
对话 MiniMax 闫俊杰:M3、10X 计划、10T 模型、和智能的终局
对话 MiniMax 闫俊杰:M3、10X 计划、10T 模型、和智能的终局当智能逼近临界点。
来自主题: AI资讯
7576 点击 2026-06-16 14:16
 搜索
搜索
当智能逼近临界点。

我们在上周五开源了 MiniMax M3 模型权重,同步发布了 MSA(MiniMax Sparse Attention)技术论文。MSA 的架构设计让 M3 在长上下文下的计算成本大幅降低,论文中完整披露了架构与工程实现细节。
每一次技术范式的重大转换,都是旧秩序松动、新物种诞生的窗口期。
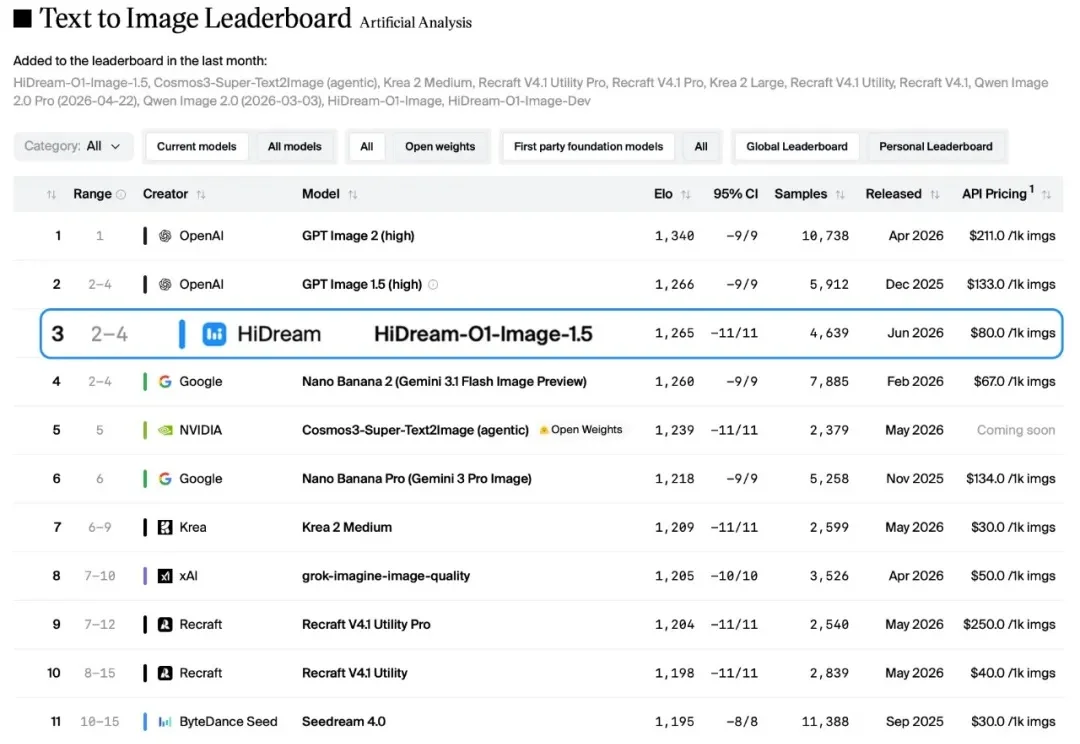
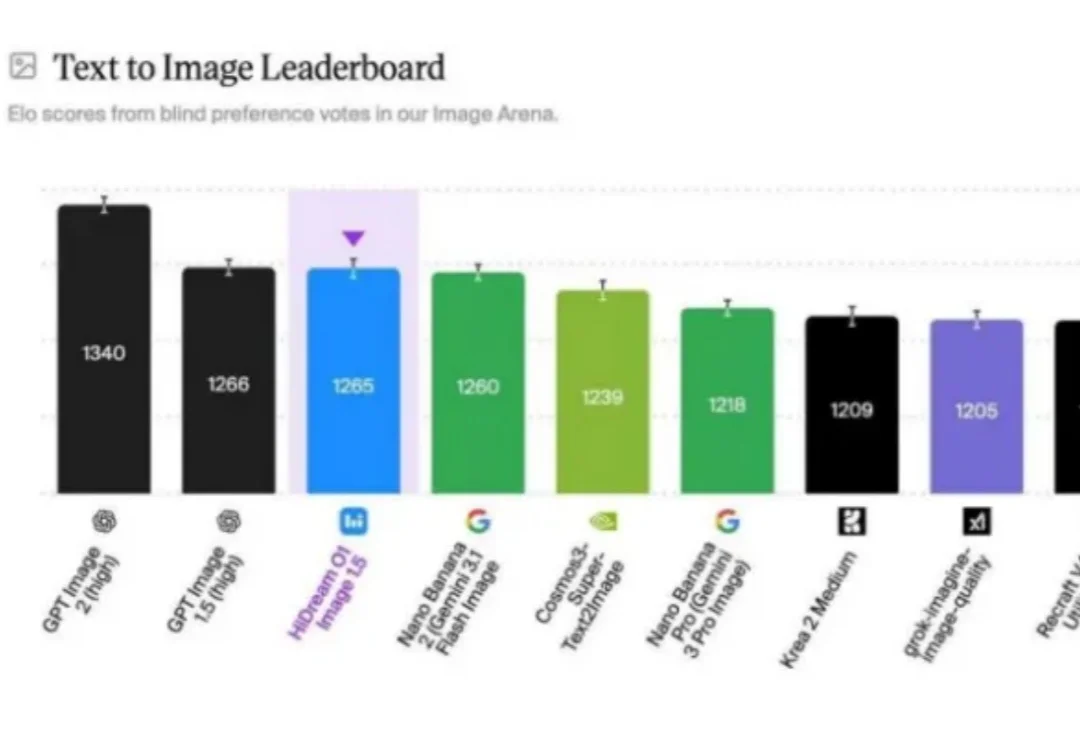
文生图的"慢思考",到底有没有用?
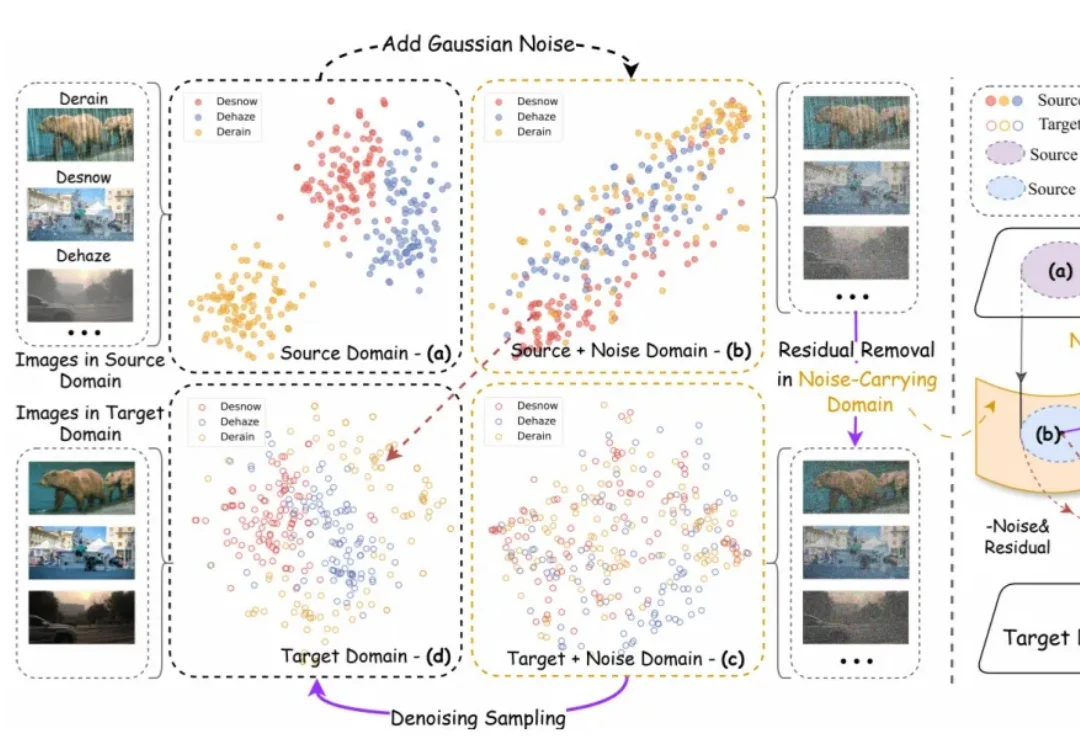
在图像到图像翻译(Image-to-Image Translation, I2I)这个任务上,扩散模型过去几年几乎形成了一套默认逻辑:先把输入图像和噪声混合,再一步步去噪,把目标图像 “还原” 出来。

近年来,文生图模型的能力快速提升。从 Stable Diffusion 到 FLUX、Qwen-Image,扩散模型已经能够生成高质量图像,也能处理越来越复杂的文本提示。
Agent 的世界,四月还是山雨欲来。五月尚未结束,已然血雨腥风。
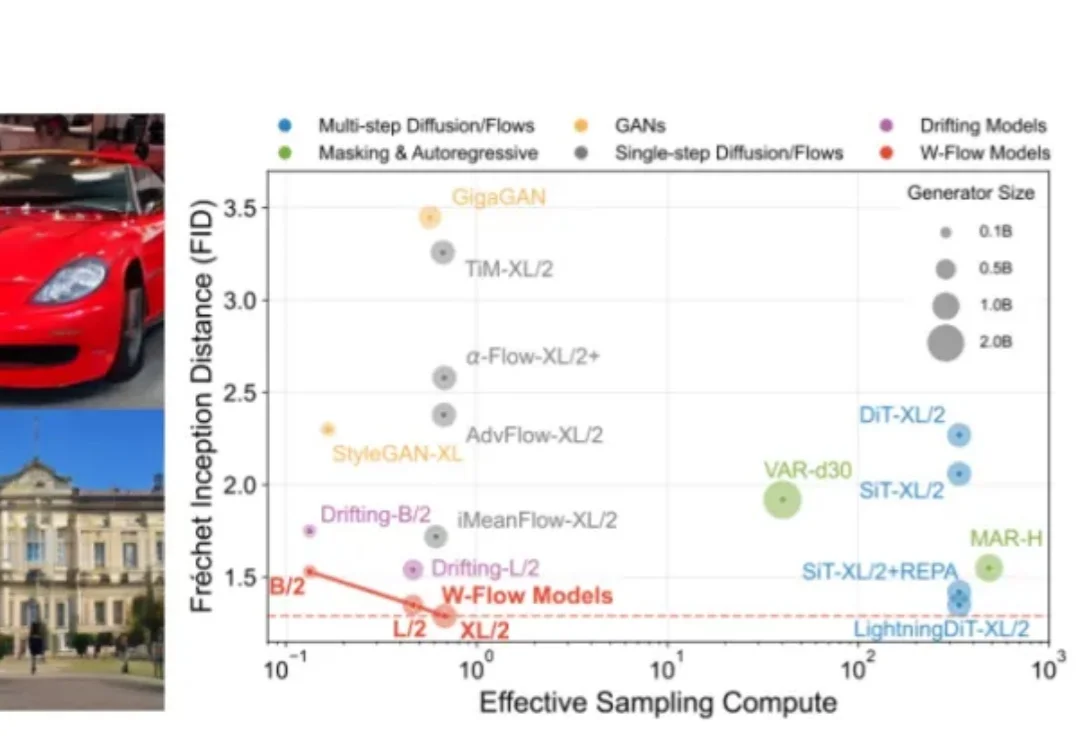
训练时让分布沿最优传输的 “下山方向” 走,推理时只需一次网络前向。W-Flow 把多步演化压进静态生成器,在 ImageNet 256×256 上刷新一步生成指标。

UiT 架构探路者,底牌还没亮。

前沿的 Coding 能力、1M 的上下文窗口,还有原生的多模态