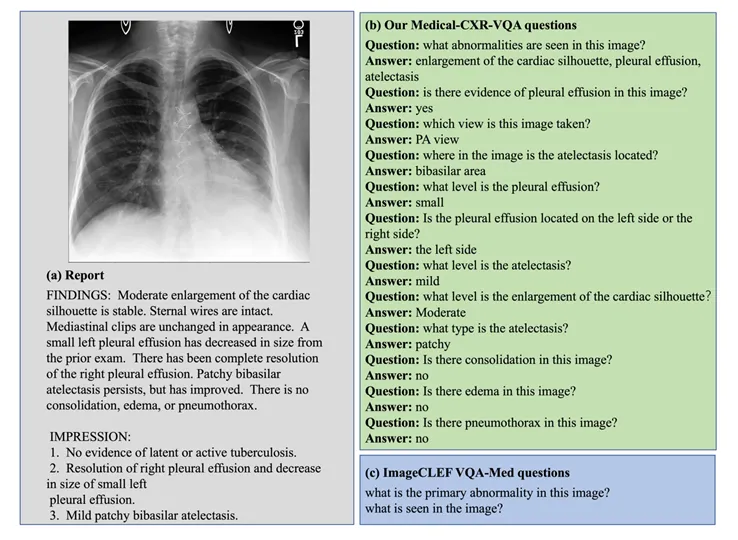
21.5万张X光,78万个问题!德州大学NIH等联合发布医学视觉问答数据集Medical-CXR-VQA
21.5万张X光,78万个问题!德州大学NIH等联合发布医学视觉问答数据集Medical-CXR-VQA多模态大语言模型 (Multimodal Large Language Moodel, MLLM) 以其强大的语言理解能力和生成能力,在各个领域取得了巨大成功。
来自主题: AI资讯
8228 点击 2024-08-10 12:03
 搜索
搜索
多模态大语言模型 (Multimodal Large Language Moodel, MLLM) 以其强大的语言理解能力和生成能力,在各个领域取得了巨大成功。

LLM数学水平不及小学生怎么办?CMU清华团队提出了Lean-STaR训练框架,在语言模型进行推理的每一步中都植入CoT,提升了模型的定理证明能力,成为miniF2F上的新SOTA。

RLHF到底是不是强化学习?最近,AI大佬圈因为这个讨论炸锅了。和LeCun同为质疑派的Karpathy表示:比起那种让AlphaGo在围棋中击败人类的强化学习,RLHF还差得远呢。
前段时间冲上热搜的问题「9.11比9.9大吗?」,让几乎所有LLM集体翻车。看似热度已过,但AI界大佬Andrej Karpathy却从中看出了当前大模型技术的本质缺陷,以及未来的潜在改进方向。

吴恩达教授开新课了,还是亲自授课!

LLM的数学推理能力缺陷得到了很多研究的关注,但最近浙大、中科院等机构的学者们提出,先进模型在视觉推理方面同样不足。为此他们提出了一种多模态的视觉推理基准,并设计了一种新颖的数据合成方法。

数以亿计的人体验过ChatGPT,但许多人尝试过后便未再回头。每家大型企业也都曾尝试过相关试点项目,但真正投入应用的却寥寥无几。这其中部分原因可能只是时间问题。然而,大型语言模型(LLMs)可能也存在陷阱:它们看似是产品,给人以神奇之感,但实际上并非如此。或许,我们终究需要经历寻找产品与市场契合点的漫长而单调的探索过程。

打造终身学习智能体,是研究界以来一直追求的目标。最近,帝国理工联手谷歌DeepMind打造了创新联合框架扩散增强智能体(DAAG),利用LLM+VLM+DM三大模型,让AI完成迁移学习、高效探索。
随着大型语言模型(LLM)技术日渐成熟,各行各业加快了 LLM 应用落地的步伐。为了改进 LLM 的实际应用效果,业界做出了诸多努力。

地球是平的吗? 当然不是。自古希腊数学家毕达哥拉斯首次提出地圆说以来,现代科学技术已经证明了地球是圆形这一事实。 但是,你有没有想过,如果 AI 被误导性信息 “忽悠” 了,会发生什么? 来自清华、上海交大、斯坦福和南洋理工的研究人员在最新的论文中深入探索 LLMs 在虚假信息干扰情况下的表现,他们发现大语言模型在误导信息反复劝说下,非常自信地做出「地球是平的」这一判断。