
NeurIPS 2025放榜:阿里Qwen门控注意力获最佳论文,何恺明Faster R-CNN获时间检验奖
NeurIPS 2025放榜:阿里Qwen门控注意力获最佳论文,何恺明Faster R-CNN获时间检验奖刚刚,NeurIPS 2025最佳论文奖、时间检验奖出炉!
来自主题: AI技术研报
10536 点击 2025-11-27 14:39
刚刚,NeurIPS 2025最佳论文奖、时间检验奖出炉!
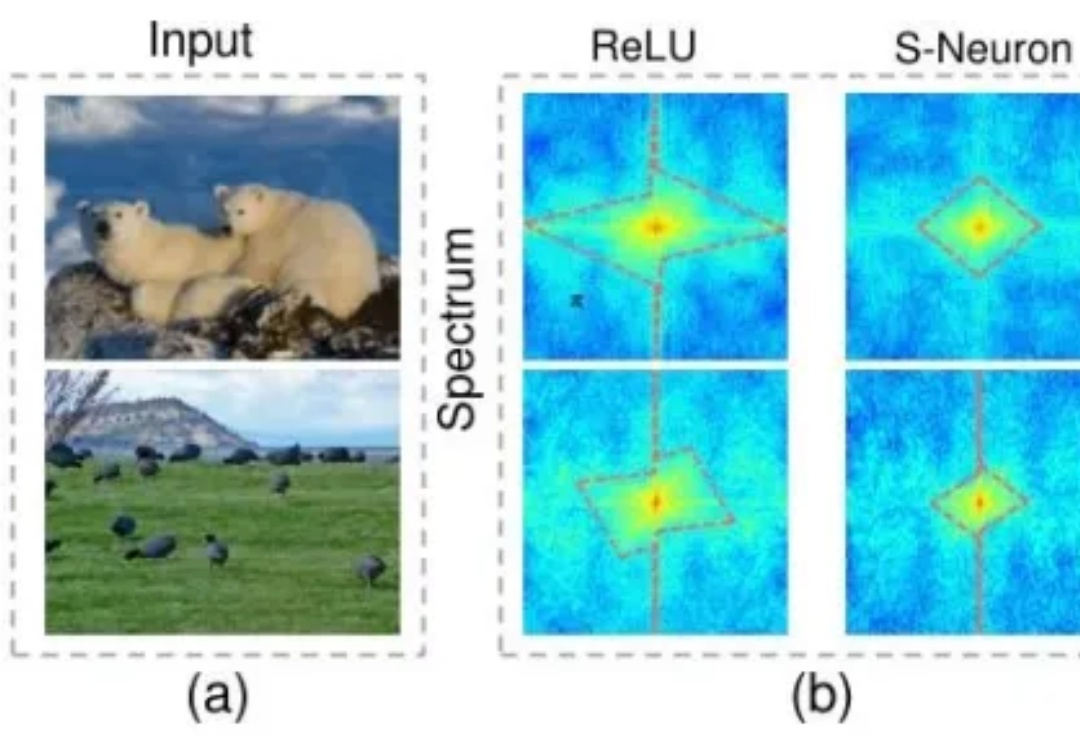
脉冲神经网络(SNN)不用再纠结二进制短板了。

当前,视频生成模型性能正在快速提升,尤其是基于Transformer架构的DiT模型,在视频生成领域的表现已经逐渐接近真实拍摄效果。然而,这些扩散模型也面临一个共同的瓶颈:推理时间长、算力成本高、生成速度难以提升。随着视频生成长度持续增加、分辨率不断提高,这个瓶颈正在成为影响视频创作体验的主要障碍之一。

图像与视频重光照(Relighting)技术在计算机视觉与图形学中备受关注,尤其在电影、游戏及增强现实等领域应用广泛。当前,基于扩散模型的方法能够生成多样且可控的光照效果,但其优化过程通常依赖于语义空间,而语义上的相似性无法保证视觉空间中的物理合理性,导致生成结果常出现高光过曝、阴影错位、遮挡关系错误等不合理现象。

扩散概率生成模型(Diffusion Models)已成为AIGC时代的重要基础,但其推理速度慢、训练与推理之间的差异大,以及优化困难,始终是制约其广泛应用的关键问题。近日,被NeurIPS 2025接收的一篇重磅论文EVODiff给出了全新解法:来自华南理工大学曾德炉教授「统计推断,数据科学与人工智能」研究团队跳出了传统的数值求解思维,首次从信息感知的推理视角,将去噪过程重构为实时熵减优化问题。
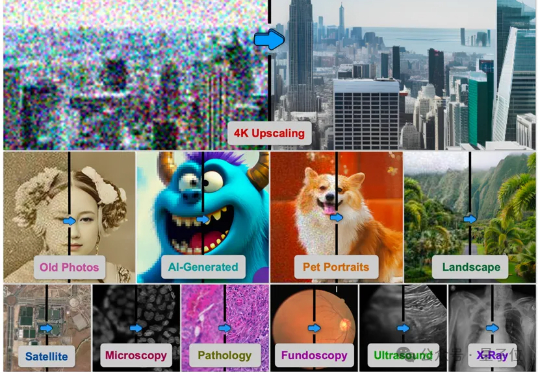
由德克萨斯A&M大学、斯坦福大学、Snap公司、CU Boulder大学、德克萨斯大学奥斯汀分校、加州理工大学、Topaz Labs以及加州大学Merced分校的研究者联合提出的基于AI智能体的方法4KAgent针对不同类型的图像以及需求对图像进行智能修复并放大到4K分辨率,带来优秀的视觉感知效果。该工作已被NeurIPS 2025接收。

在视觉处理任务中,Vision Transformers(ViTs)已发展成为主流架构。然而,近期研究表明,ViT 模型的密集特征中会出现部分与局部语义不一致的伪影(artifact),进而削弱模型在精细定位类任务中的性能表现。因此,如何在不耗费大量计算资源的前提下,保留 ViT 模型预训练核心信息并消除密集特征中的伪影?
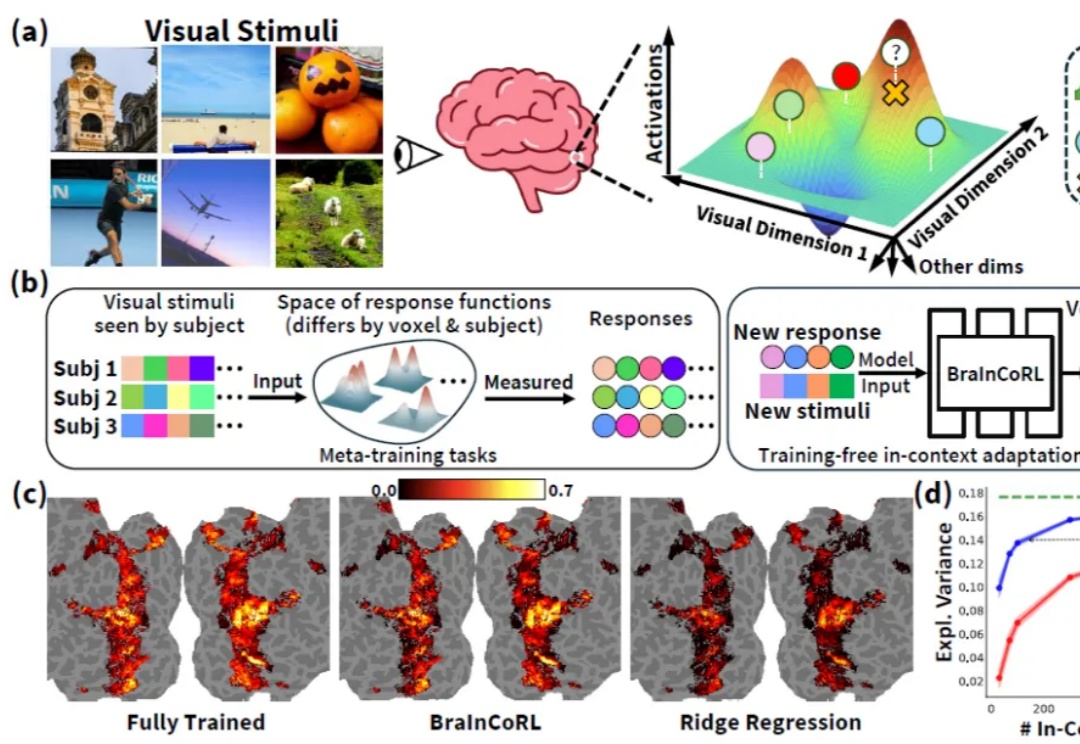
人类高级视觉皮层在个体间存在显著的功能差异,而构建大脑编码模型(brain encoding models)—— 即能够从视觉刺激(如图像)预测人脑神经响应的计算模型 —— 是理解人类视觉系统如何表征世界的关键。传统视觉编码模型通常需要为每个新被试采集大量数据(数千张图像对应的脑活动),成本高昂且难以推广。
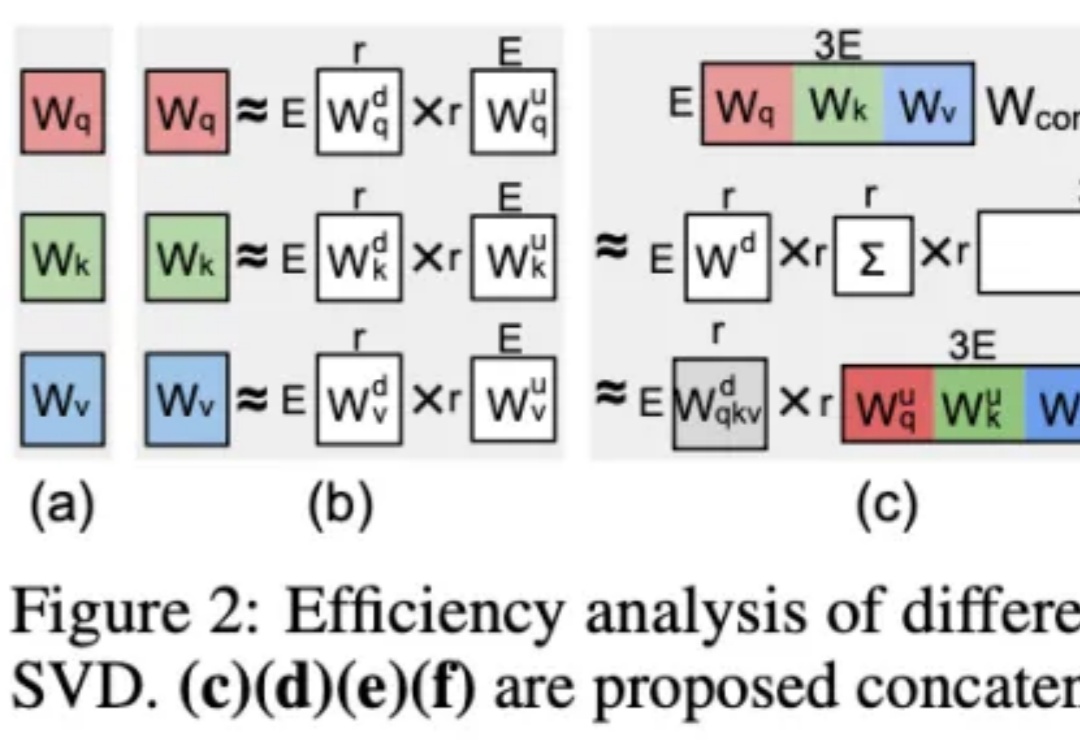
在多模态智能浪潮中,视觉语言模型(Vision-Language Models, VLM)已成为连接视觉理解与语言生成的核心引擎。从图像描述、视觉问答到 AI 教育和交互系统,它们让机器能够「看懂世界、说人话」。
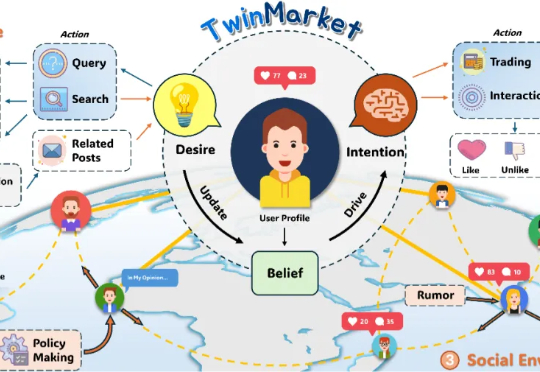
市场不是机器,而是人群;不是公式,而是故事。TwinMarket让AI学会讲述这些故事。 1994年,美国圣塔菲研究所(Santa Fe Institute)推出了一个野心勃勃的项目:人工股票市场(A