
实战:手把手教你Prompt到底该怎么写
实战:手把手教你Prompt到底该怎么写新加坡举办了首届GPT-4提示工程竞赛,Sheila Teo取得了冠军,我们来学习借鉴她采用的三项提示技巧: 使用CO-STAR框架构建提示词 2.使用分隔符将提示词分段 3.使用LLM系统提示
来自主题: AI技术研报
9731 点击 2024-08-06 14:47
 搜索
搜索
新加坡举办了首届GPT-4提示工程竞赛,Sheila Teo取得了冠军,我们来学习借鉴她采用的三项提示技巧: 使用CO-STAR框架构建提示词 2.使用分隔符将提示词分段 3.使用LLM系统提示

从前两年的百模大战到大语言模型 LLM(Large Language Model)的逐步落地应用,端侧AI始终是人工智能技术发展中至关重要的一环。 所谓的端侧AI,即用户在使用过程中不依赖云服务器,直接在终端设备本地使用AI服务。相比于ChatGPT4.0和最新推出的Llama3.1等依赖于云端接口的主流大语言模型,设备端边缘应用的紧凑模型有较强的私密性,也具有个性化操作和节省成本等诸多优势。
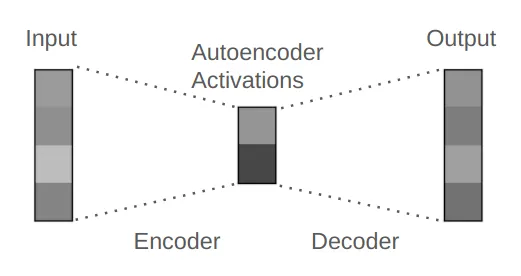
简而言之:矩阵 → ReLU 激活 → 矩阵
为了对齐 LLM,各路研究者妙招连连。
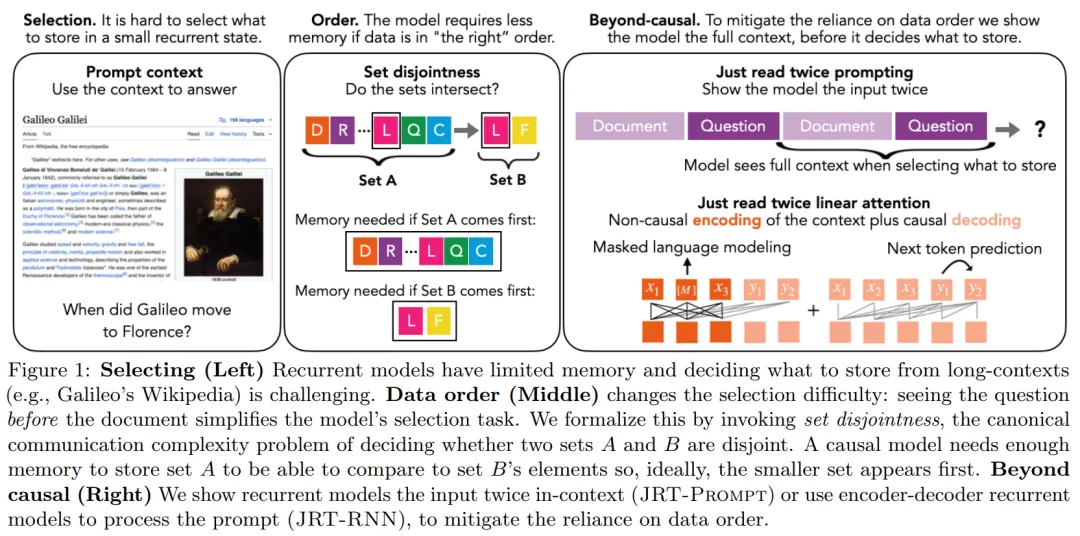
在当前 AI 领域,大语言模型采用的主流架构是 Transformer。不过,随着 RWKV、Mamba 等架构的陆续问世,出现了一个很明显的趋势:在语言建模困惑度方面与 Transformer 较量的循环大语言模型正在快速进入人们的视线。

大模型展现出了卓越的指令跟从和任务泛化的能力,这种独特的能力源自 LLMs 在训练中使用了指令跟随数据以及人类反馈强化学习(RLHF)。

大语言模型 (LLM) 是如何解数学题的?是通过模板记忆,还是真的学会了推理思维?
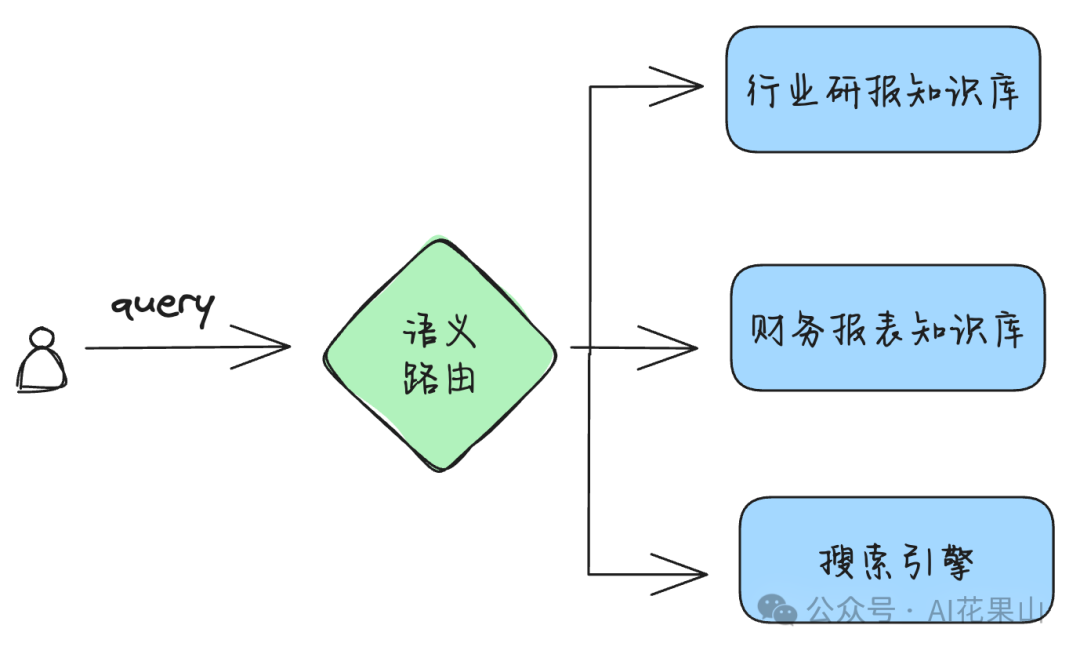
在这篇文章中,笔者将讨论以下几个问题: • 什么是语义路由 • RAG 路由的不同场景
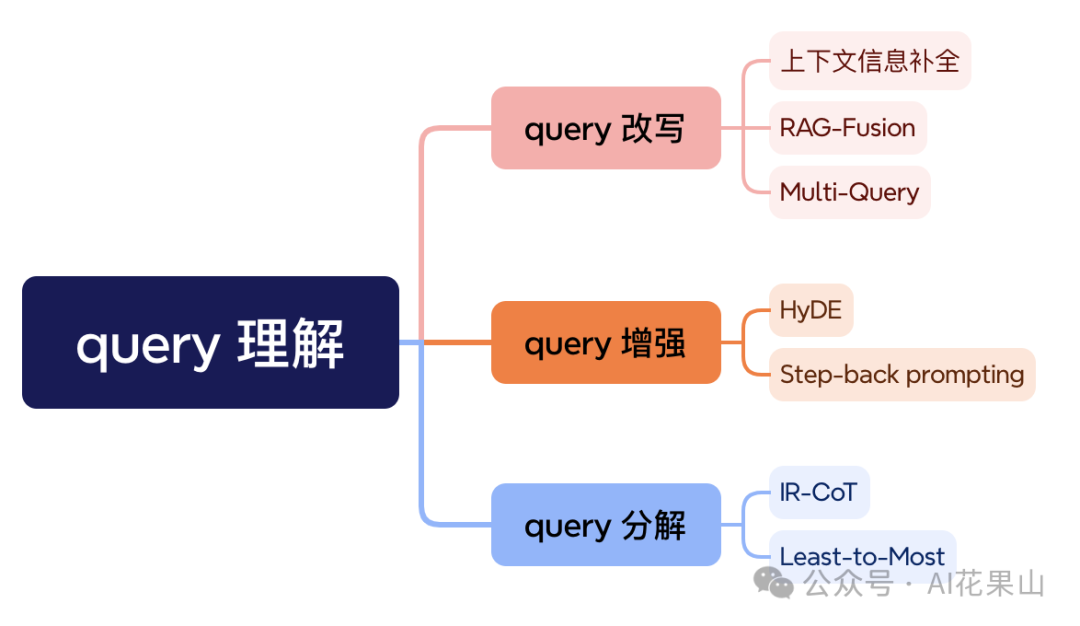
在这篇文章中,笔者将讨论以下几个问题: • 为什么要进行 query 理解 • query 理解有哪些技术(从 RAG 角度) • 各种 query 理解技术的实现(基于 LangChain)
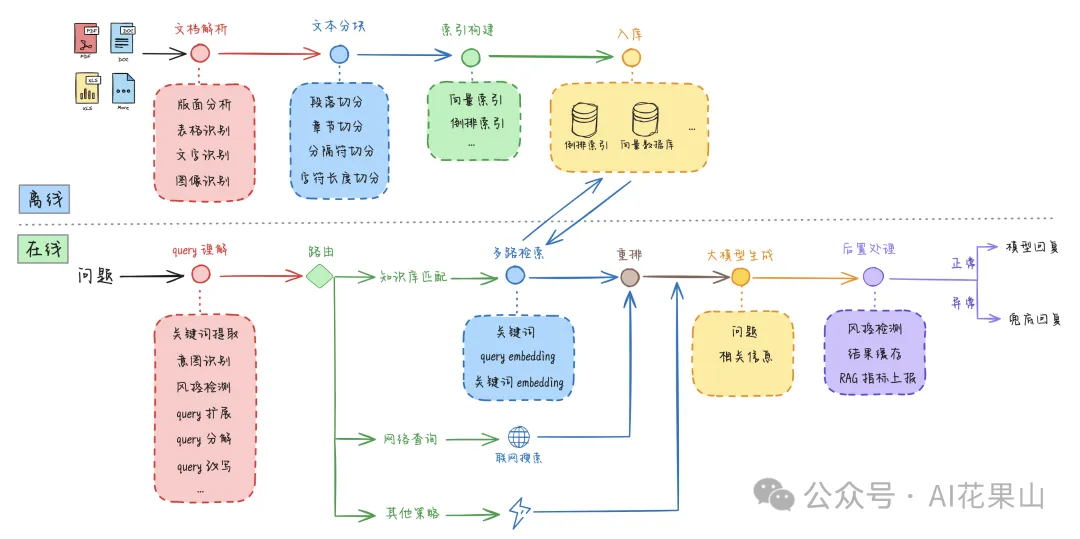
『RAG 高效应用指南』系列将就如何提高 RAG 系统性能进行深入探讨,提供一系列具体的方法和建议。同时读者也需要记住,提高 RAG 系统性能是一个持续的过程,需要不断地评估、优化和迭代。