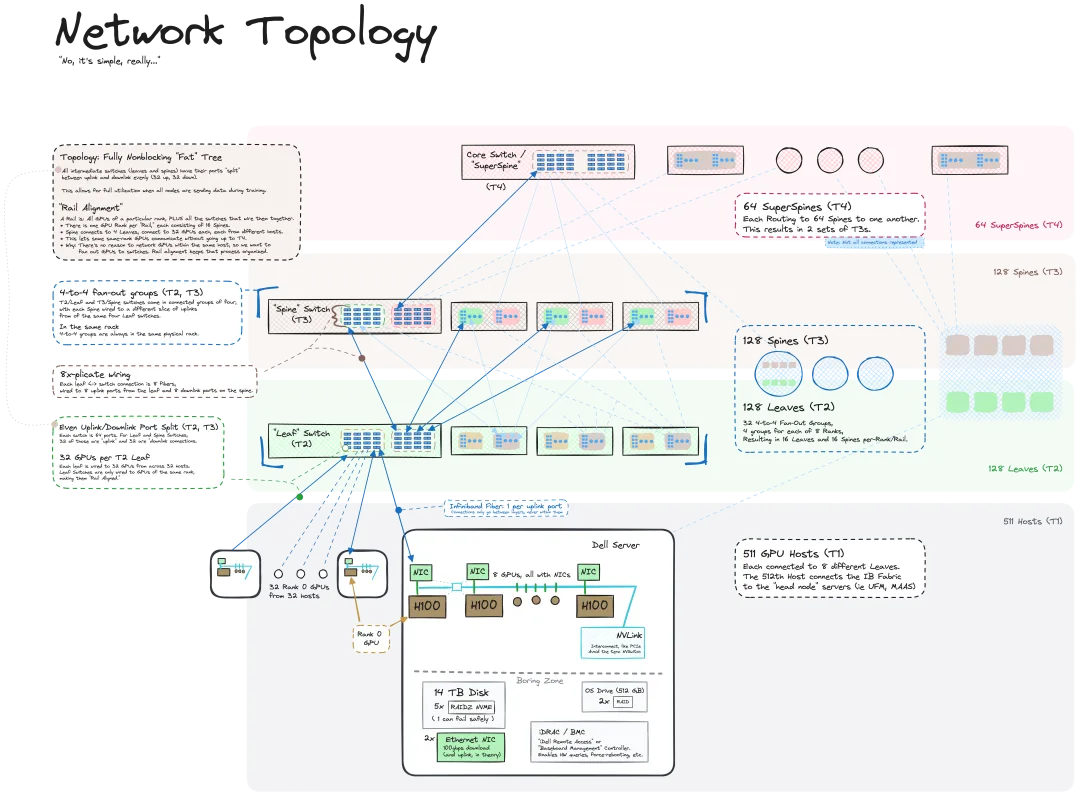
我们知道 LLM 是在大规模计算机集群上使用海量数据训练得到的,机器之心曾介绍过不少用于辅助和改进 LLM 训练流程的方法和技术。而今天,我们要分享的是一篇深入技术底层的文章,介绍如何将一堆连操作系统也没有的「裸机」变成用于训练 LLM 的计算机集群。

英伟达全面转向开源GPU内核模块,历史将再次见证Linux社区开源的力量。