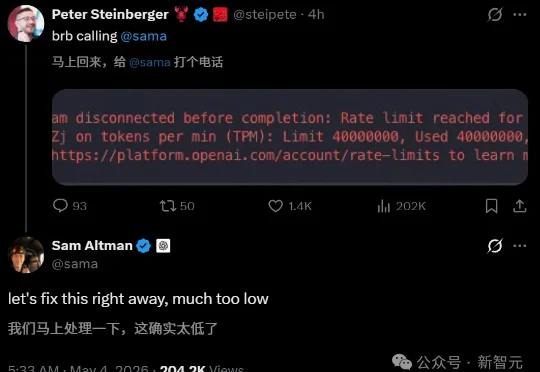
Claude Token榜:迪士尼「榜一大哥」9天46万次,Meta月烧60万亿
Claude Token榜:迪士尼「榜一大哥」9天46万次,Meta月烧60万亿迪士尼最近就做了一件「很不迪士尼」的事。它在内网上线了一块看板,名字直白得不像那个出品白雪公主的公司——「AI Adoption Dashboard」。看板上滚动着三个数字:每个员工调用AI的频率、请求次数、token消耗量。Claude是主要追踪对象。
来自主题: AI资讯
7889 点击 2026-05-05 10:04