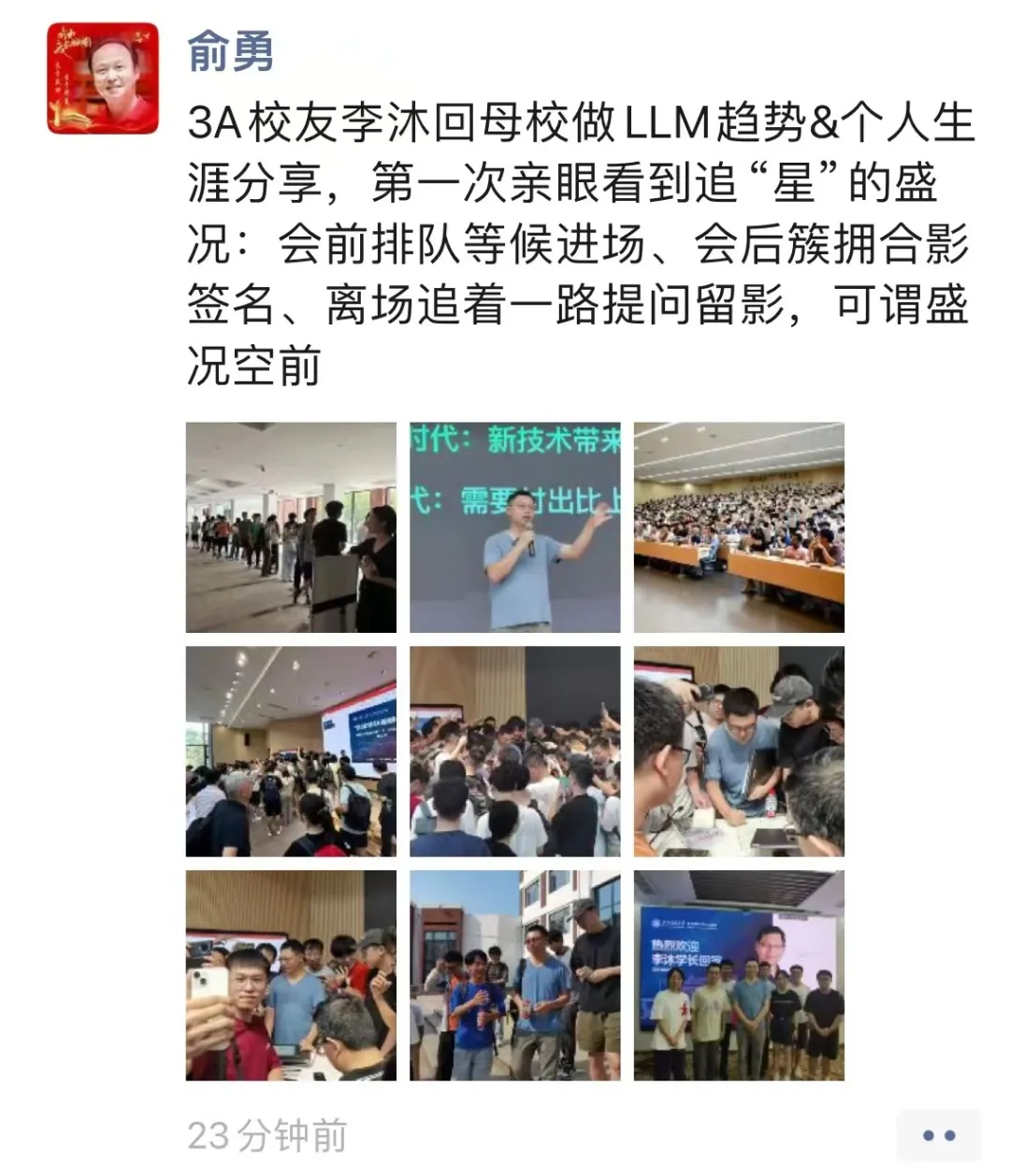
李沐重返母校上海交大,从LLM聊到个人生涯,这里是演讲全文
李沐重返母校上海交大,从LLM聊到个人生涯,这里是演讲全文昨天,李沐回到了母校上海交大,做了一场关于 LLM 和个人生涯的分享。本文是机器之心梳理的李沐演讲内容
来自主题: AI资讯
10893 点击 2024-08-25 11:15
 搜索
搜索
昨天,李沐回到了母校上海交大,做了一场关于 LLM 和个人生涯的分享。本文是机器之心梳理的李沐演讲内容
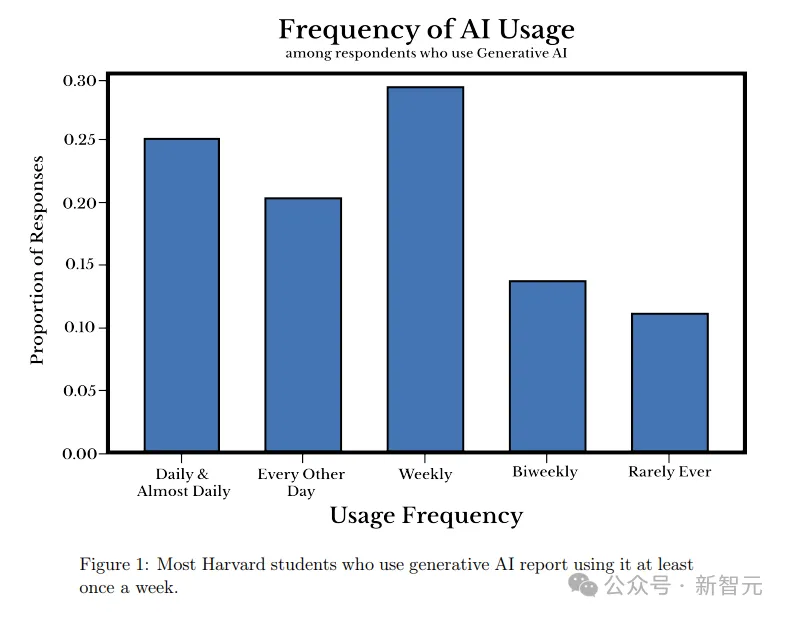
哈佛大学的一项最新研究表明,大语言模型已经深入学生的日常生活。为何学生们对AI的兴趣如此浓厚,背后的原因恐怕是这所大学的教授们。

OpenAI警告说,跟人工智能语音聊天可能会产生「情感依赖」。这种情感依赖是怎么产生的呢?MIT的一项研究指出,这可能是「求仁得仁」的结果,无怪乎连软件工程师也会对AI着迷。

Emory大学的研究团队提出了一种创新的方法,将大语言模型(LLM)在文本图(Text-Attributed Graph, 缩写为TAG)学习中的强大能力蒸馏到本地模型中,以应对文本图学习中的数据稀缺、隐私保护和成本问题。通过训练一个解释器模型来理解LLM的推理过程,并对学生模型进行对齐优化,在多个数据集上实现了显著的性能提升,平均提高了6.2%。

距离GPT-4首次发布已经过去了将近一年半的时间,Nature最近发表的一篇报告却探索出了这个「过气」模型的新用途——氨基酸和蛋白质的结构建模。
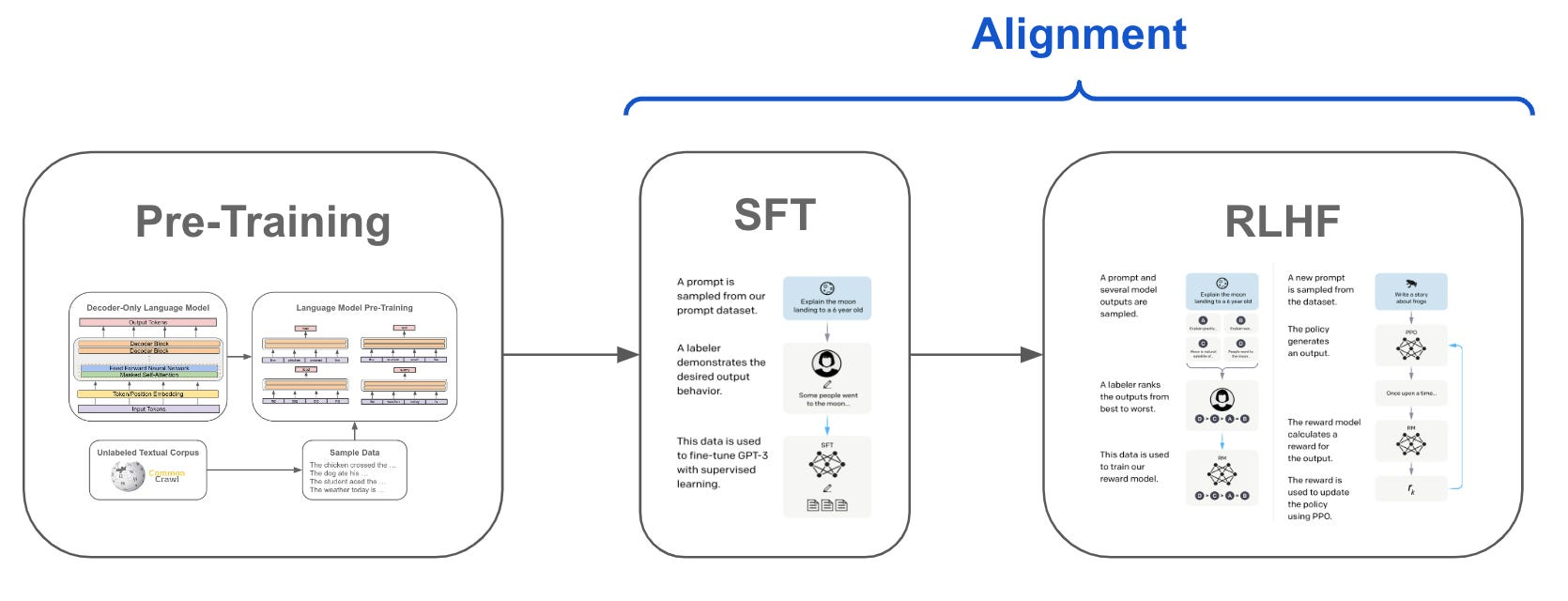
SFT、RLHF 和 DPO 都是先估计 LLMs 本身的偏好,再与人类的偏好进行对齐

虽然大语言模型(LLM)的能力不断突破,但在长文生成方面却一直存在瓶颈。近日,清华大学和智谱AI联合发布的最新研究成果,为解决这一难题提供了创新方案。这项名为"LongWriter"的技术,成功将AI模型的长文生成能力从约2000字提升至10000字以上,同时保持了高质量输出。这一成果通过创新的数据构建方法、模型训练策略和评估基准,为AI长文创作开辟了新天地。

Replika 是一款虚拟陪伴(AI 伴侣)应用,成立于 2017 年,在 LLM 技术爆发之前。

合成数据2.0秘诀曝光了!来自微软的研究人员们提出了智能体框架AgentInstruct,能够自动创建大量、多样化的合成数据。经过合成数据微调后的模型Orca-3,在多项基准上刷新了SOTA。
检索增强生成(Retrieval-Augmented Generation, RAG)技术正在彻底革新 AI 应用领域,通过将外部知识库和 LLM 内部知识的无缝整合,大幅提升了 AI 系统的准确性和可靠性。然而,随着 RAG 系统在各行各业的广泛部署,其评估和优化面临着重大挑战