

只要交钱,高中生也能发NeurIPS?港大教授怒批顶会变味
只要交钱,高中生也能发NeurIPS?港大教授怒批顶会变味在AI的浪潮下,学术研究正在被商业机构加速「量产化」,包装成明码标价的「入学筹码」。这不仅稀释了学术研究的含金量,挤占了学术资源,也可能导致学术通胀、学历贬值与更深层的信任危机。
来自主题: AI资讯
6885 点击 2025-12-08 15:14
在AI的浪潮下,学术研究正在被商业机构加速「量产化」,包装成明码标价的「入学筹码」。这不仅稀释了学术研究的含金量,挤占了学术资源,也可能导致学术通胀、学历贬值与更深层的信任危机。

谷歌DeepMind掌门人断言,2030年AGI必至!不过,在此之前,还差1-2个「Transformer级」核爆突破。恰在NeurIPS大会上,谷歌甩出下一代Transformer最强继任者——Titans架构。

两项关于大模型新架构的研究一口气在NeurIPS 2025上发布,通过“测试时训练”机制,能在推理阶段将上下文窗口扩展至200万token。两项新成果分别是:Titans:兼具RNN速度和Transformer性能的全新架构;MIRAS:Titans背后的核心理论框架。
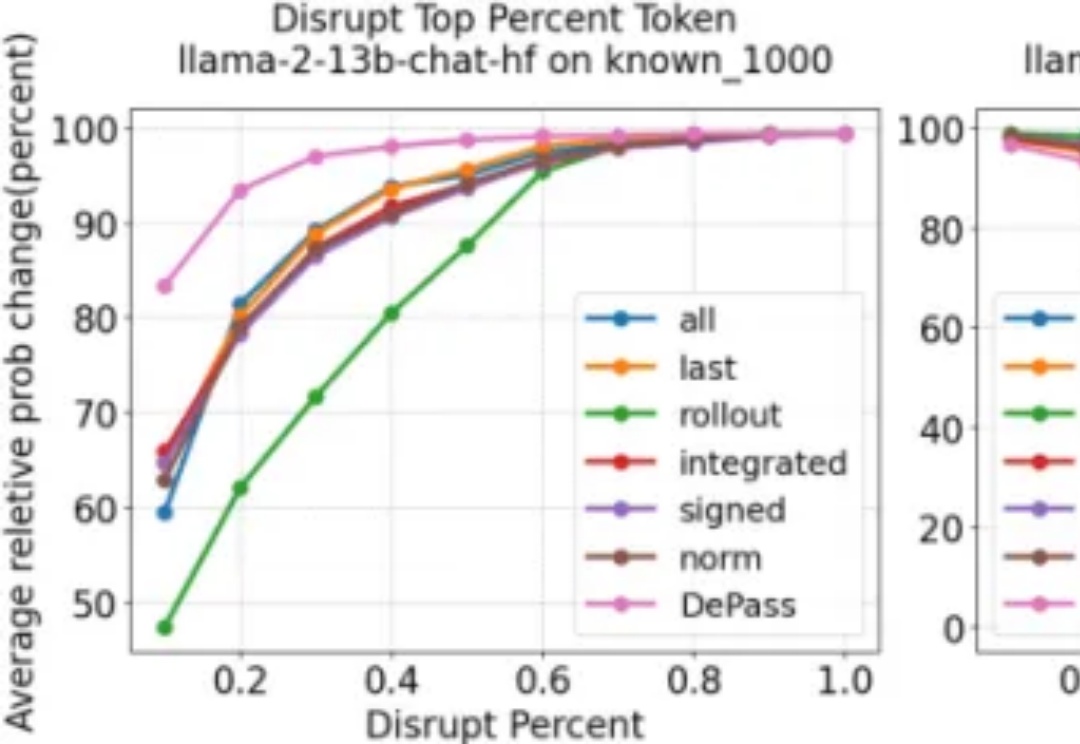
随着大型语言模型在各类任务中展现出卓越的生成与推理能力,如何将模型输出精确地追溯到其内部计算过程,已成为 AI 可解释性研究的重要方向。然而,现有方法往往计算代价高昂、难以揭示中间层的信息流动;同时,不同层面的归因(如 token、模型组件或表示子空间)通常依赖各自独立的特定方法,缺乏统一且高效的分析框架。
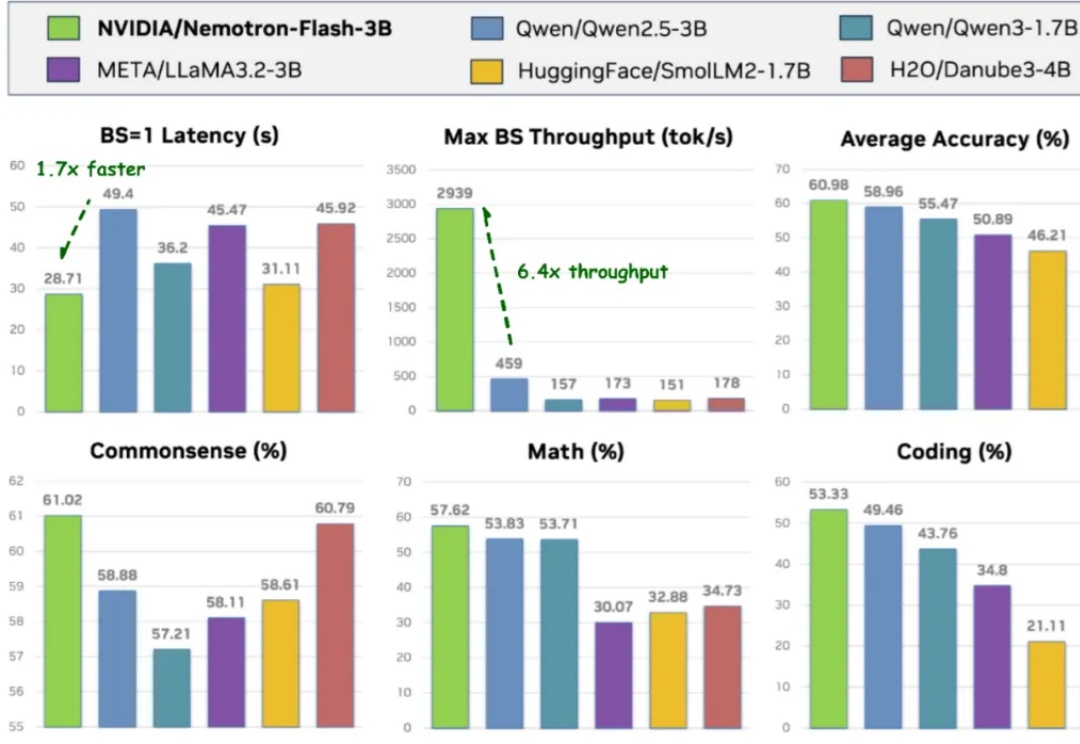
导读 过去两年,小语言模型(SLM)在业界备受关注:参数更少、结构更轻,理应在真实部署中 “更快”。但只要真正把它们跑在 GPU 上,结论往往令人意外 —— 小模型其实没有想象中那么快。

在大语言模型(LLM)的研究浪潮中,绝大多数工作都聚焦于优化模型的输出分布 —— 扩大模型规模、强化分布学习、优化奖励信号…… 然而,如何将这些输出分布真正转化为高质量的生成结果 —— 即解码(decoding)阶段,却没有得到足够的重视。

大模型推理的爆发,实际源于 scaling 范式的转变:从 train-time scaling 到 test-time scaling(TTS),即将更多的算力消耗部署在 inference 阶段。典型的实现是以 DeepSeek r1 为代表的 long CoT 方法:通过增加思维链的长度来获得答案精度的提升。那么 long CoT 是 TTS 的唯一实现吗?

李飞飞等顶尖学者投身的创业方向——世界模型是 AI 的下一站吗? 「AI 是人类自诞生以来,唯一担得起『日新月异』这个词的技术领域,」在机器之心近日举办的 NeurIPS 2025 论文分享会圆桌讨论上,茶思屋科技网站总编张群英的开场感叹引发了在场专家们的共鸣。

REG 是一种简单而有效的方法,仅通过引入一个 class token 便能大幅加速生成模型的训练收敛。其将基础视觉模型(如 DINOv2)的 class token 与 latent 在空间维度拼接后共同加噪训练,从而显著提升 Diffusion 的收敛速度与性能上限。在 ImageNet 256×256 上,

今天,NeurIPS 2025最佳论文出炉!4篇最佳论文,华人占多半,何恺明孙剑等人曾提出的Faster R-CNN获「时间检验奖」,实至名归。