
深度|如何最大化 GPU 利用效率,让 ROI 最大化?
深度|如何最大化 GPU 利用效率,让 ROI 最大化?前不久在人工智能的帮助下,两位科学家获得了诺贝尔物理学奖。可以说人工智能已经在很多领域被广泛应用了。随着大语言模型(LLM)和深度学习的广泛应用,GPU 也已成为机器学习工程师和研究人员最重要的计算资源之一。
来自主题: AI资讯
9240 点击 2024-10-21 14:14
 搜索
搜索
前不久在人工智能的帮助下,两位科学家获得了诺贝尔物理学奖。可以说人工智能已经在很多领域被广泛应用了。随着大语言模型(LLM)和深度学习的广泛应用,GPU 也已成为机器学习工程师和研究人员最重要的计算资源之一。
近期在LLM方面,AI搜索热度居高不下,遥感业务也能做AI搜索。


近日,来自谷歌和苹果的研究表明:AI模型掌握的知识比表现出来的要多得多!这些真实性信息集中在特定的token中,利用这一属性可以显著提高检测LLM错误输出的能力。

LLM训练速度还可以再飙升20倍!英伟达团队祭出全新架构归一化Transformer(nGPT),上下文越长,训练速度越快,还能维持原有精度。

大型语言模型(LLMs)虽然在适应新任务方面取得了长足进步,但它们仍面临着巨大的计算资源消耗,尤其在复杂领域的表现往往不尽如人意。
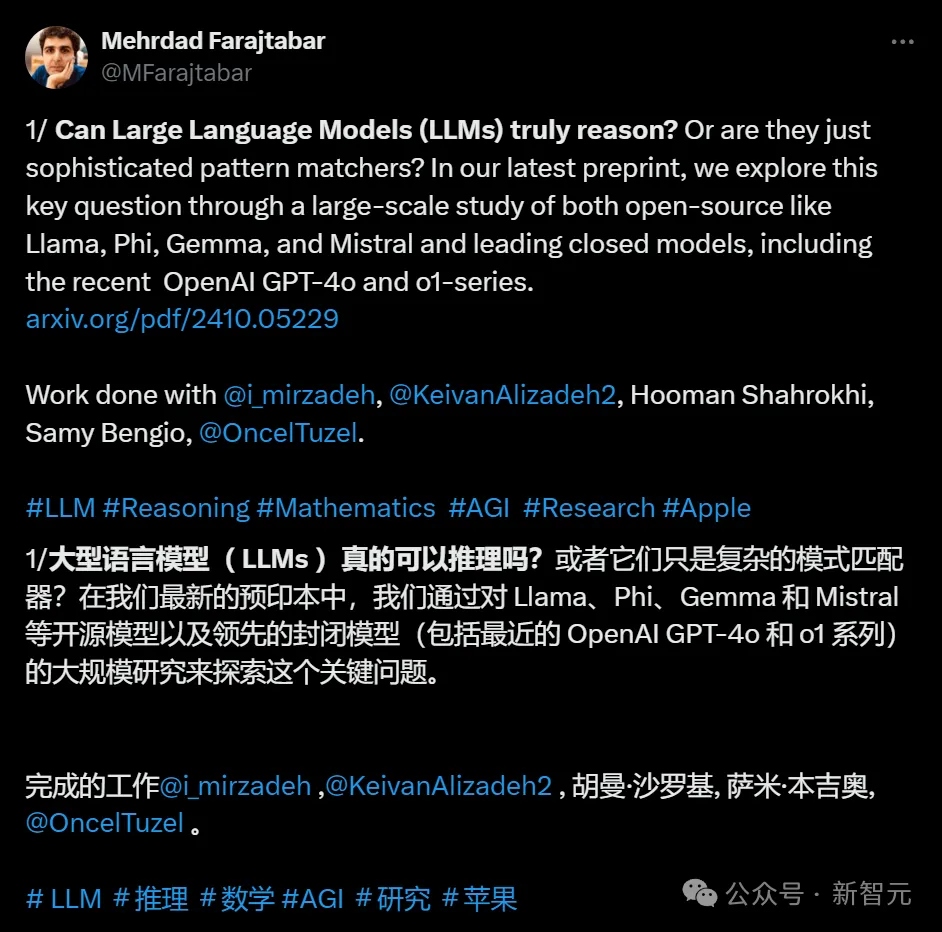
苹果研究者发现:无论是OpenAI GPT-4o和o1,还是Llama、Phi、Gemma和Mistral等开源模型,都未被发现任何形式推理的证据,而更像是复杂的模式匹配器。无独有偶,一项多位数乘法的研究也被抛出来,越来越多的证据证实:LLM不会推理!

最近,大模型训练遭恶意攻击事件已经刷屏了。就在刚刚,Anthropic也发布了一篇论文,探讨了前沿模型的巨大破坏力,他们发现:模型遇到危险任务时会隐藏真实能力,还会在代码库中巧妙地插入bug,躲过LLM和人类「检查官」的追踪!

虽然数据有限,但AI性能不会停滞不前,我们当前的算法还没有从我们拥有的数据中最大限度地提取信息,还有更多的推论、推断和其他过程我们可以应用到我们当前的数据上,以提供更多的价值。

大型语言模型 (LLM) 在各种自然语言处理和推理任务中表现出卓越的能力,某些应用场景甚至超越了人类的表现。然而,这类模型在最基础的算术问题的表现上却不尽如人意。