

这一次,谷歌Veo 3.1教Sora做视频!角色0变形,4K竖屏直接满分
这一次,谷歌Veo 3.1教Sora做视频!角色0变形,4K竖屏直接满分今天,谷歌Veo 3.1终于迎来重磅升级,表现力直接爆表! 这一次,谷歌特别优化了移动端体验。只需上传一些「素材图片」(ingredient images),就能轻松创作出更有趣、更有创意、画质极佳的视频。
来自主题: AI技术研报
7470 点击 2026-01-14 17:07
今天,谷歌Veo 3.1终于迎来重磅升级,表现力直接爆表! 这一次,谷歌特别优化了移动端体验。只需上传一些「素材图片」(ingredient images),就能轻松创作出更有趣、更有创意、画质极佳的视频。
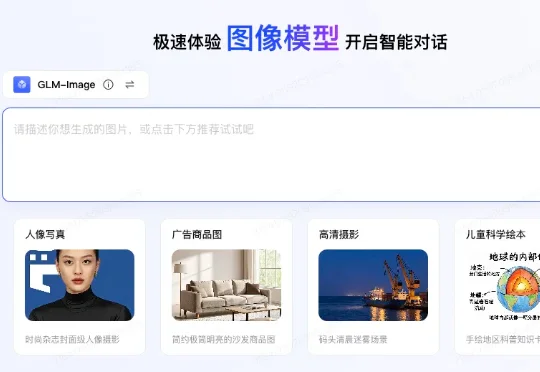
今天,首个在国产芯片上完成全程训练的SOTA(最佳水平)多模态模型开源。这是智谱联合华为开源的图像生成模型GLM-Image。从数据到训练的全流程,该模型完全基于昇腾Atlas 800T A2设备和昇思MindSpore AI框架完成构建。
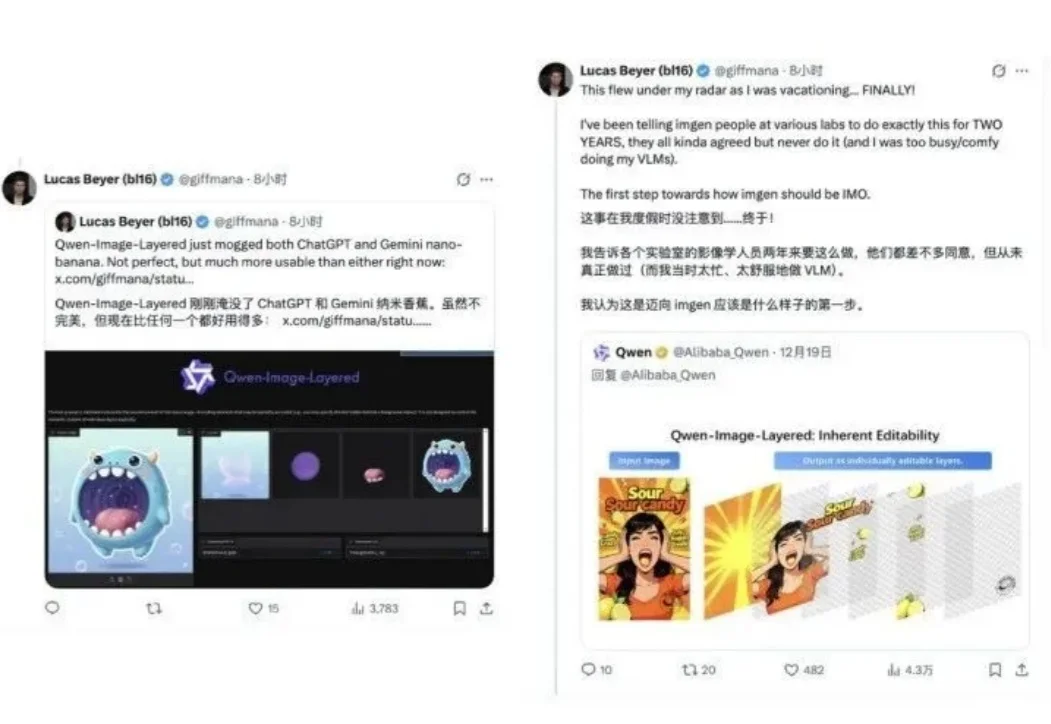
太香了太香了,妥妥完爆ChatGPT和Nano Banana!
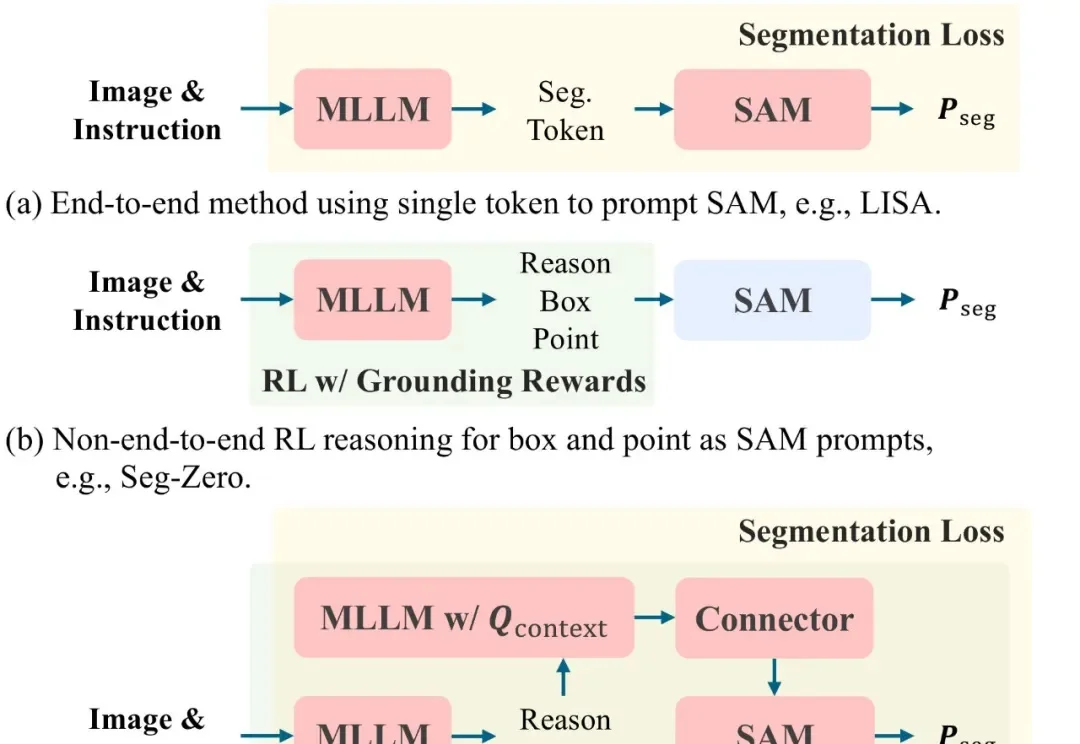
文本提示图像分割(Text-prompted image segmentation)是实现精细化视觉理解的关键技术,在人机交互、具身智能及机器人等前沿领域具有重大的战略意义。这项技术使机器能够根据自然语言指令,在复杂的视觉场景中定位并分割出任意目标。

热门LoRA首次内置,控光换镜头实测可用。

在迈向通用人工智能的道路上,我们一直在思考一个问题:现有的 Image Editing Agent,真的「懂」修图吗?

抽奖式的生图体验,确实让很多设计师在尝鲜之后又默默打开了 Photoshop。于是乎,阿里千问团队再次出手,开源了一个叫 Qwen-Image-Layered 的模型,试图从底层逻辑上解决这个问题。
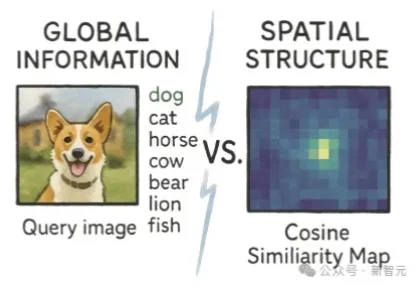
学霸的谎言被揭穿!一篇来自Adobe Research的论文发现,高语义理解并不会提升生成质量,反而可能破坏空间结构。用iREPA简单修改,削弱全局干扰,生成质量立即飙升 。
在文生图(Text-to-Image)和视频生成领域,以FLUX.1、Emu3为代表的扩散模型与自回归模型已经能生成极其逼真的画面。

尽管扩散模型在单图像生成上已经日渐成熟,但当任务升级为高度定制化的多实例图像生成(Multi-Instance Image Generation, MIG)时,挑战随之显现: