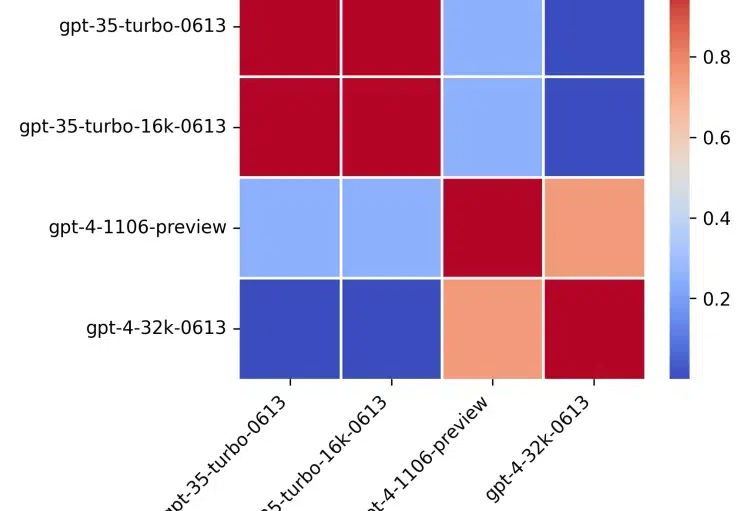
微软发现不同prompt模版会导致最大40%性能差距!
微软发现不同prompt模版会导致最大40%性能差距!这篇文章研究了提示格式对大型语言模型(LLM)性能的影响。
来自主题: AI技术研报
7008 点击 2024-11-27 13:48
 搜索
搜索
这篇文章研究了提示格式对大型语言模型(LLM)性能的影响。
2022 年,以ChatGPT 大语言模型(LLM)的发布为标志, AI 神经网络的类人学习能力取得了里程碑式的进展,在全球范围内掀起了一股 AI 热潮。

将知识图谱技术与RAG有机结合的GraphRAG可谓是今年下半年来的LLM应用领域的一个热点,借助大模型从非结构化文本数据创建知识图谱与摘要,并结合图与向量索引技术来提高对复杂用户查询的检索增强与响应质量。
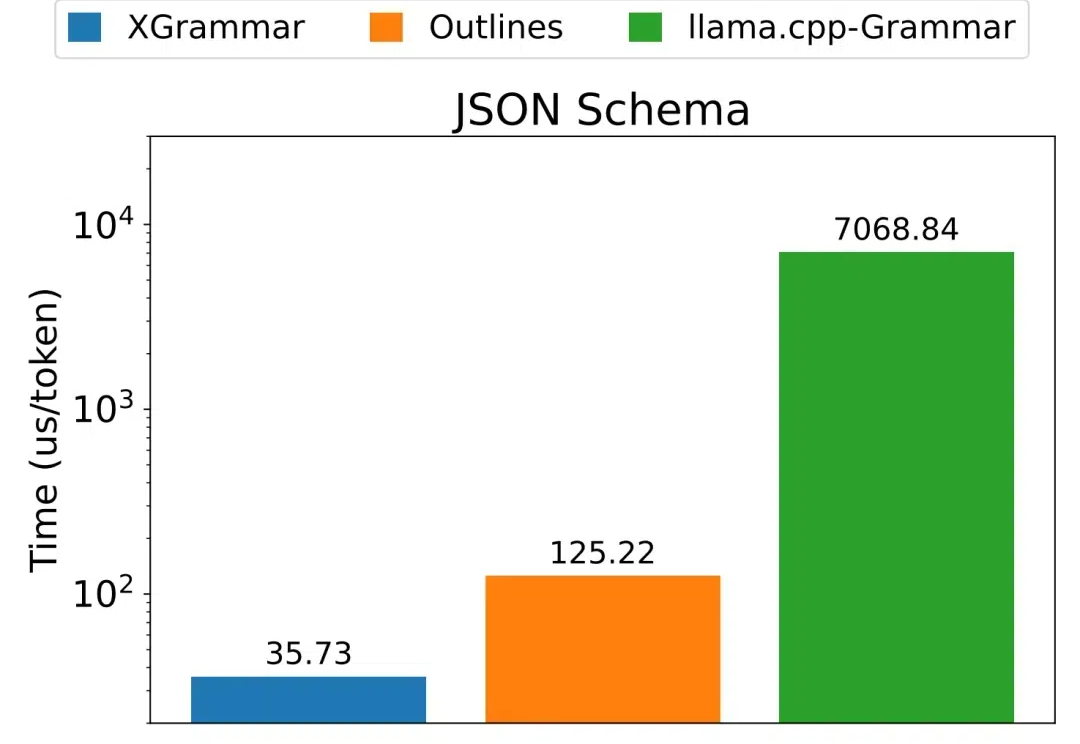
不管是编写和调试代码,还是通过函数调用来使用外部工具,又或是控制机器人,都免不了需要 LLM 生成结构化数据,也就是遵循某个特定格式(如 JSON、SQL 等)的数据。 但使用上下文无关语法(CFG)来进行约束解码的方法并不高效。针对这个困难,陈天奇团队提出了一种新的解决方案:XGrammar。
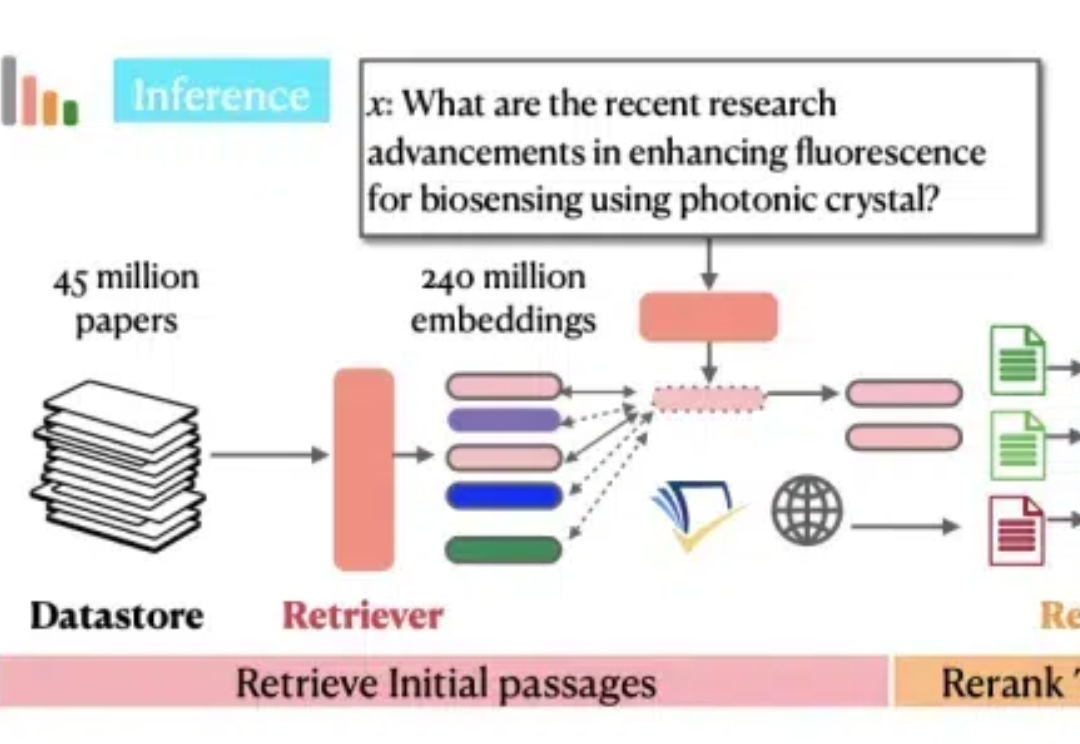
Ai2和华盛顿大学联合Meta、CMU、斯坦福等机构发布了最新的OpenScholar系统,使用检索增强的方法帮助科学家进行文献搜索和文献综述工作,而且做到了数据、代码、模型权重的全方位开源。

如果给LLM做MBTI,会得到什么结果?UC伯克利的最新研究就发现,不同模型真的有自己独特的性格

各位大佬,激动人心的时刻到啦!Anthropic 开源了一个革命性的新协议——MCP(模型上下文协议),有望彻底解决 LLM 应用连接数据难的痛点!它的目标是让前沿模型生成更好、更相关的响应。以后再也不用为每个数据源写定制的集成代码了,MCP 一个协议全搞定!
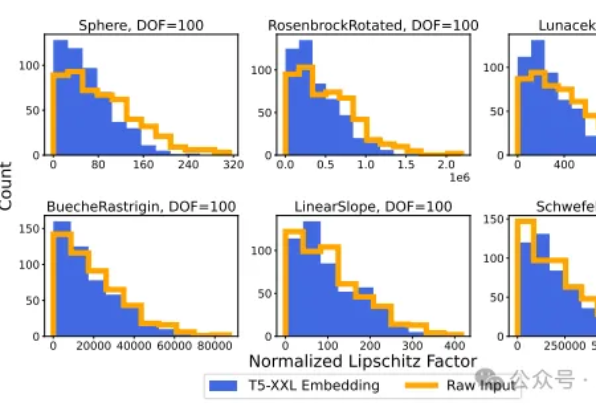
在人工智能领域,大语言模型(LLM)的向量嵌入能力一直被视为处理文本数据的利器。然而,斯坦福大学和Google DeepMind的研究团队带来了一个颠覆性发现:LLM的向量嵌入能力可以有效应用于回归任务。
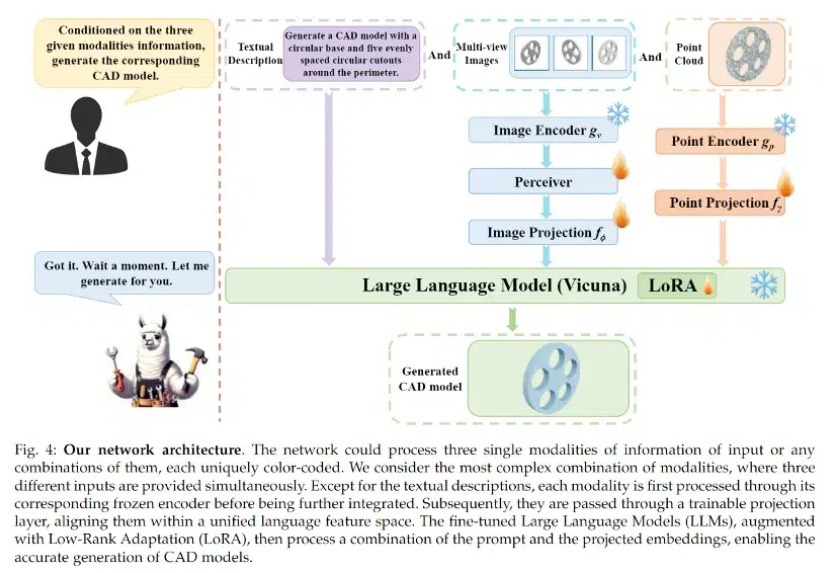
该项目由忆生科技联合香港大学、上海科技大学共同完成,是全球首个同时支持文本描述、图像、点云等多模态输入的计算机辅助设计(CAD)生成大模型。
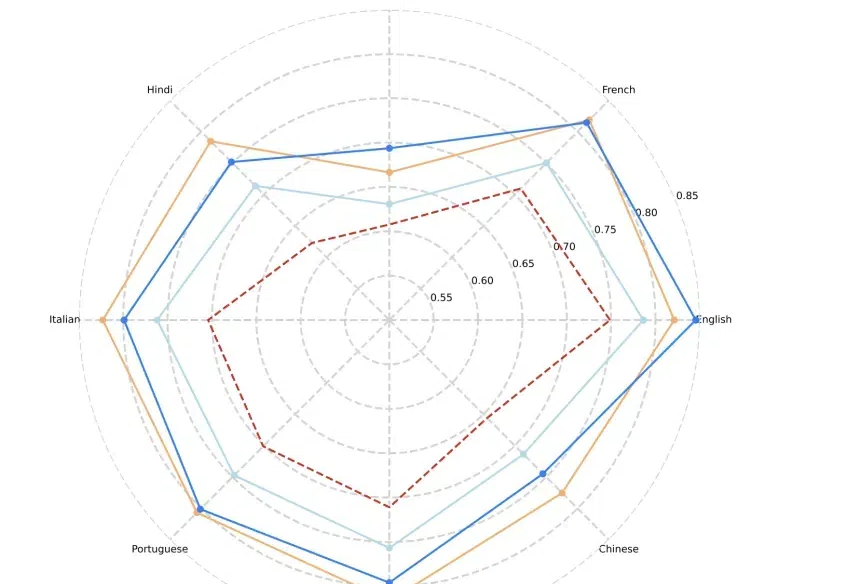
Meta全新发布的基准Multi-IF涵盖八种语言、4501个三轮对话任务,全面揭示了当前LLM在复杂多轮、多语言场景中的挑战。所有模型在多轮对话中表现显著衰减,表现最佳的o1-preview模型在三轮对话的准确率从87.7%下降到70.7%;在非拉丁文字语言上,所有模型的表现显著弱于英语。