
建议六小虎合并,实现China AGI
建议六小虎合并,实现China AGI昨天我在沈阳大街遗址和刀哥握手了,很开心,今天来锐评一下智谱和MiniMax的IPO。
来自主题: AI资讯
9038 点击 2026-01-05 15:29
 搜索
搜索
昨天我在沈阳大街遗址和刀哥握手了,很开心,今天来锐评一下智谱和MiniMax的IPO。

MiniMax今起招股,作价461亿港元,拟募资超6亿美元。预计将于1月9日正式挂牌上市,代号00100。

MiniMax 启动了上市进程:今天公开发售正式启动,预计将于 1 月 9 日以 0100 为股票代码正式登陆港股资本市场。根据招股书披露的核心细节,MiniMax 本次 IPO 拟发行 25,389,220 股,定价区间为 151 至 165 港元/股,在不考虑发售量调整权及超额配股权行使的情况下,发行估值将介于 461.23 亿港元至 503.99 亿港元之间。

第一批AI大模型公司上市潮来了,先冲线的两家公司MiniMax、智谱揭开了自己的底牌。
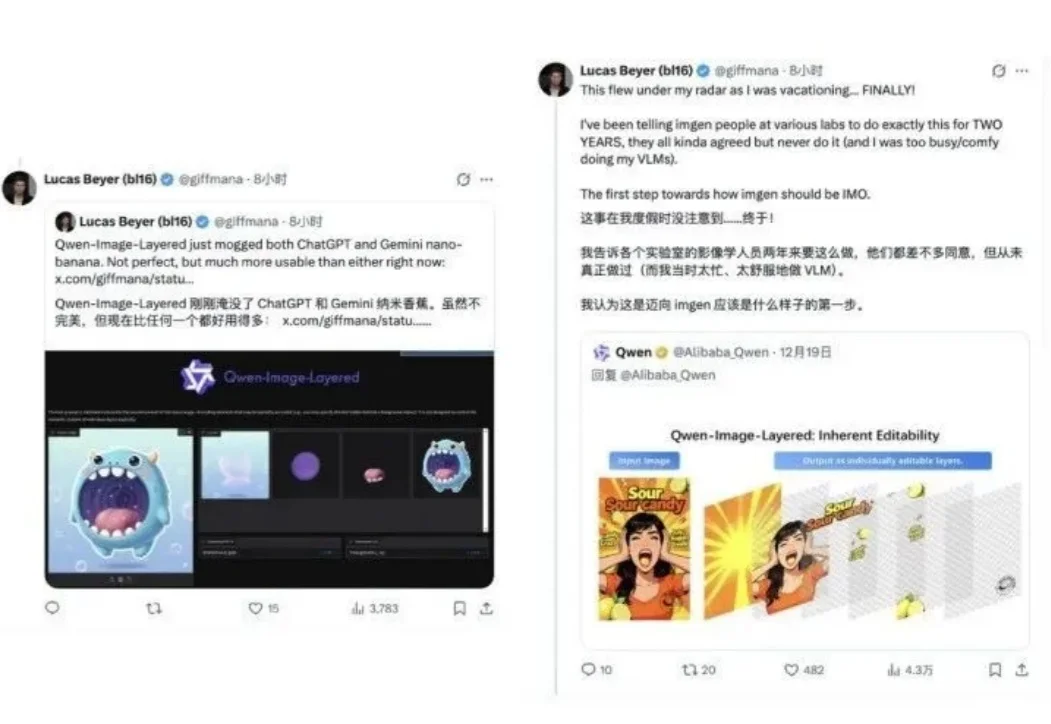
太香了太香了,妥妥完爆ChatGPT和Nano Banana!
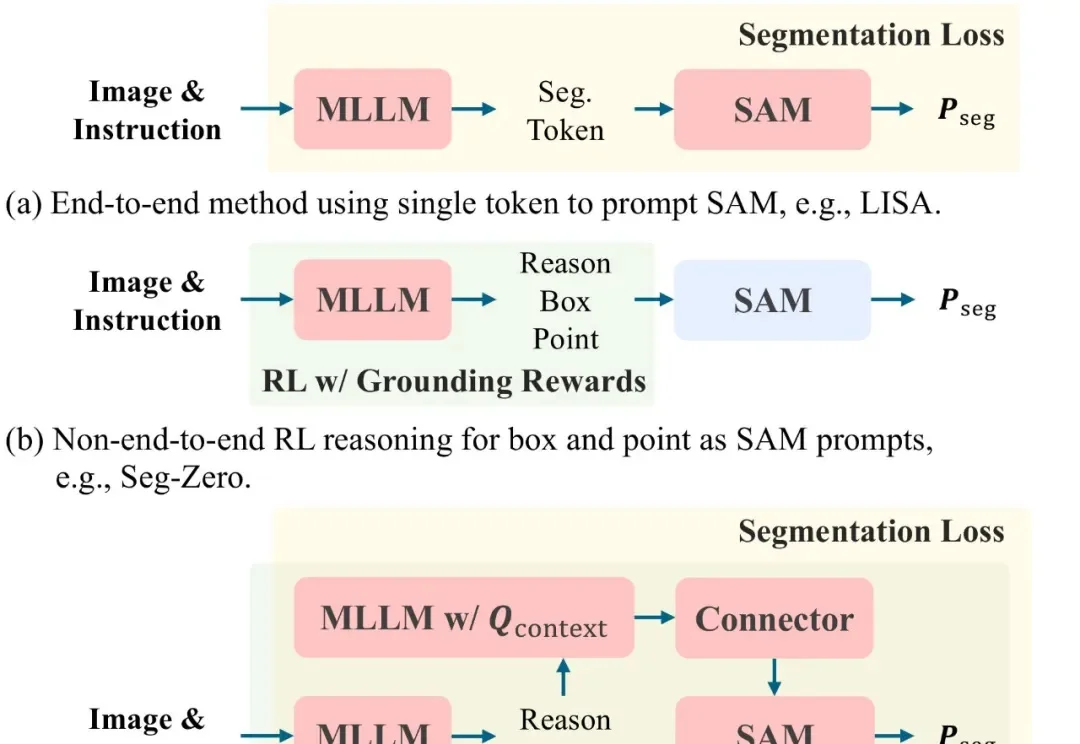
文本提示图像分割(Text-prompted image segmentation)是实现精细化视觉理解的关键技术,在人机交互、具身智能及机器人等前沿领域具有重大的战略意义。这项技术使机器能够根据自然语言指令,在复杂的视觉场景中定位并分割出任意目标。
上周我还在折腾各种图片、视频生成模型,这周又到了编程周。前天MiniMax丢出了个在编程界绝对有分量的模型:MiniMax-M2.1。然后发现就在刚才已经开源了:

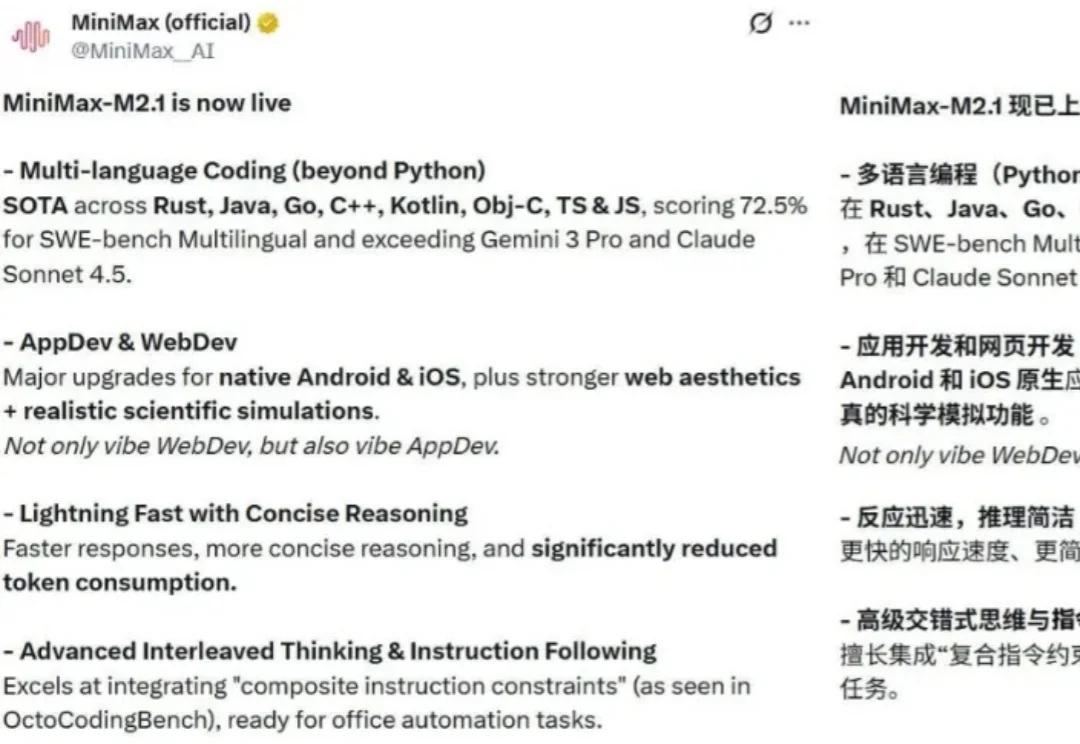
前脚刚听完罗永浩和 MiniMax 创始人闫俊杰的超长播客,然后就看到 MiniMax M2.1 发布了。

刚刚,由SciMaster团队推出的AI机器学习专家ML-Master 2.0,基于国产开源大模型DeepSeek,在OpenAI权威基准测试MLE-bench中一举击败Google、Meta、微软等国际顶流,刷新全球SOTA,再次登顶!目前该功能已在SciMaster线上平台开放waiting list,欢迎申请体验。
这两天,中国 AI 行业关注的核心无疑是 MiniMax。