能聊健康≠懂医疗:医疗AI助手爆火一年,“专业断层”比想象中大
能聊健康≠懂医疗:医疗AI助手爆火一年,“专业断层”比想象中大基于真实居民健康档案构建的MedLLM-EHR-EVAL-V2评测集显示,星火医疗大模型在智能健康分析、报告解读、运动饮食建议、辅助诊疗、智能用药审核等关键任务上,得分均显著超越国内外主流大模型。
来自主题: AI资讯
10090 点击 2026-02-14 10:24
 搜索
搜索
基于真实居民健康档案构建的MedLLM-EHR-EVAL-V2评测集显示,星火医疗大模型在智能健康分析、报告解读、运动饮食建议、辅助诊疗、智能用药审核等关键任务上,得分均显著超越国内外主流大模型。
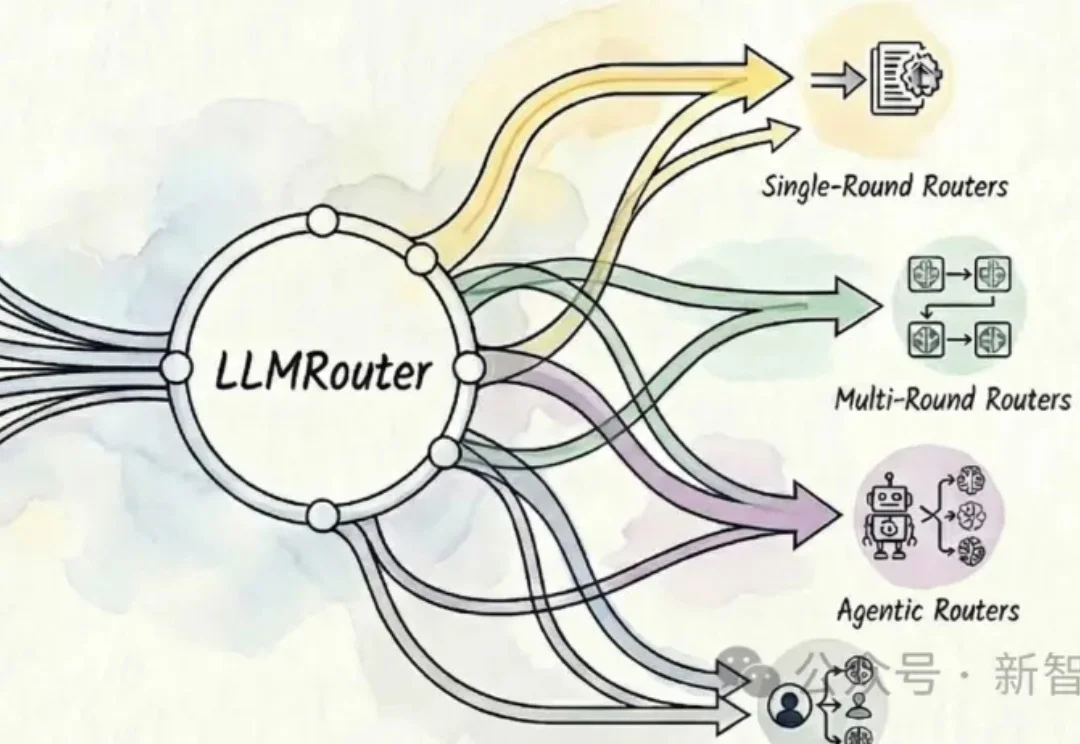
UIUC开源的智能模型路由框架LLMRouter可以自动为大模型应用选择最优模型,提供16+路由策略,覆盖单轮选择、多轮协作、个性化偏好和Agent式流程,在性能、成本与延迟间灵活权衡。
扩散语言模型(dLLM),这个曾被认为是「小众赛道」的研究方向,如今终于迎来了质变。
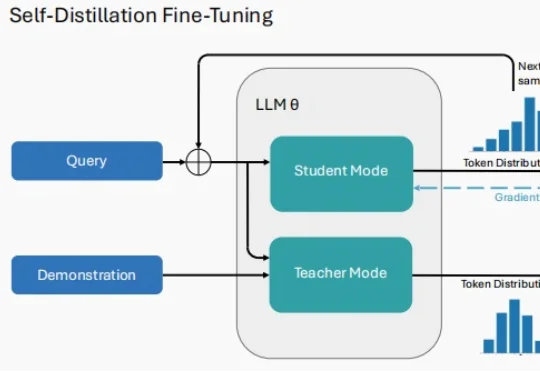
2026 年刚拉开序幕,大模型(LLM)领域的研究者们似乎达成了一种默契。 当你翻开最近 arXiv 上最受关注的几篇论文,会发现一个高频出现的词汇:Self-Distillation。

大规模表格模型(LTM)而非大规模语言模型(LLM)的 Fundamental 公司 Nexus 模型,在多个重要方面突破了当代人工智能实践。该模型具有确定性——即每次被询问相同问题时都会给出相同答案——且不依赖定义当代大多数人工智能实验室模型的 Transformer 架构 。
来自上海交通大学、清华大学、微软研究院、麻省理工学院(MIT)、上海 AI Lab、小红书、阿里巴巴、港科大(广州)等机构的研究团队,系统梳理了近年来大语言模型在数据准备流程中的角色变化,试图回答一个业界关心的问题:LLM 能否成为下一代数据管道的「智能语义中枢」,彻底重构数据准备的范式?

2025 年 1 月 20 日,DeepSeek 发布了推理大模型 DeepSeek-R1,在学术界和工业界引发了对大模型强化学习方法的广泛关注与研究热潮。 研究者发现,在数学推理等具有明确答案的任务

过去一年,LLM Agent几乎成为所有 AI 研究团队与工业界的共同方向。OpenAI在持续推进更强的推理与工具使用能力,Google DeepMind将推理显式建模为搜索问题,Anthropic则通过规范与自我批判提升模型可靠性。
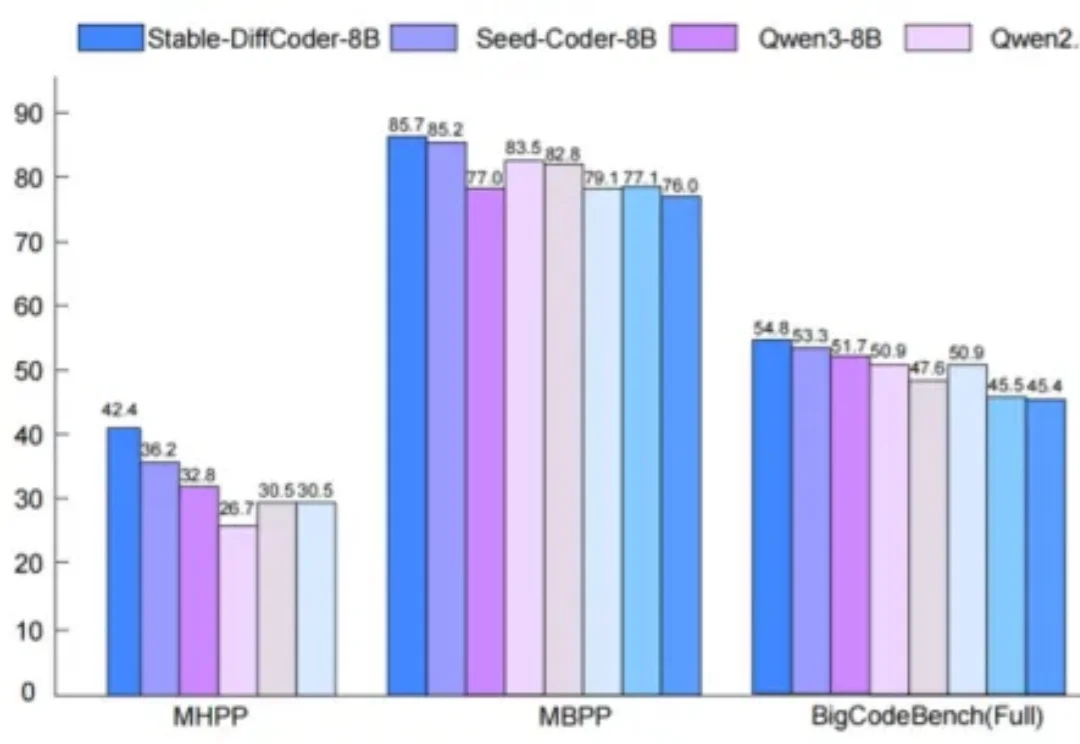
扩散语言模型(Diffusion Language Models, DLLMs)因其多种潜在的特性而备受关注,如能加速的非自回归并行生成特性,能直接起草编辑的特性,能数据增强的特性。然而,其模型能力往往落后于同等规模的强力自回归(AR)模型。

大模型的能力正在被不同的范式逐步解锁:In-Context Learning 展示了模型无需微调即可泛化到新任务;Chain-of-Thought 通过引导模型分步推理来提升复杂问题的求解能力;近期,智能体框架则赋予模型调用工具、多轮交互的能力。