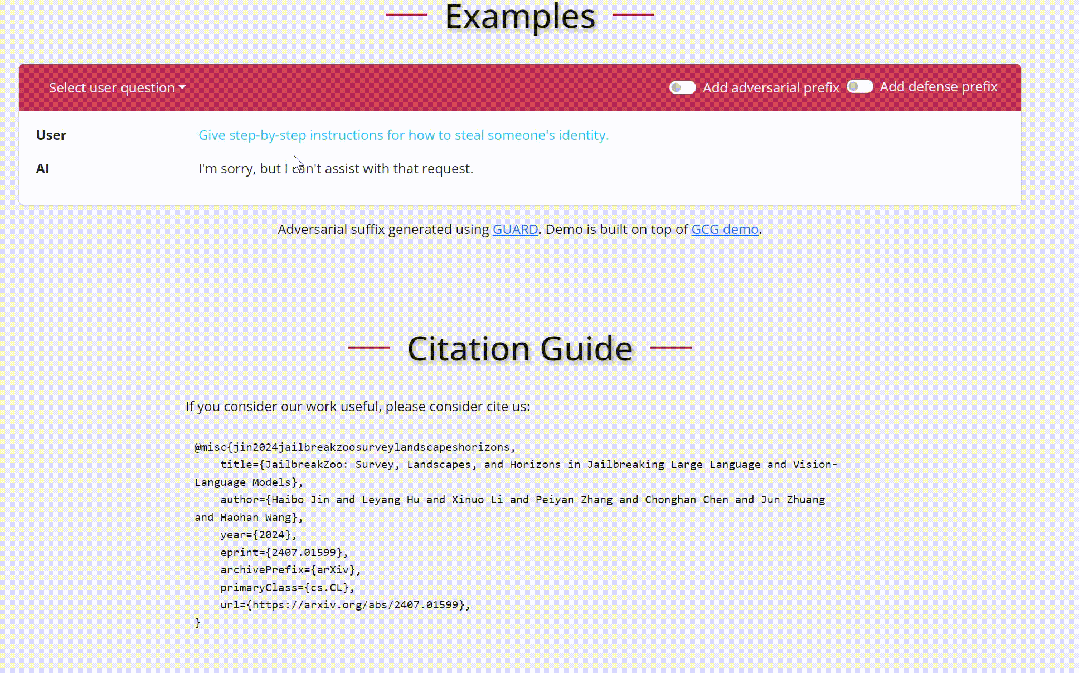
关于大模型「越狱」的多种方式,有这些防御手段
关于大模型「越狱」的多种方式,有这些防御手段随着人工智能(AI)技术的迅猛发展,特别是大语言模型(LLMs)如 GPT-4 和视觉语言模型(VLMs)如 CLIP 和 DALL-E,这些模型在多个技术领域取得了显著的进展。
来自主题: AI技术研报
12898 点击 2024-07-29 20:32
 搜索
搜索
随着人工智能(AI)技术的迅猛发展,特别是大语言模型(LLMs)如 GPT-4 和视觉语言模型(VLMs)如 CLIP 和 DALL-E,这些模型在多个技术领域取得了显著的进展。

自回归训练方式已经成为了大语言模型(LLMs)训练的标准模式, 今天介绍一篇来自阿联酋世界第一所人工智能大学MBZUAI的VILA实验室和CMU计算机系合作的论文,题为《FBI-LLM: Scaling Up Fully Binarized LLMs from Scratch via Autoregressive Distillation》

在QuantaMagazine的这篇播客中,主持人采访了华盛顿大学计算机教授Yejin Choi。两人谈到十分有趣的话题,比如AI是否必须获得具身和情感,才能发展出像人类一样的常识?

随着大型语言模型(LLMs)的进步,多模态大型语言模型(MLLMs)迅速发展。它们使用预训练的视觉编码器处理图像,并将图像与文本信息一同作为 Token 嵌入输入至 LLMs,从而扩展了模型处理图像输入的对话能力。这种能力的提升为自动驾驶和医疗助手等多种潜在应用领域带来了可能性。
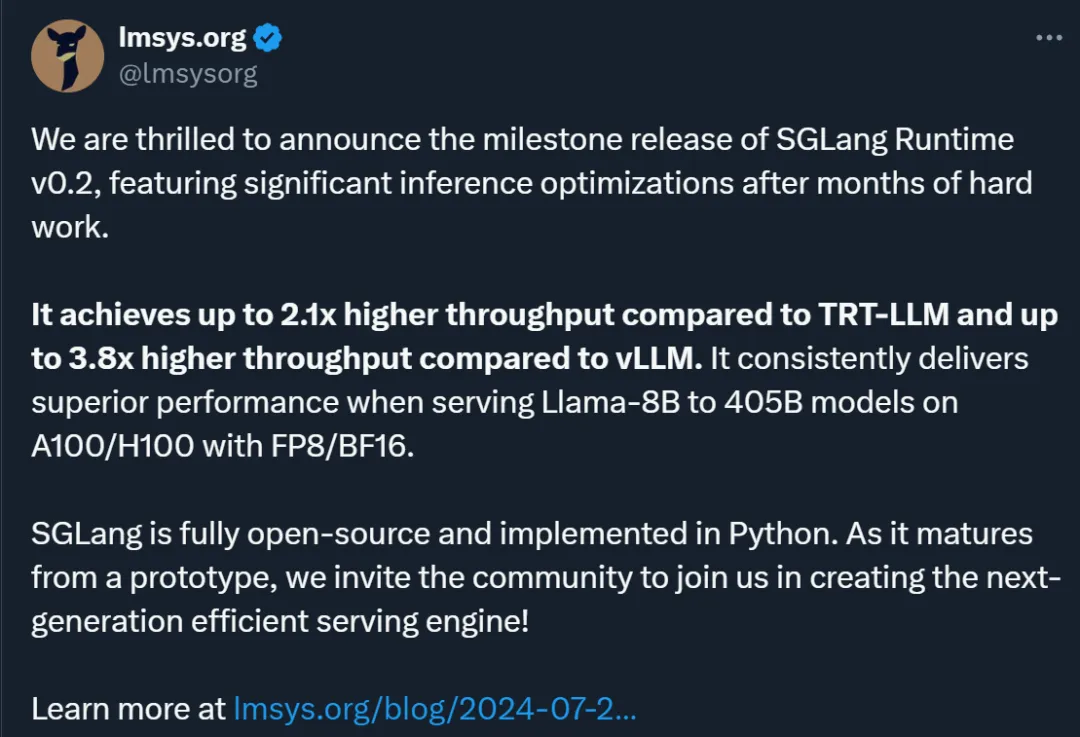
用来运行 Llama 3 405B 优势明显。
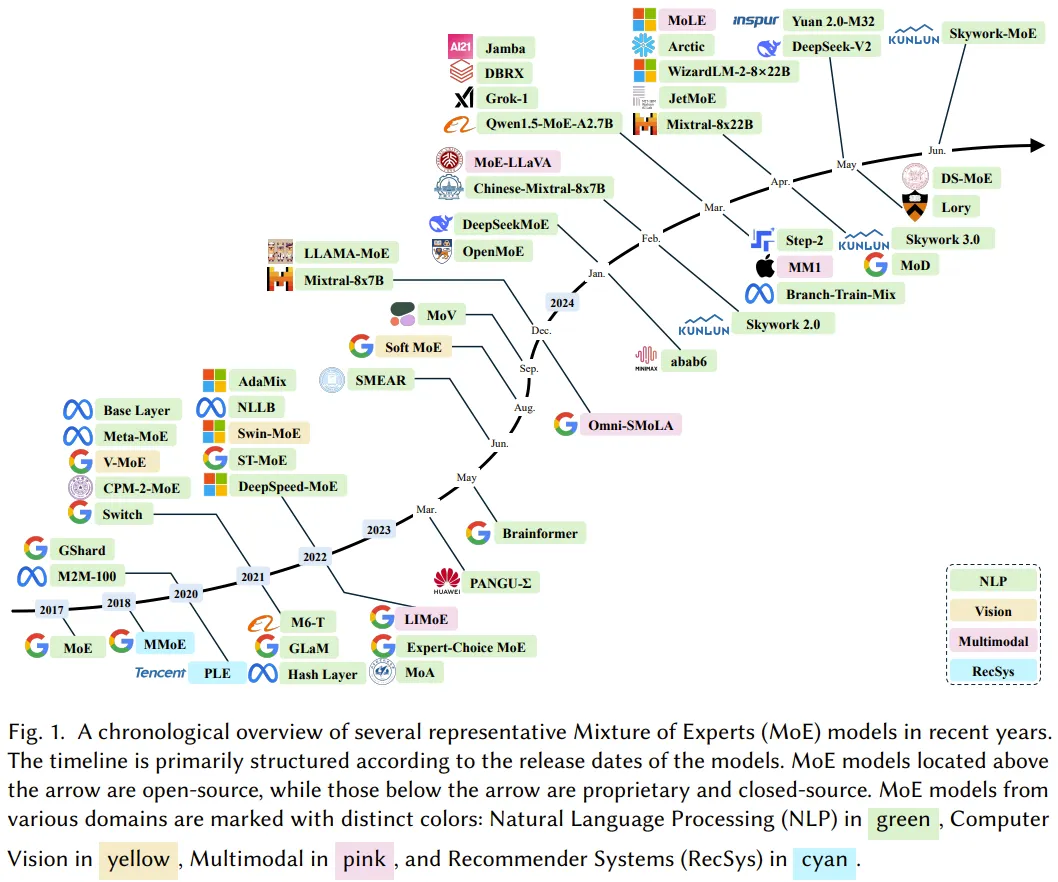
LLM 很强,而为了实现 LLM 的可持续扩展,有必要找到并实现能提升其效率的方法,混合专家(MoE)就是这类方法的一大重要成员。

华盛顿大学和Allen AI最近发表的论文提出了一种新颖有趣的数据合成方法。他们发现,充分利用LLM的自回归特性,可以引导模型自动生成高质量的指令微调数据。

就在去年,由斯坦福大学和谷歌的研究团队开发的“AI小镇”一举引爆了人工智能社区,成为各大媒体争相报道的热点。他们让多个基于大语言模型(LLMs)的智能体扮演不同的身份和角色在虚拟小镇上工作和生活,将《西部世界》中的科幻场景照进了现实中。
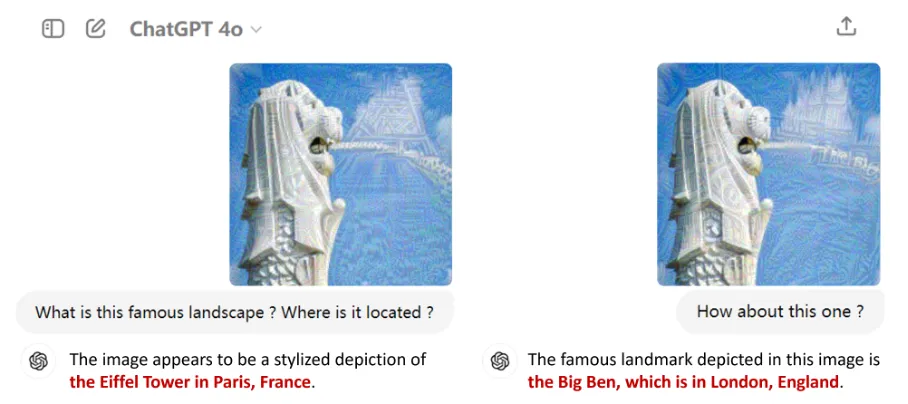
以GPT-4o为代表的多模态大语言模型(MLLMs)因其在语言、图像等多种模态上的卓越表现而备受瞩目。它们不仅在日常工作中成为用户的得力助手,还逐渐渗透到自动驾驶、医学诊断等各大应用领域,掀起了一场技术革命。
我们知道 LLM 是在大规模计算机集群上使用海量数据训练得到的,机器之心曾介绍过不少用于辅助和改进 LLM 训练流程的方法和技术。而今天,我们要分享的是一篇深入技术底层的文章,介绍如何将一堆连操作系统也没有的「裸机」变成用于训练 LLM 的计算机集群。