世界模型又近了?MIT惊人研究:LLM已模拟现实世界,绝非随机鹦鹉!
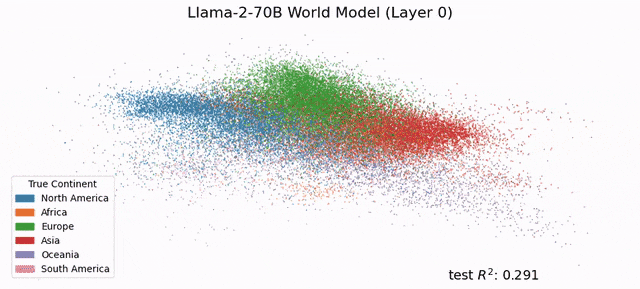
世界模型又近了?MIT惊人研究:LLM已模拟现实世界,绝非随机鹦鹉!MIT CSAIL的研究人员发现,LLM的「内心深处」已经发展出了对现实的模拟,模型对语言和世界的理解,绝不仅仅是简单的「鹦鹉学舌」。也就说,在未来,LLM会比今天更深层地理解语言。
来自主题: AI资讯
10086 点击 2024-08-18 10:34
 搜索
搜索
MIT CSAIL的研究人员发现,LLM的「内心深处」已经发展出了对现实的模拟,模型对语言和世界的理解,绝不仅仅是简单的「鹦鹉学舌」。也就说,在未来,LLM会比今天更深层地理解语言。

输出格式不同,竟然还能影响大模型发挥?!

现存的LLM是否真的有用?在工作中真实使用LLM的场景都有哪些?谷歌DeepMind科学家详细分享了他是如何「玩转」AI,帮助自己提质增效的。

最近的论文表明,LLM等生成模型可以通过搜索来扩展,并实现非常显著的性能提升。另一个复现实验也发现,让参数量仅8B的Llama 3.1模型搜索100次,即可在Python代码生成任务上达到GPT-4o同等水平。

预计在 2025 年能看到企业端 GenAI 的大规模放量

大语言模型 (LLM) 经历了重大的演变,最近,我们也目睹了多模态大语言模型 (MLLM) 的蓬勃发展,它们表现出令人惊讶的多模态能力。 特别是,GPT-4o 的出现显著推动了 MLLM 领域的发展。然而,与这些模型相对应的开源模型却明显不足。开源社区迫切需要进一步促进该领域的发展,这一点怎么强调也不为过。

长文本处理能力对LLM的重要性是显而易见的。在2023年初,即便是当时最先进的GPT-3.5,其上下文长度也仅限于2k,然而今日,128k的上下文长度已经成为衡量模型技术先进性的重要标志之一。那你知道LLMs的长文本阅读能力如何评估吗?

T-MAC是一种创新的基于查找表(LUT)的方法,专为在CPU上高效执行低比特大型语言模型(LLMs)推理而设计,无需权重反量化,支持混合精度矩阵乘法(mpGEMM),显著降低了推理开销并提升了计算速度。
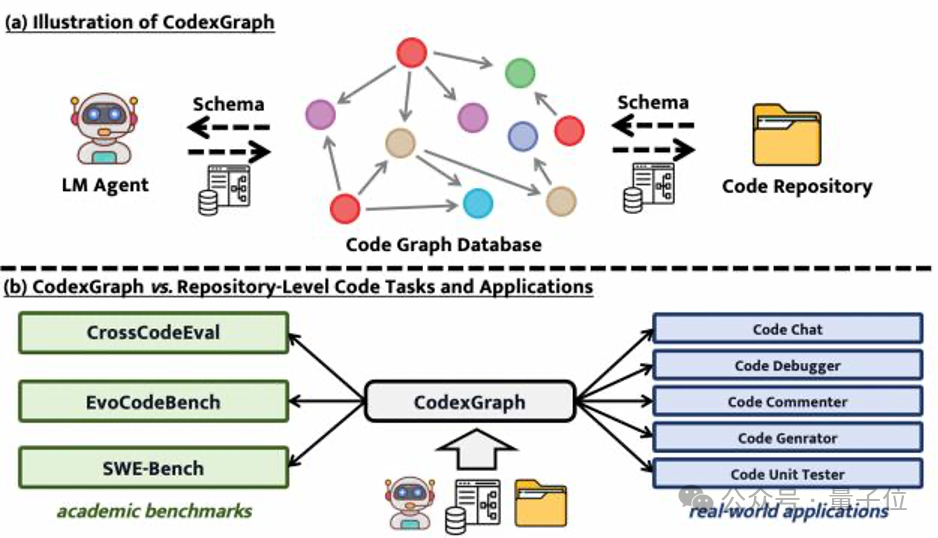
代码生成和补全任务做不完了?!

在过去的几年中,大型语言模型(Large Language Models, LLMs)在自然语言处理(NLP)领域取得了突破性的进展。这些模型不仅能够理解复杂的语境,还能够生成连贯且逻辑严谨的文本。