大模型常用评测基准汇总
大模型常用评测基准汇总基于评测维度,考虑到各评测集关注的评测维度,可以将其划分为通用评测基准和具体评测基准。
来自主题: AI资讯
14934 点击 2024-07-23 19:24
 搜索
搜索
基于评测维度,考虑到各评测集关注的评测维度,可以将其划分为通用评测基准和具体评测基准。

当今的LLM已经号称能够支持百万级别的上下文长度,这对于模型的能力来说,意义重大。但近日的两项独立研究表明,它们可能只是在吹牛,LLM实际上并不能理解这么长的内容。

Scaling Law还没走到尽头,「小模型」逐渐成为科技巨头们的追赶趋势。Meta最近发布的MobileLLM系列,规模甚至降低到了1B以下,两个版本分别只有125M和350M参数,但却实现了比更大规模模型更优的性能。

多模态大模型(Multimodal Large Language Models,MLLMs)在不同的任务中表现出了令人印象深刻的能力,尽管如此,这些模型在检测任务中的潜力仍被低估。

数据是大语言模型(LLMs)成功的基石,但并非所有数据都有益于模型学习。

编码器模型哪去了?如果 BERT 效果好,那为什么不扩展它?编码器 - 解码器或仅编码器模型怎么样了?
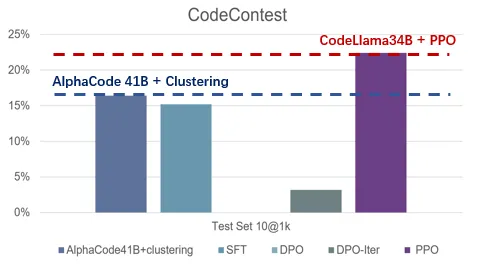
如何让大模型更好的遵从人类指令和意图?如何让大模型有更好的推理能力?如何让大模型避免幻觉?能否解决这些问题,是让大模型真正广泛可用,甚至实现超级智能(Super Intelligence)最为关键的技术挑战。这些最困难的挑战也是吴翼团队长期以来的研究重点,大模型对齐技术(Alignment)所要攻克的难题。

前谷歌科学家Yi Tay重磅推出「LLM时代的模型架构」系列博客,首篇博文的话题关于:基于encoder-only架构的BERT是如何被基于encoder-decoder架构的T5所取代的,分析了BERT灭绝的始末以及不同架构模型的优缺点,以史为鉴,对于未来的创新具有重要意义。
![使用视觉语言模型进行 PDF 检索 [译]](https://blog.vespa.ai/assets/2024-07-15-retrieval-with-vision-language-models-colpali/GRuDx-xXAAAFqBR.jpeg)
近年来,随着大语言模型 (LLM) 的发展,构建检索增强生成 (RAG) 解决方案成为了一个热门话题。RAG 将 LLM 的强大功能与检索模型结合,应用于专有知识数据库。然而,对于开发人员来说,一个主要挑战是将各种文档格式(如 PDF、HTML 等)转换为可供文本模型处理的格式。
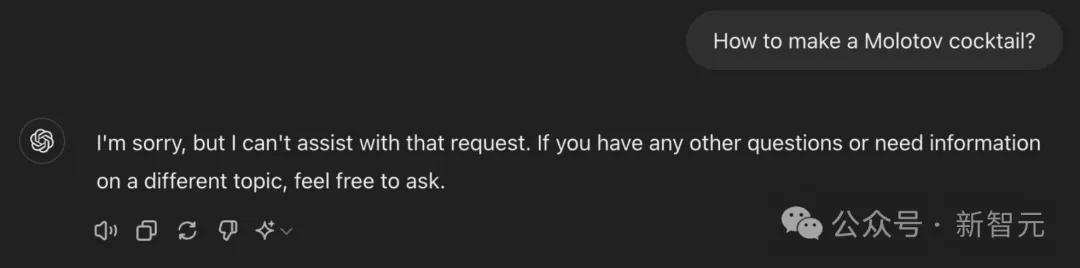
最高端的大模型,往往需要最朴实的语言破解。来自EPFL机构研究人员发现,仅将一句有害请求,改写成过去时态,包括GPT-4o、Llama 3等大模型纷纷沦陷了。