刚刚,翁荔博客上新:谨慎对待Scaling Law
刚刚,翁荔博客上新:谨慎对待Scaling Law刚刚,翁荔(Lilian Weng)的博客 Lil'Log 终于更新了!要知道,自从她联合创立了 Thinking Machines Lab 之后,她那让许多人受益良多的博客就鲜少更新了——距离她上一次更新,已经过去了 13 个月。
来自主题: AI技术研报
9312 点击 2026-06-26 11:14
 搜索
搜索
刚刚,翁荔(Lilian Weng)的博客 Lil'Log 终于更新了!要知道,自从她联合创立了 Thinking Machines Lab 之后,她那让许多人受益良多的博客就鲜少更新了——距离她上一次更新,已经过去了 13 个月。

Fable 5回来了?Claude安卓版的「模型选择器」中,消失一周的Fable 5意外现身。
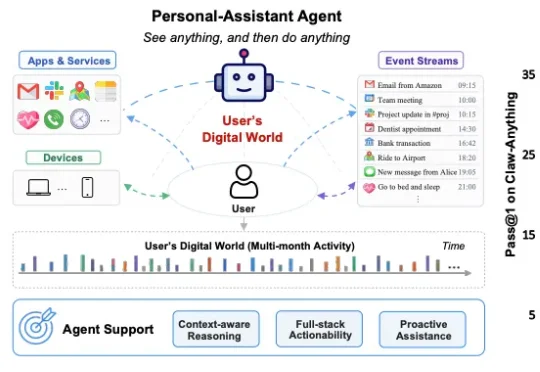
我们相信,常驻型 (always-on) AI 助理的下一次飞跃,不在于把某一个模型单点调得更聪明,而在于扩展智能体的上下文 (Scaling Agent Context)—— 不断拓宽助理能够持续 "感知 — 推理 — 执行" 的范围,作为生活连接器连接用户的信息孤岛,直到它能接管用户的整个数字世界。
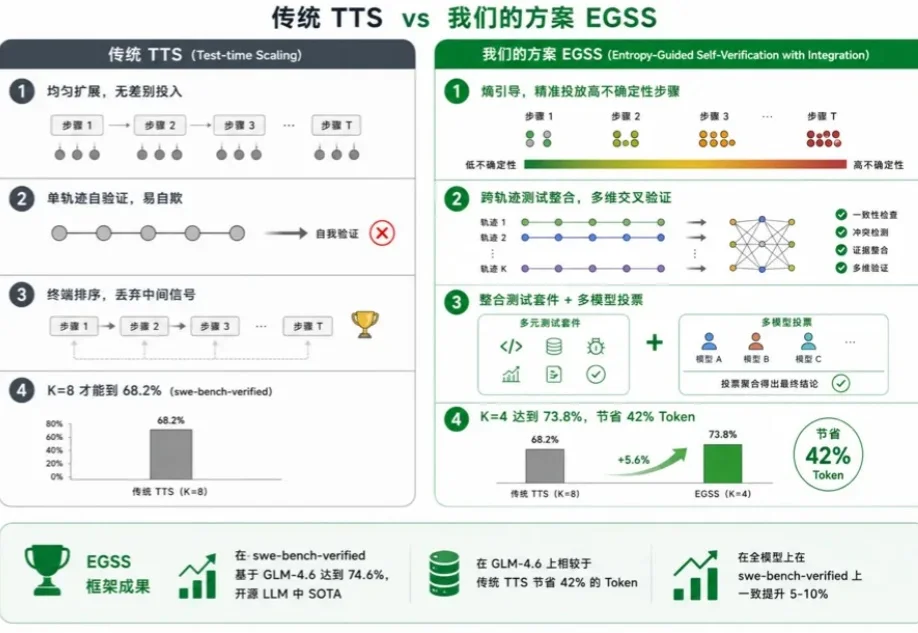
更聪明的计算远比更多的计算更有效。

具身智能现在面临的问题,和自动驾驶几年前的困境非常相似。
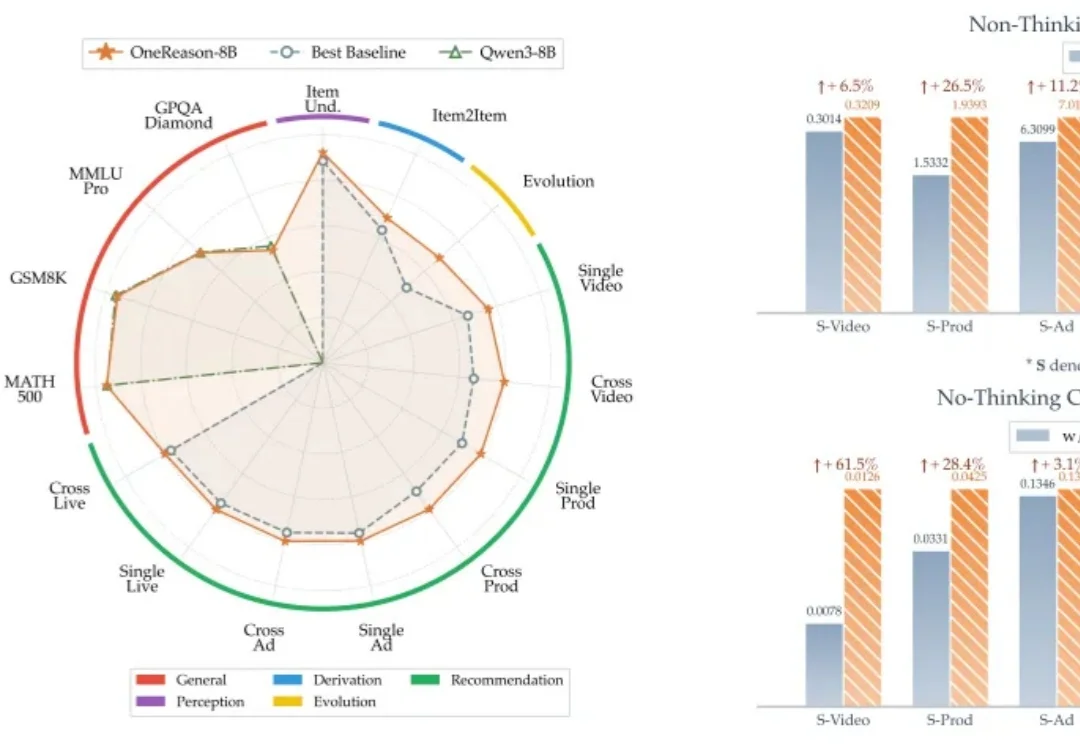
推荐系统的过去十年,本质是把 "用户 - 物料" 的统计共现挖到极致 —— 从协同过滤、深度模型,到生成式 OneRec 系列,每一代都在让 "记忆" 更精细、参数更大、序列更长,也让 Scaling 这件事在工业级推荐系统上跑通,持续释放算力红利。

Transformer 依托强大的建模能力和 Scaling 效率在推荐领域被广泛应用于超长序列建模和生成式推荐等方向,

过去的大模型 scaling law 通常回答的是:当模型参数量、数据量和训练计算量增加后,loss 会如何下降。

5 月 20 日,武汉光谷。极佳视界(GigaAI)在「家庭场景子品牌发布会暨物理通用智能技术发布会」上,给出了一份相对完整的答案。这场发布会公布了五件事:全球首个物理 AGI「双金字塔」体系;家庭场景子品牌「拾光 SeeLight」与首款家庭通用人形机器人「拾光 S1」同步亮相;国内首个真实家庭场景百台部署落地武汉,Q3 起规模化运营;

姜旭是少数完整参与过 OpenAI 大模型核心技术演进的华人创业者之一。2019 至 2023 年间,他经历了 GPT 系列能力爆发最关键的阶段,工作横跨底层训练 infra、大规模预训练、RLHF 对齐算法与数据构建等核心链路。