# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当前主流的视觉语言模型(VLM)主要基于大语言模型(LLM)进一步微调。因此需要通过各种方式将图像映射到 LLM 的嵌入空间,然后使用自回归方式根据图像 token 预测答案。
在这个过程中,模态的对齐是通过文本 token 隐式实现的,如何做好这一步的对齐非常关键。
针对这一问题,武汉大学、字节跳动豆包大模型团队和中国科学院大学的研究人员提出了一种基于对比学习的文本 token 筛选方法(CAL),从文本中筛选出与图像高度相关的 token,并加大其损失函数权重,从而实现更精准的多模态对齐。

CAL 有以下几个亮点:
研究动机
目前视觉语言模型依赖于图片模态的对齐,如何做好对齐非常关键。目前主流的方法是通过文本自回归的方式进行隐式对齐,但是每个文本 token 对图像对齐的贡献是不一致的,对这些文本 token 进行区分是非常有必要的。
CAL 提出,在现有的视觉语言模型(VLM)训练数据中,文本 token 可以被分为三类:

图一:绿色标记为与图片高度相关 token,红色为内容相悖,无色为中性 token
在训练过程中,后两类 token 整体而言实际上占据了较大比例,但由于它们并不强依赖于图片,对图片的模态对齐作用不大。因此,为了实现更好的对齐,需要加大第一类文本 token,即与图片高度相关部分 token 的权重。如何找出这一部分 token 成为了解决这个问题的关键所在。
方法
找出与图片高度相关 token 这个问题可以通过 condition contrastive 的方式来解决。
具体来说,在训练过程中,CAL 将图文序列和单独的文本序列分别输入到大语言模型(LLM)中,得到每个文本 token 的 logit。通过计算这两种情况下的 logit 差值,可以衡量图片对每个 token 的影响程度。logit 差值越大,说明图片对该 token 的影响越大,因此该 token 与图像越相关。下图展示了文本 token 的 logit diff 和 CAL 方法的流程图。
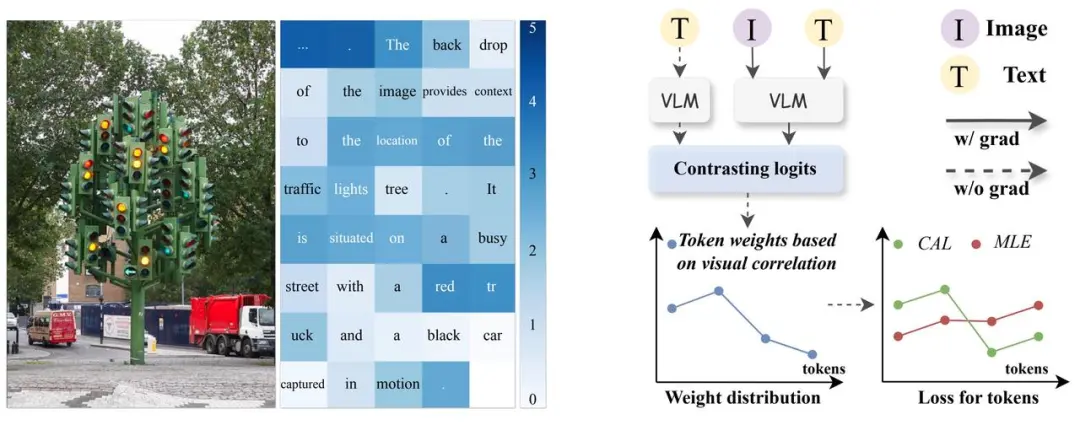
图二:左图是对两种情形下 token logit diff 的可视化,右图是 CAL 方法流程的可视化
实验
CAL 在 LLaVA 和 MGM 两个主流模型上进行了实验验证,在不同规模的模型下均实现了性能提升。
包含以下四个部分的验证:
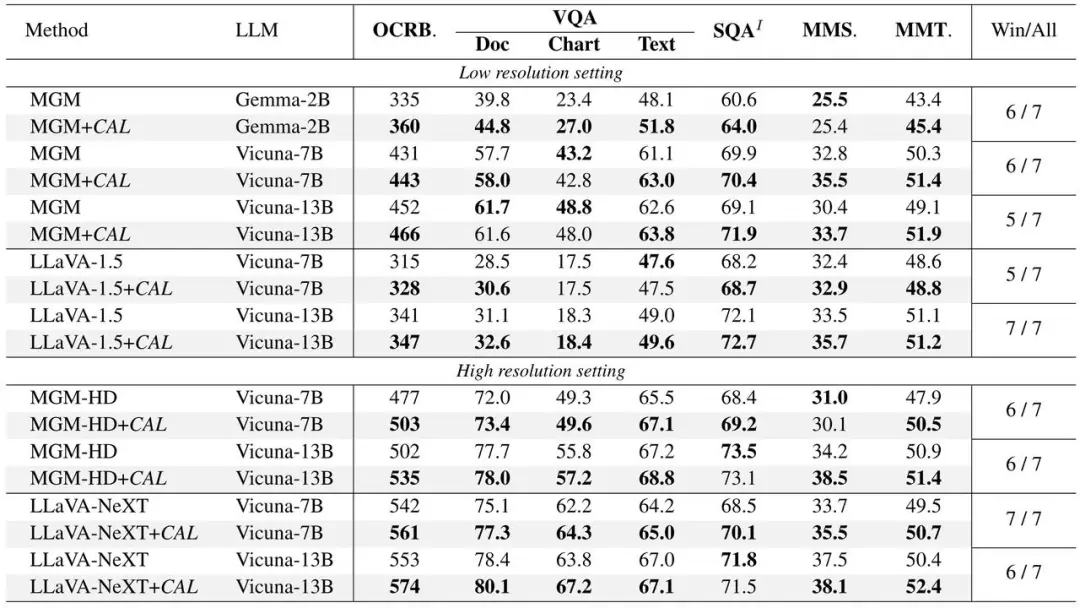
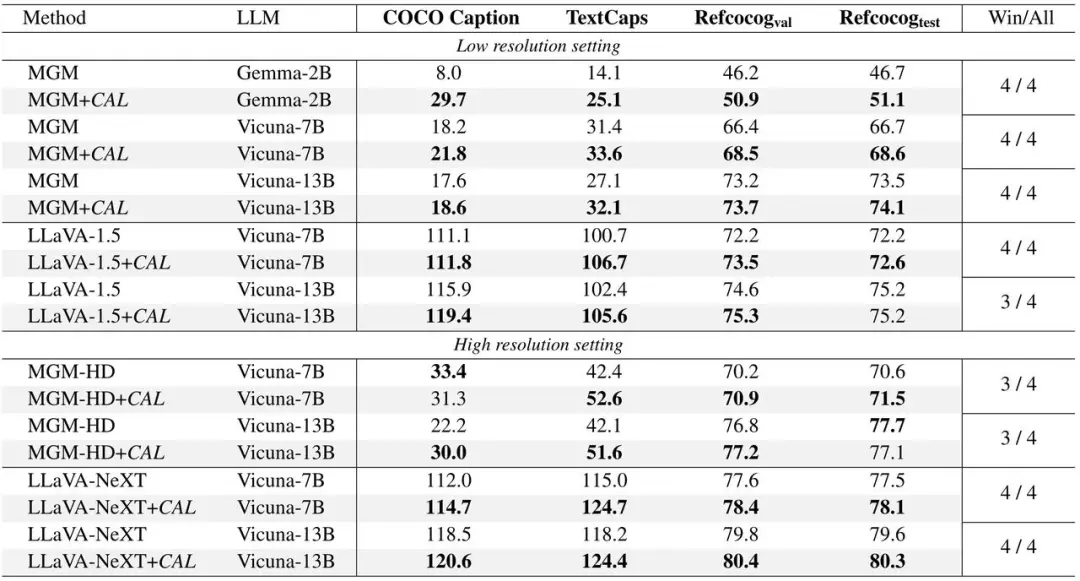
(1)使用 CAL 的模型在各项基准测试指标上表现更佳。
(2) 通过按比例随机交换两个图文对中的文本来制造一批噪声数据(图文错配),并用于模型训练,CAL 使得训练过程具有更强的数据抗噪性能。
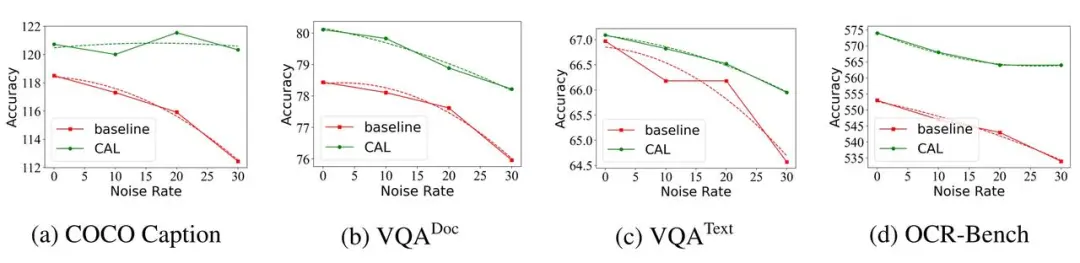
图三:在不同强度训练噪声情况下,CAL 与基线的性能表现
(3)对 QA case 中的答案部分计算其与图片 token 的注意力分数分布,并将其绘制在原图上,CAL 训练的模型拥有更清晰的注意力分布图。

图四:基线与 CAL 的 attention map 可视化,每对中的右边为 CAL
(4)将每个图片 token 映射为它最相似 LLM 词表中的文本 token,将其绘制到原图上,CAL 训练的模型映射内容更接近图片内容。

图五:将 image token 映射为最相似词表 token,并对应到原图上
文章来源于“机器之心”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
