Token 经济,人类史上「第一个叛徒」出现了
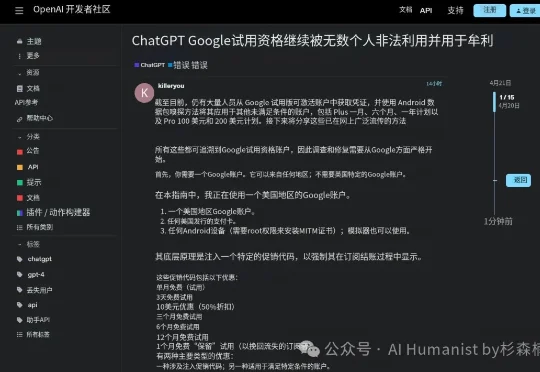
Token 经济,人类史上「第一个叛徒」出现了2026 年 4 月 21 日凌晨,OpenAI 开发者社区论坛上出现了一条帖子,Token 经济,人类史上「第一个叛徒」由此出现了:发帖的人叫 Killeryou。如果你混过中文技术社区,应该对这个名字不陌生。他过去两年一直活跃在 AI 工具的薅羊毛前线,属于那种既会写爬虫也会开店的角色。
来自主题: AI资讯
9900 点击 2026-04-27 15:19
 搜索
搜索
2026 年 4 月 21 日凌晨,OpenAI 开发者社区论坛上出现了一条帖子,Token 经济,人类史上「第一个叛徒」由此出现了:发帖的人叫 Killeryou。如果你混过中文技术社区,应该对这个名字不陌生。他过去两年一直活跃在 AI 工具的薅羊毛前线,属于那种既会写爬虫也会开店的角色。

昨晚,DeepSeek-V4又降价了,全系两款模型输入缓存命中的价格直接降至首发价格1/10。最新调价后,DeepSeek-V4-Flash每百万tokens输入(缓存命中)价格为0.02元,DeepSeek-V4-Pro为0.025元。
做过 AI 视频的都懂,除了 Seedance 2.0 本身的高定价,废片所烧掉的 token 算力也是一笔不小的开支。但在 Topview 平台,直接把这笔最大试错成本给重新定义了!热门视频生成模型 Seedance 2.0,加上最新的图片生成模型 Image 2,订阅 Ultra Plan,可不限量使用。

Meta内部搞了个AI用量排行榜「Claudeonomics」,8.5万员工拼消耗、冲段位、抢「Token传奇」称号。有人一个月烧掉200万美元,有人写外挂冲榜,有人挂着Agent睡觉也在跑——硅谷卷Token,已经卷到走火入魔了。

2026 年 3 月 24 日早上,我坐在 YC W26 batch Demo Day 的观众席里,听到第五家公司上台路演的时候,决定不再做笔记了。 不是不重要,而是我意识到,自己记下来的这些东西,可能下个月就过时了。

最新消息是,DeepSeek V4 Pro 2.5折的大力度优惠来啦!官方API文档显示,DeepSeek-V4-Pro模型API限时2.5折优惠,优惠期截至2026年5月5日。 具体是这样: 1️⃣百万tokens输入(缓存命中)折后0.25元(原价1元); 2️⃣百万tokens输入(缓存未命中)折后3元(原价12元); 3️⃣百万tokens输出折后6元(原价24元)。
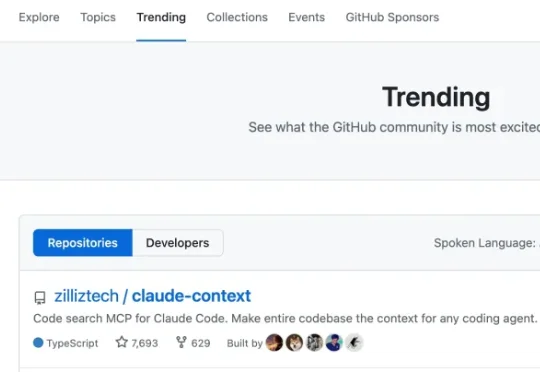
欢迎大家尝试前不久GitHub的日榜榜首项目——Claude Context。通过在AI coding场景引入混合检索,Claude Context相比使用grep的原生 Claude Code 能大幅提升检索精度和效率,减少约 40% 的 不必要Token 消耗。

阶跃星辰今日发布新一代自动语音识别模型StepAudio 2.5 ASR。该模型面向语音转写与长音频处理场景,在架构上引入Multi-Token Prediction(多Token预测)以提升推理效率,并通过扩展上下文窗口强化长内容识别能力。

几乎所有 Transformer 都在做一件反常的事:把大量注意力集中到少数几个特定 Token 上。这不是 bug,而是 Transformer 固有的「注意力汇聚」(Attention Sink)。首篇系统性综述,带你从利用、理解到消除,全面掌握这一核心现象。
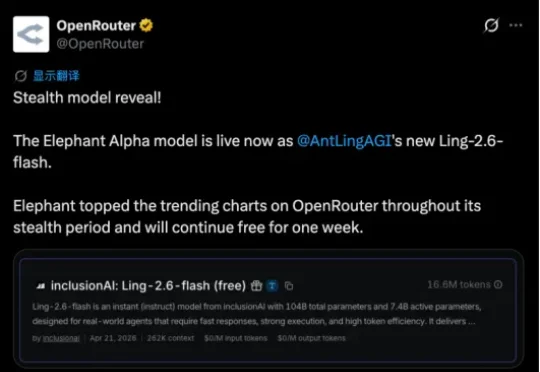
4月22日,蚂蚁百灵正式推出Ling-2.6-flash Instruct模型。该模型总参数量为104B,激活参数仅7.4B,核心主打高“Token 效率(Token Efficiency)”。API定价方面,Ling-2.6-flash输入每百万tokens定价0.1美元,输出 0.3 美元。目前,Ling-2.6-flash API已在OpenRouter及百灵tbox平台上线。