
谷歌最强开源模型Gemma 2发布,270亿参数奇袭Llama 3,单张A100可全精度推理
谷歌最强开源模型Gemma 2发布,270亿参数奇袭Llama 3,单张A100可全精度推理可在单张A100/H100 GPU或TPU主机上高效运行全精度推理。
来自主题: AI资讯
7768 点击 2024-06-29 11:32
 搜索
搜索
可在单张A100/H100 GPU或TPU主机上高效运行全精度推理。

性能翻倍的Gemma 2, 让同量级的Llama3怎么玩?
谷歌开源模型Gemma 2开放了! 虽然前段时间Google I/O大会上,Gemma 2开源的消息就已经被放出,但谷歌还留了个小惊喜—— 除27B模型外,还有一个更轻的9B版本。 DeepMind创始人哈萨比斯表示,27B参数规模下,Gemma 2提供了同类模型最强性能,甚至还能与其两倍大的模型竞争。
如何无痛玩转Llama 3,这个手把手教程一看就会!80亿参数推理单卡半分钟速成,微调700亿参数仅用4卡近半小时训完,还有100元代金券免费薅。
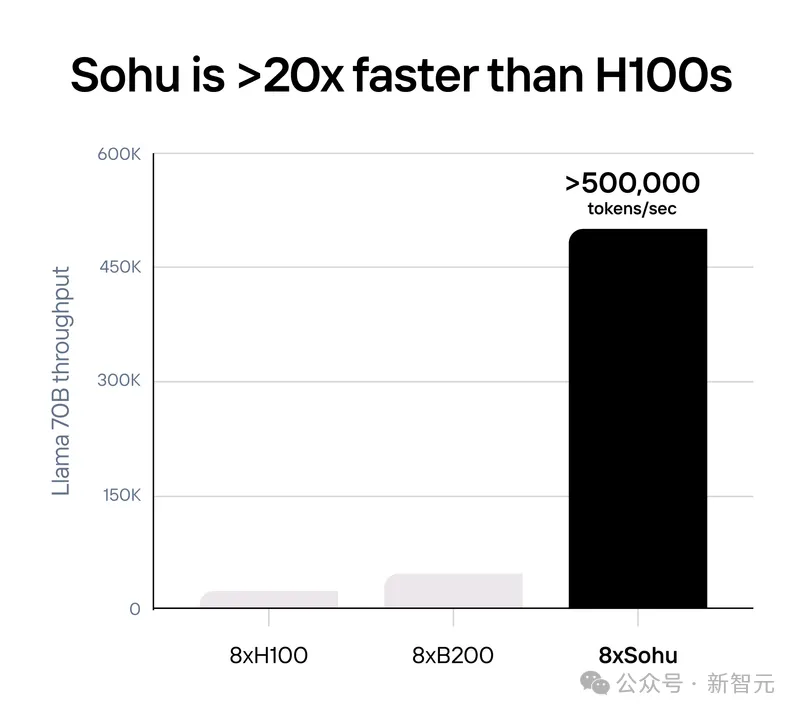
史上最快Transformer芯片诞生了!用 Etched chip 跑Llama 70B,推理性能已超B200十倍,超H100二十倍!刚刚,几位00后小哥从哈佛辍学后成立的公司Etached,宣布再融资1.2亿美元。

近日,一篇出自中国团队之手的AI论文在外网引发热议。论文中,研究团队提出了Q*模型算法,帮助Llama-2-7b等小模型达到参数量比其大数十倍、甚至上百倍模型的推理能力,使模型性能迎来惊人提升。

是时候把数据Scale Down了!Llama 3揭示了这个可怕的事实:数据量从2T增加到15T,就能大力出奇迹,所以要想要有GPT-3到GPT-4的提升,下一代模型至少还要150T的数据。好在,最近有团队从CommonCrawl里洗出了240T数据——现在数据已经不缺了,但你有卡吗?

排名超过Llama-3-70B,英伟达Nemotron-4 340B问鼎竞技场最强开源模型!
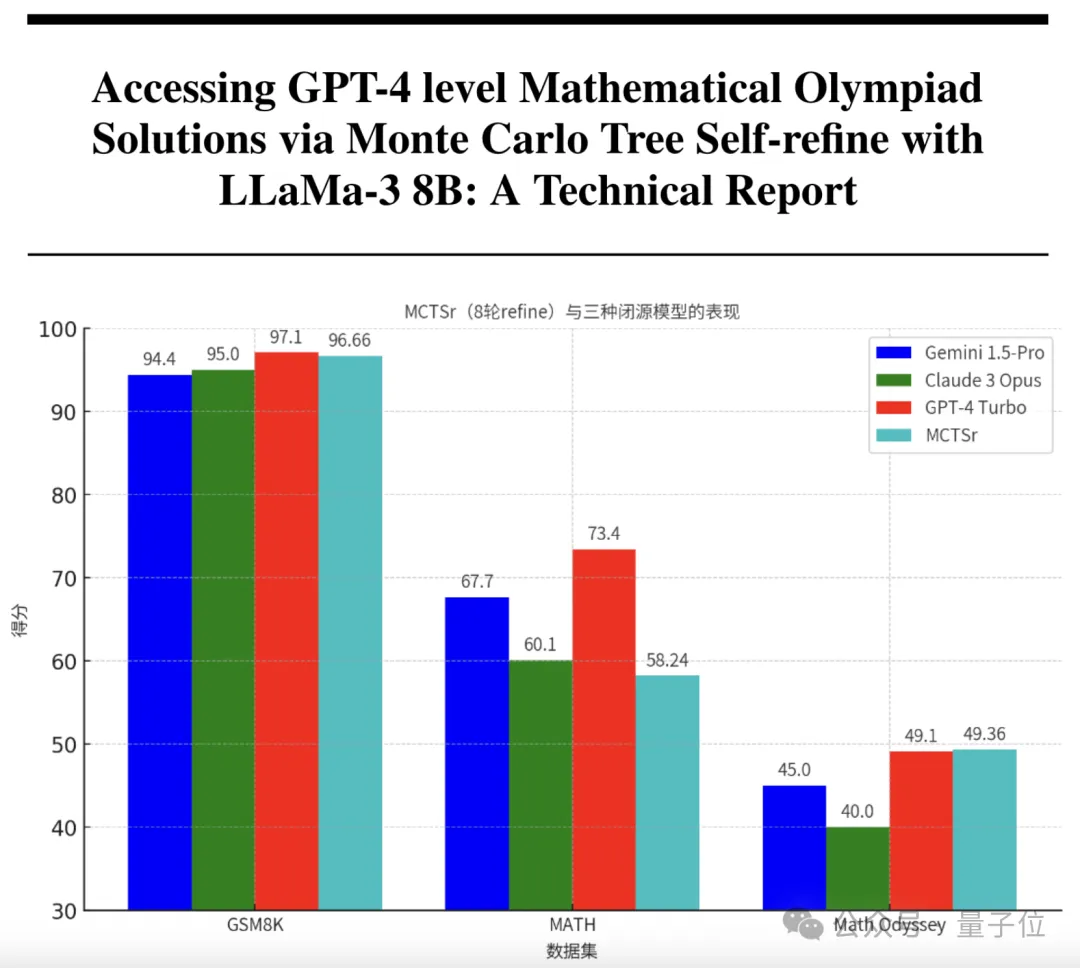
只要1/200的参数,就能让大模型拥有和GPT-4一样的数学能力? 来自复旦和上海AI实验室的研究团队,刚刚研发出了具有超强数学能力的模型。 它以Llama 3为基础,参数量只有8B,却在奥赛级别的题目上取得了比肩GPT-4的准确率。

通过算法层面的创新,未来大语言模型做数学题的水平会不断地提高。