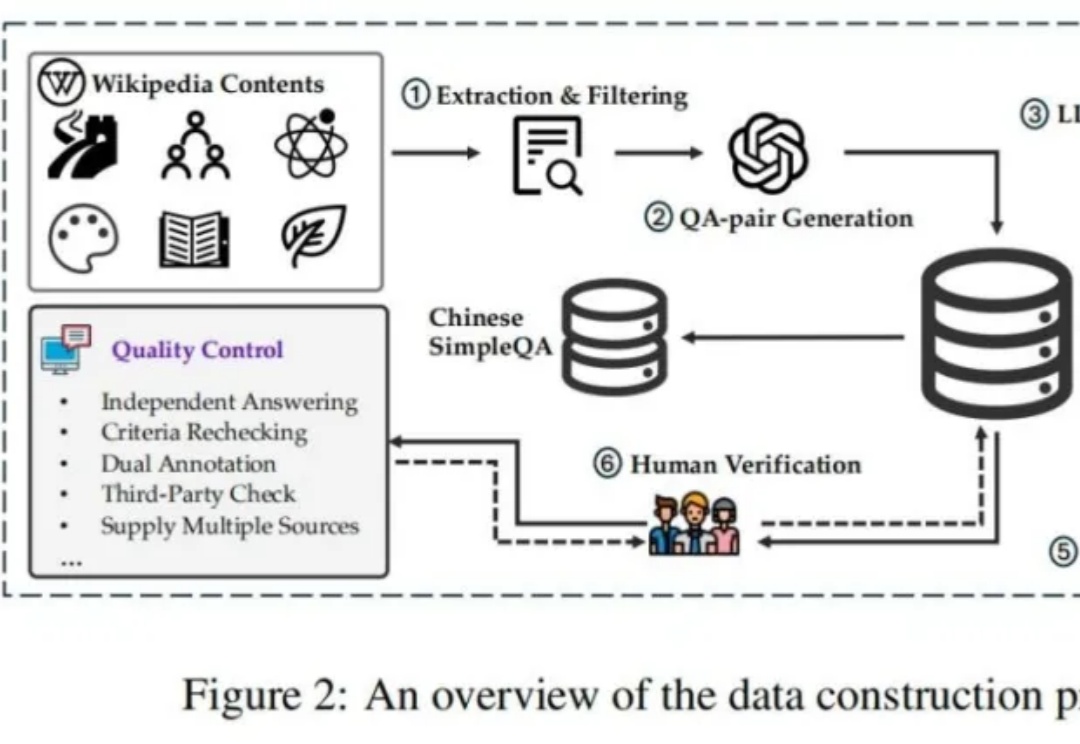
史上最严“中文真实性评估”:OpenAI o1第1豆包第2,其它全部不及格
史上最严“中文真实性评估”:OpenAI o1第1豆包第2,其它全部不及格新的大语言模型(LLM)评估基准对于跟上大语言模型的快速发展至关重要。
来自主题: AI技术研报
9755 点击 2024-11-21 13:47
 搜索
搜索
新的大语言模型(LLM)评估基准对于跟上大语言模型的快速发展至关重要。
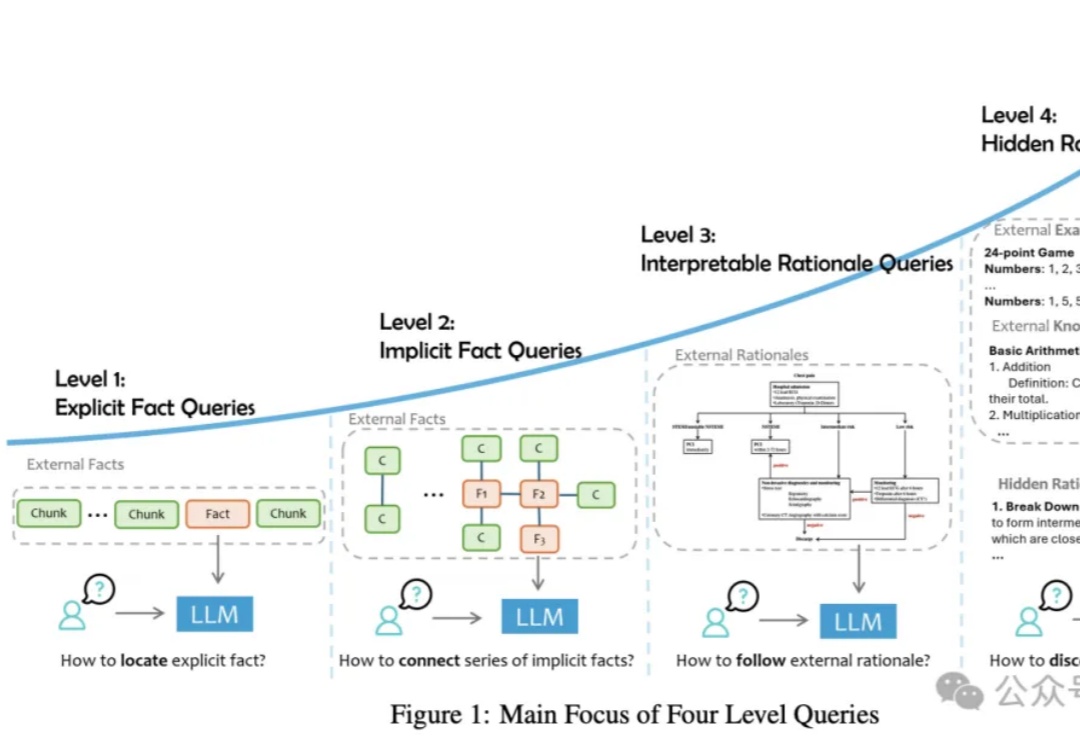
论文提出了一种RAG任务分类法,将用户查询分为四个级别,并讨论了将外部数据集成到LLMs中的三种主要方式。从简单的事实检索到复杂的推理任务,每个级别都有其独特的难点和解决方案,需要不同的技术和方法来优化性能。
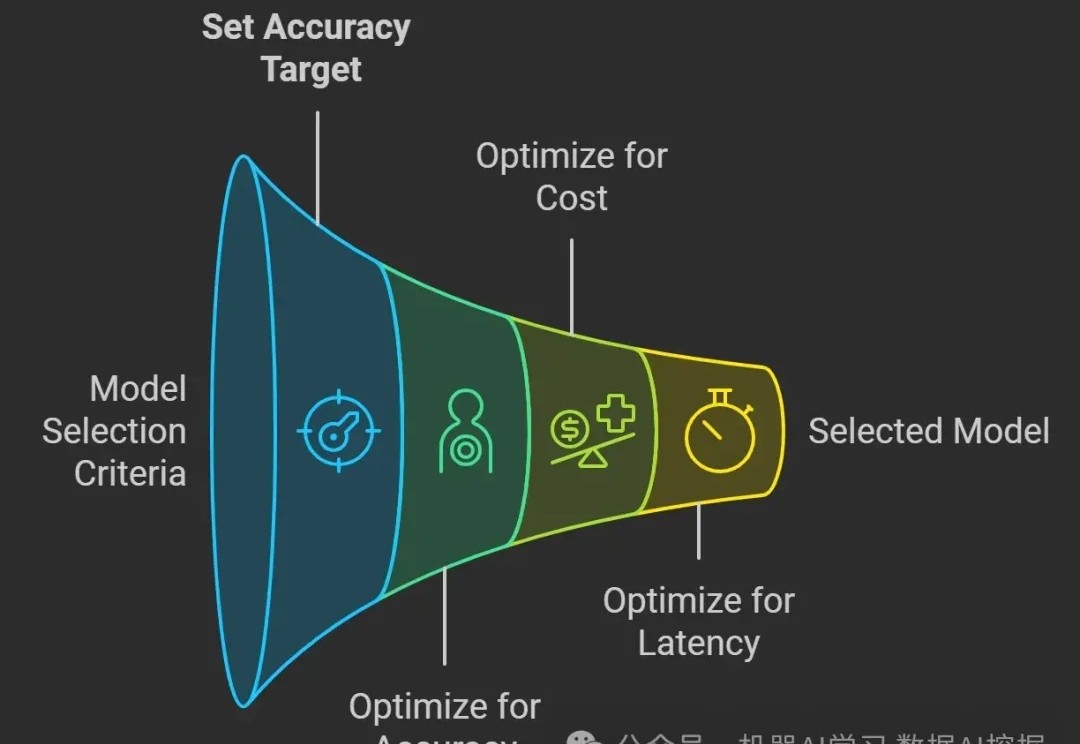
当你开始任何客户项目时,最常见的问题之一是:“我应该使用哪个模型?” 这个问题没有直接的答案,它是一个过程。在本博客中,我们将解释这个过程,这样下次客户问你这个问题时,你可以与他们分享这份文档。
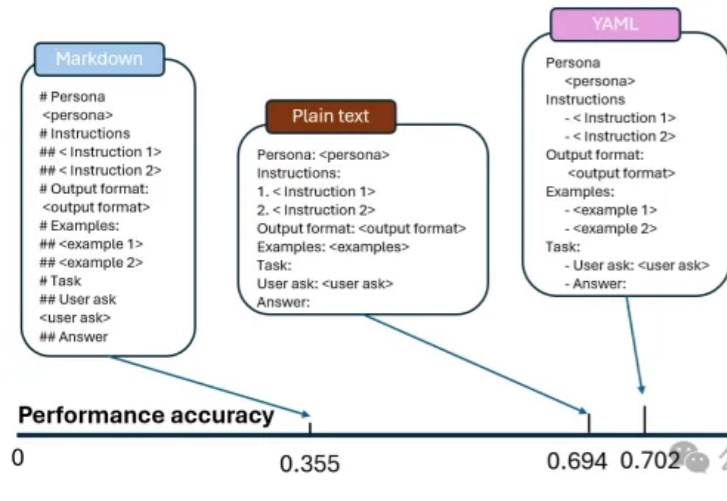
朋友们,想了解为什么同一模型会带来大量结果的不一致性吗?今天,我们来一起深入分析一下来自微软和麻省理工学院的一项重大发现——不同的Prompt格式如何显著影响LLM的输出精度。这些研究结果对于应用Prompt优化设计具有非常重要的应用价值。
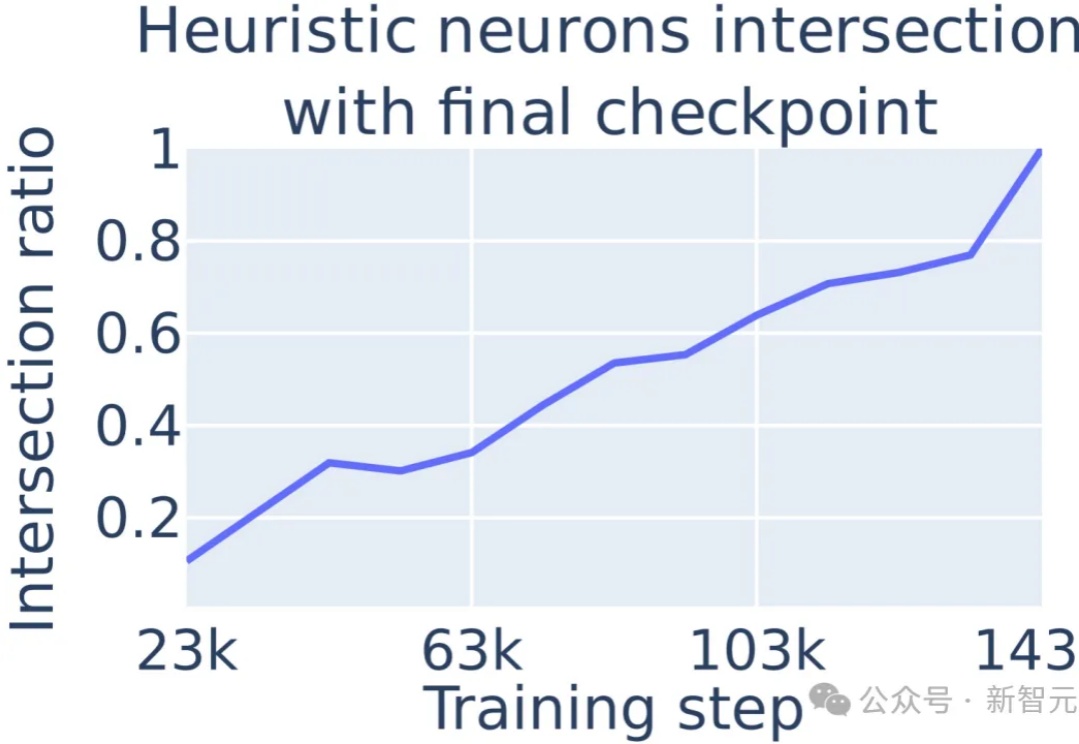
大模型在数学问题上的表现不佳,原因在于采取启发式算法进行数学运算的,通过定位到多层感知机(MLP)中的单个神经元,可以对进行数学运算的具体过程进行解释。

自我纠错(Self Correction)能力,传统上被视为人类特有的特征,正越来越多地在人工智能领域,尤其是大型语言模型(LLMs)中得到广泛应用,最近爆火的OpenAI o1模型[1]和Reflection 70B模型[2]都采取了自我纠正的方法。
自从生成式 AI 和 LLM 在世界舞台上占据中心位置以来,员工们一直在思考如何最好地将这些变革性的新工具应用于他们的工作流程。然而,他们中的许多人在尝试将生成式 AI 集成到企业环境中时遇到了类似的问题,例如隐私泄露、缺乏相关性以及需要更好的个性化结果。

一位AI从业者分享的14天学习路线图,涵盖大模型从基础到高级的主要关键概念!

最近,Nature上的一项研究,全面驳斥了LLM具有类人推理能力的说法。研究者设定的「人类亲吻难题」把7个大模型彻底绕晕。最终研究者表示,与其说LLM是科学理论,不如说它们更接近工具,比如广义导数。

利用概念激活向量破解大模型的安全对齐,揭示LLM重要安全风险漏洞。