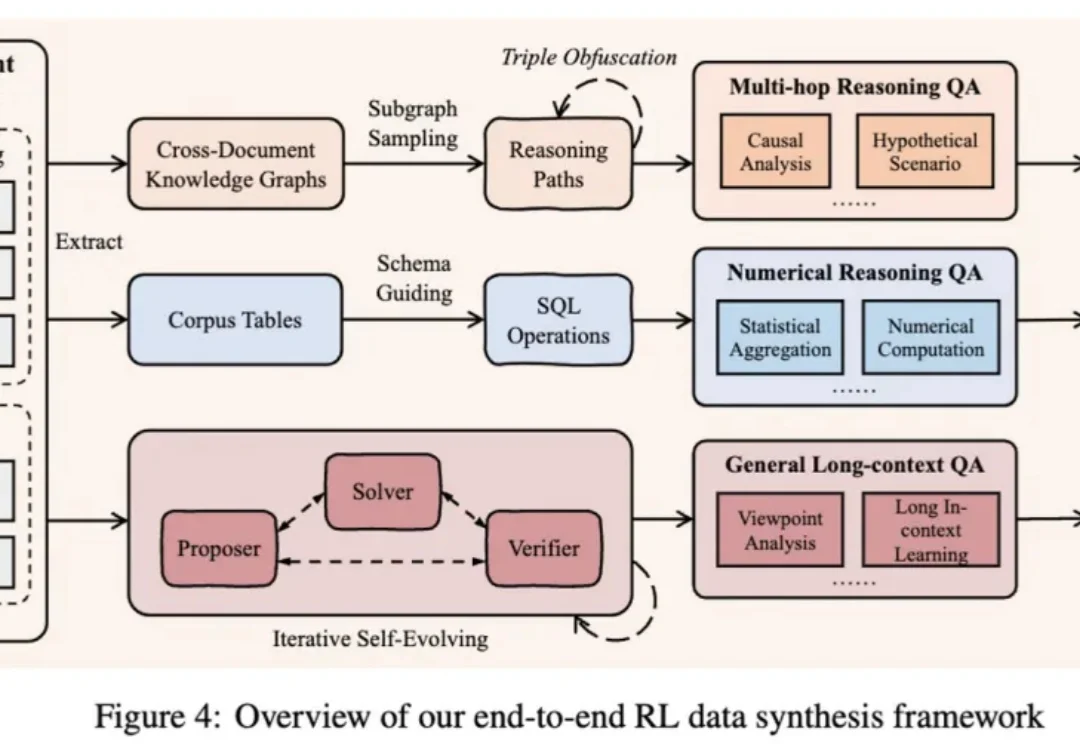
DeepSeek连更GitHub,华尔街回想起被支配的恐惧:“DeepSeek第二时刻”要来了
DeepSeek连更GitHub,华尔街回想起被支配的恐惧:“DeepSeek第二时刻”要来了DeepSeek员工节后一上班,美国AI圈又要抖三抖了(doge)。就从十几个小时前开始,DeepSeek的GitHub仓库突然一阵猛更新,Merge了一堆PR:维护者主要是mowentian——DeepSeekMoE等论文的署名作者之一Huang Panpan。他这一干活不要紧,大洋彼岸“V4来了???”的紧张神经,又被瞬间挑了起来。
来自主题: AI资讯
10504 点击 2026-02-25 10:37