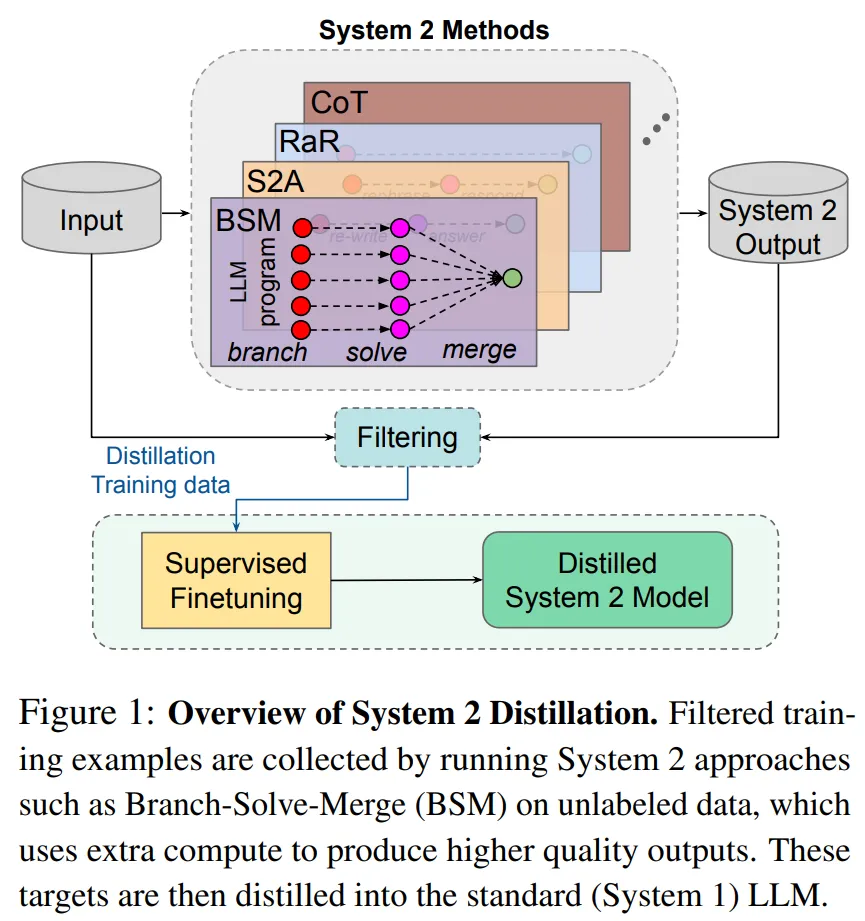
Meta开发System 2蒸馏技术,Llama 2对话模型任务准确率接近100%
Meta开发System 2蒸馏技术,Llama 2对话模型任务准确率接近100%研究者表示,如果 Sytem 2 蒸馏可以成为未来持续学习 AI 系统的重要特征,则可以进一步提升 System 2 表现不那么好的推理任务的性能。
来自主题: AI技术研报
10874 点击 2024-07-14 13:36
 搜索
搜索
研究者表示,如果 Sytem 2 蒸馏可以成为未来持续学习 AI 系统的重要特征,则可以进一步提升 System 2 表现不那么好的推理任务的性能。
《思考快与慢》中人类的两种思考方式,属实是被Meta给玩明白了。

评估大模型是否诚实的基准来了!

全球首个芯片设计开源大模型SemiKong正式发布,基于Llama 3微调而来,性能超越通用大模型。未来5年,SemiKong或将重塑价值5000亿美元的半导体行业。

来自佐治亚理工学院和英伟达的两名华人学者带队提出了名为RankRAG的微调框架,简化了原本需要多个模型的复杂的RAG流水线,用微调的方法交给同一个LLM完成,结果同时实现了模型在RAG任务上的性能提升。

基于 ChatGPT、LLAMA、Vicuna [1, 2, 3] 等大语言模型(Large Language Models,LLMs)的强大理解、生成和推理能力
只需Image Tokenizer,Llama也能做图像生成了,而且效果超过了扩散模型。

导读:时隔4个月上新的Gemma 2模型在LMSYS Chatbot Arena的排行上,以27B的参数击败了许多更大规模的模型,甚至超过了70B的Llama-3-Instruct,成为开源模型的性能第一!

可在单张A100/H100 GPU或TPU主机上高效运行全精度推理。

性能翻倍的Gemma 2, 让同量级的Llama3怎么玩?