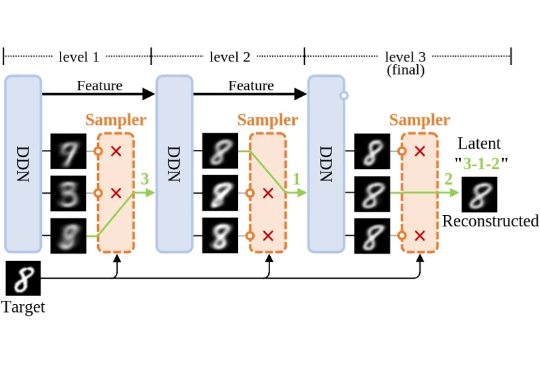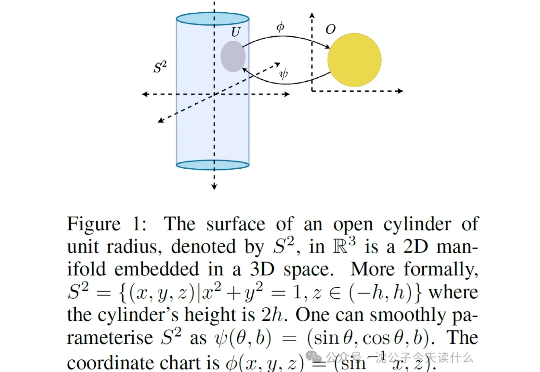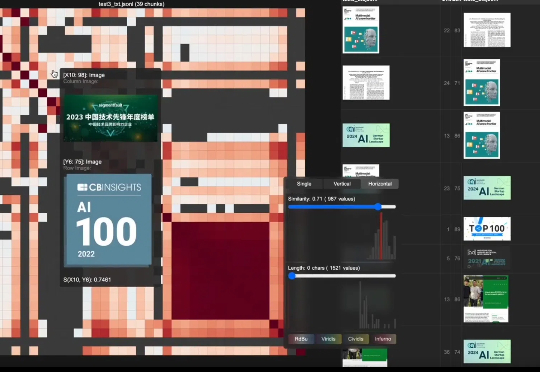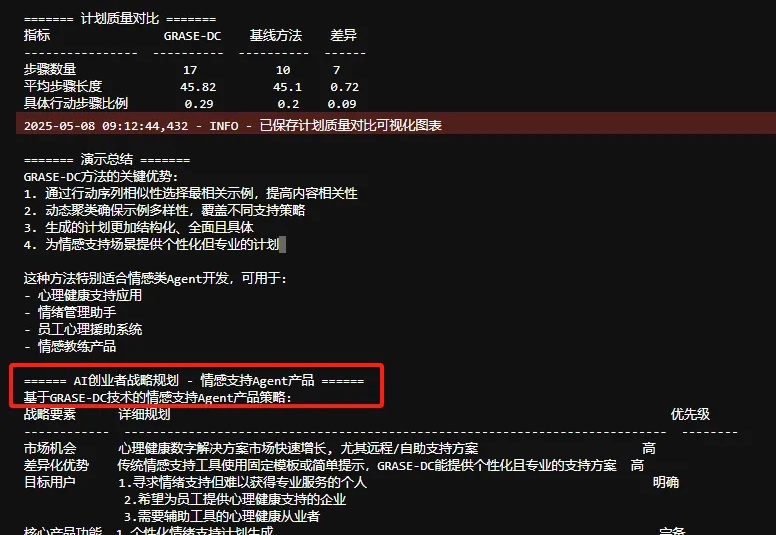
Mamba-3惊现AI顶会ICLR 2026!CMU知名华人教授一作首代工作AI圈爆红
Mamba-3惊现AI顶会ICLR 2026!CMU知名华人教授一作首代工作AI圈爆红曼巴回来了!Transformer框架最有力挑战者之一Mamba的最新进化版本Mamba-3来了,已进入ICLR 2026盲审环节,超长文本处理和低延时是其相对Transformer的显著优势。另一个挑战者是FBAM,从不同的角度探索Transformer的下一代框架。
来自主题: AI资讯
10299 点击 2025-10-13 14:34