Meta宣战OpenAI,发ChatGPT超强平替App,语音交互联动AI眼镜,Llama API免费用
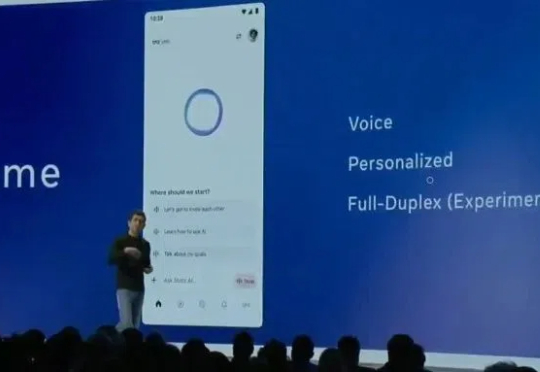
Meta宣战OpenAI,发ChatGPT超强平替App,语音交互联动AI眼镜,Llama API免费用今天,在首届LlamaCon开发者大会上,Meta正式发布了对标ChatGPT的智能助手Meta AI App,并宣布面向开发者提供官方Llama API服务的预览版本。Meta AI App是一款智能助手,基于Llama模型打造,可通过社交媒体账号了解用户偏好、记住上下文。与ChatGPT一样,Meta AI App支持语音和文本交互,并额外支持了全双工语音交互(Full-duplex,
来自主题: AI资讯
10574 点击 2025-04-30 10:10