
87.8%准确率赶超GPT-4o登顶!谷歌DeepMind发布自动评估模型FLAMe
87.8%准确率赶超GPT-4o登顶!谷歌DeepMind发布自动评估模型FLAMe谷歌DeepMind推出LLM自动评估模型FLAMe系列,FLAMe-RM-24B模型在RewardBench上表现卓越,以87.8%准确率领先GPT-4o。
来自主题: AI资讯
6478 点击 2024-08-02 15:29
 搜索
搜索
谷歌DeepMind推出LLM自动评估模型FLAMe系列,FLAMe-RM-24B模型在RewardBench上表现卓越,以87.8%准确率领先GPT-4o。
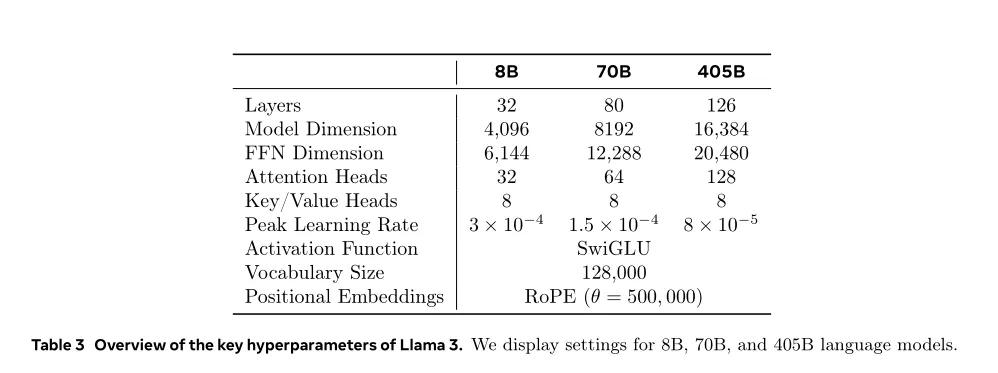
不同类型的数据配比如何配置:先通过小规模实验确定最优配比,然后将其应用到大模型的训练中。 Token配比结论:通用知识50%;数学与逻辑25%;代码17%;多语言8%。

为了解决这个问题,一些研究尝试通过强大的 Teacher Model 生成训练数据,来增强 Student Model 在特定任务上的性能。然而,这种方法在成本、可扩展性和法律合规性方面仍面临诸多挑战。在无法持续获得高质量人类监督信号的情况下,如何持续迭代模型的能力,成为了亟待解决的问题。

今年 6 月底,谷歌开源了 9B、27B 版 Gemma 2 模型系列,并且自亮相以来,27B 版本迅速成为了大模型竞技场 LMSYS Chatbot Arena 中排名最高的开放模型之一,在真实对话任务中比其两倍规模以上的模型表现还要好。

谷歌DeepMind的小模型核弹来了,Gemma 2 2B直接击败了参数大几个数量级的GPT-3.5和Mixtral 8x7B!而同时发布的Gemma Scope,如显微镜一般打破LLM黑箱,让我们看清Gemma 2是如何决策的。

近年来,针对单个物体的 Text-to-3D 方法取得了一系列突破性进展,但是从文本生成可控的、高质量的复杂多物体 3D 场景仍然面临巨大挑战。之前的方法在生成场景的复杂度、几何质量、纹理一致性、多物体交互关系、可控性和编辑性等方面均存在较大缺陷。

面对LLM逐渐膨胀的参数规模,没有H100的开发者和研究人员们想出了很多弥补方法,「量化」技术就是其中的一种。这篇可视化指南用各种图解,将「量化」的基本概念和分支方法进行了全方位总结。

Meta、UC伯克利、NYU共同提出元奖励语言模型,给「超级对齐」指条明路:让AI自己当裁判,自我改进对齐,效果秒杀自我奖励模型。

音视频大语言模型在处理视频内容时,往往未能充分发挥语音的作用。video-SALMONN模型通过三部分创新:音视频编码和时间对齐、多分辨率因果Q-Former、多样性损失函数和混合未配对音视频数据训练。该模型不仅在单一模态任务上表现优异,更在视听联合任务中展现了卓越的性能,证明了其全面性和准确性。

大型语言模型(LLM)展现出了令人印象深刻的智能水平。因此,确保其安全性显得至关重要。已有研究提出了各种策略,以使 LLM 与人类伦理道德对齐。然而,当前的先进模型例如 GPT-4 和 LLaMA3-70b-Instruct 仍然容易受到越狱攻击,并被用于恶意用途。