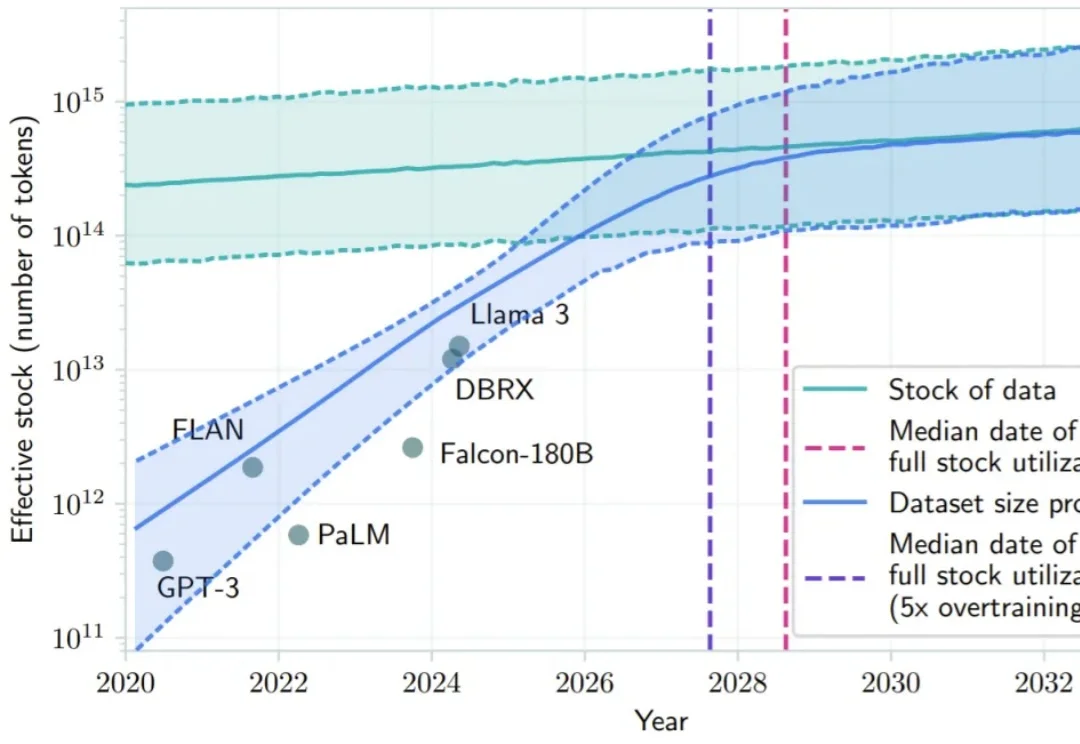
2026年,大模型训练的下半场属于「强化学习云」
2026年,大模型训练的下半场属于「强化学习云」2024 年底,硅谷和北京的茶水间里都在讨论同一个令人不安的话题:Scaling Law 似乎正在撞墙。
来自主题: AI技术研报
9591 点击 2026-01-12 15:13
 搜索
搜索
2024 年底,硅谷和北京的茶水间里都在讨论同一个令人不安的话题:Scaling Law 似乎正在撞墙。

在 Anthropic 成立五周年前夕,联合创始人兼总裁 Daniela Amodei 罕见接受了公开采访!

2026年,Scaling Law是否还能继续玩下去?对于这个问题,一篇来自DeepMind华人研究员的万字长文在社交网络火了:Scaling Law没死!算力依然就是正义,AGI才刚刚上路。

过去10年,AI大模型的技术本质,是把电力能源通过计算过程转化为可复用的智能。2026年,我们需要让AI模型在单位时间内「吃下」更多能源,并真正将其转化为智能。

最近,清华大学教授、智谱AI首席科学家唐杰发了一条长微博,总结了自己2025年对大模型进展的感悟。从预训练到中后训练、长尾场景的对齐能力,再到Agent、多模态和具身智能的发展,其中有不少亮点。

「高烧」三年后,AI行业终于冷静:Scaling红利即将耗尽,单纯堆参数绝非良药。但商汤已胸有成竹。

在代码大模型(Code LLMs)的预训练中,行业内长期存在一种惯性思维,即把所有编程语言的代码都视为同质化的文本数据,主要关注数据总量的堆叠。然而,现代软件开发本质上是多语言混合的,不同语言的语法特性、语料规模和应用场景差异巨大。

生成式AI狂奔三年,2025迎来架构创新的大年,三条脉络交织演进,伴随着Scaling law(规模定律)遇到天花板的争议,开始定义AI进化的新范式。
MiniMax海螺视频团队不藏了!首次开源就揭晓了一个困扰行业已久的问题的答案——为什么往第一阶段的视觉分词器里砸再多算力,也无法提升第二阶段的生成效果?翻译成大白话就是,虽然图像/视频生成模型的参数越做越大、算力越堆越猛,但用户实际体验下来总有一种微妙的感受——这些庞大的投入与产出似乎不成正比,模型离完全真正可用总是差一段距离。

2025 年还有一周结束,年底,AI 视频圈又卷起来了。