把RLHF带给VLA模型!通过偏好对齐来优化机器人策略,代码已开源
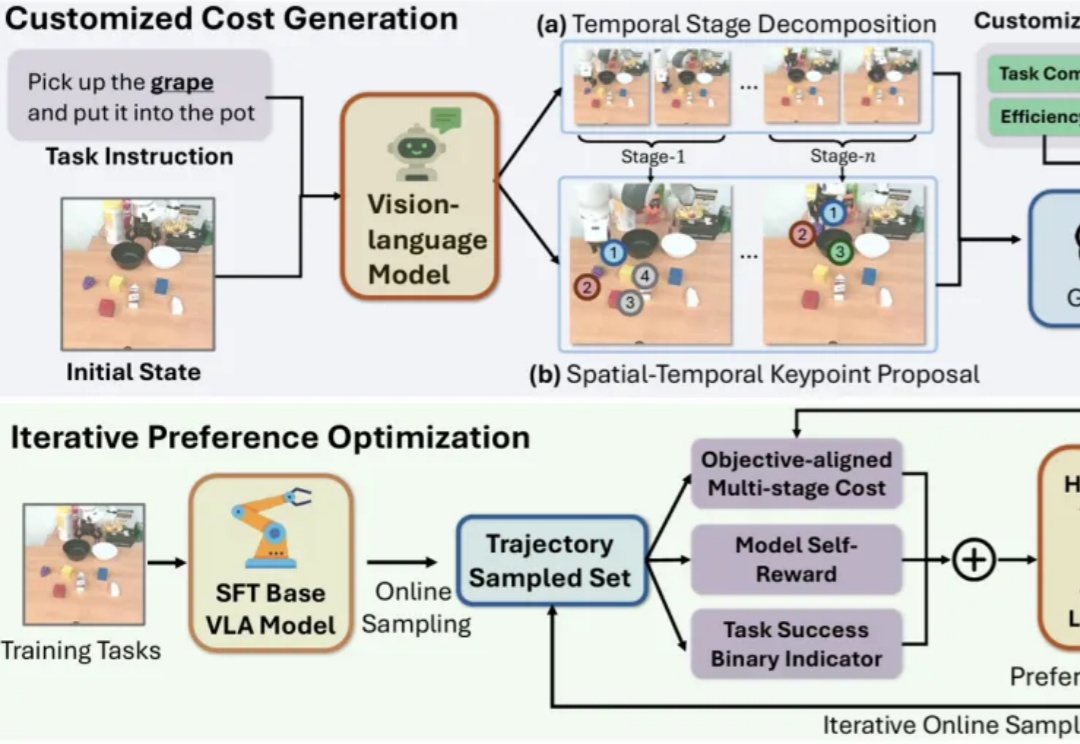
把RLHF带给VLA模型!通过偏好对齐来优化机器人策略,代码已开源近年来,视觉-语言-动作模型(Vision-Language-Action, VLA)在诸多机器人任务上取得了显著的进展,但它们仍面临一些关键问题,例如由于仅依赖从成功的执行轨迹中进行行为克隆,导致对新任务的泛化能力较差。
来自主题: AI技术研报
9233 点击 2024-12-28 11:41
 搜索
搜索
近年来,视觉-语言-动作模型(Vision-Language-Action, VLA)在诸多机器人任务上取得了显著的进展,但它们仍面临一些关键问题,例如由于仅依赖从成功的执行轨迹中进行行为克隆,导致对新任务的泛化能力较差。

AGI的定义,微软和OpenAI早就悄悄谋定了。 主要评判维度不看技术,而是收益。 The Information爆料,2023年双方达成秘密协定——OpenAI需要研发出能够带来1000亿美元收益的AI系统,才能被视为实现AGI。
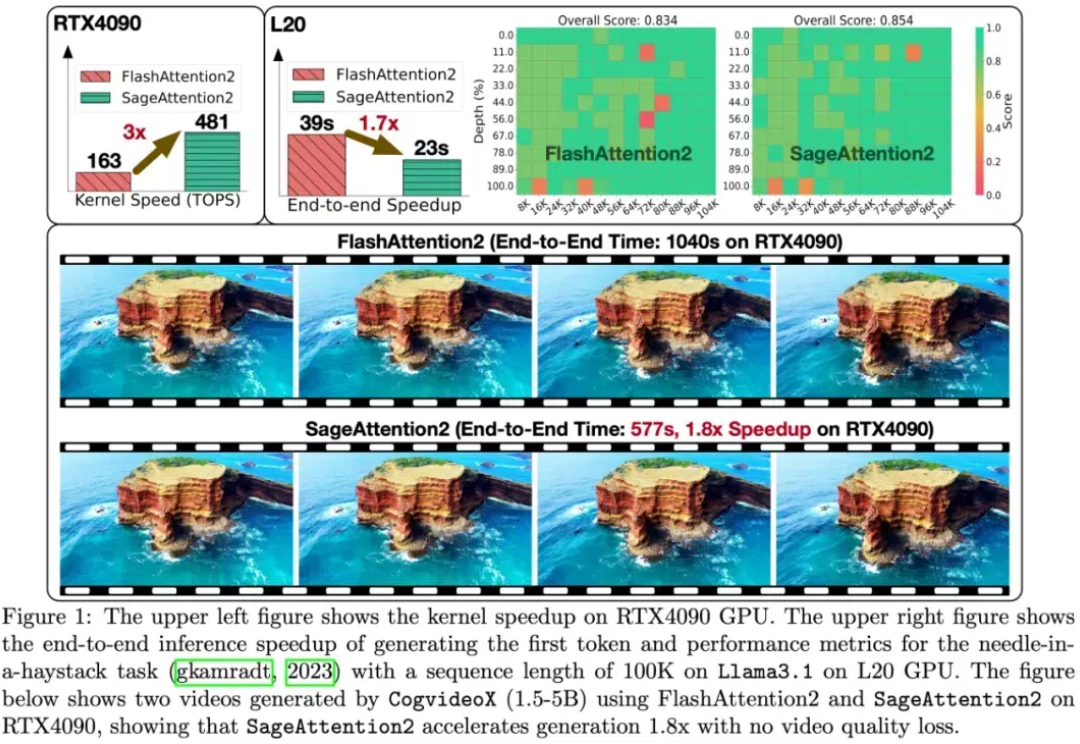
大模型中,线性层的低比特量化已经逐步落地。然而,对于注意力模块,目前几乎各个模型都还在用高精度(例如 FP16 或 FP32)的注意力运算进行训练和推理。并且,随着大型模型需要处理的序列长度不断增加,Attention(注意力运算)的时间开销逐渐成为主要开销。
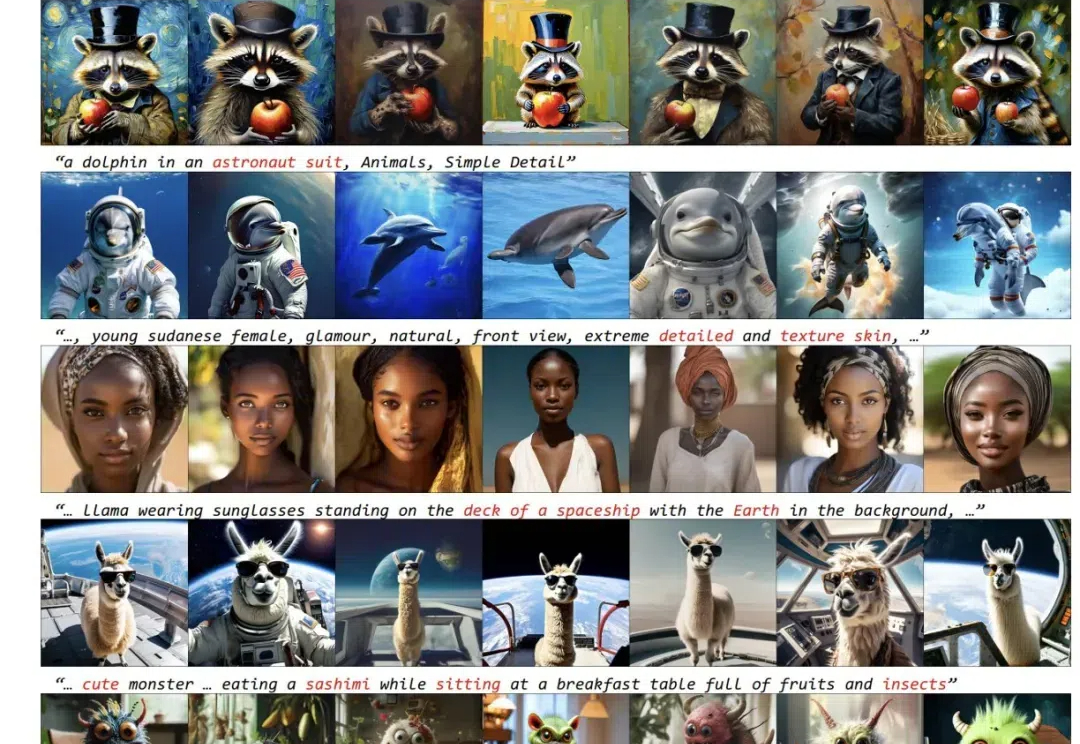
近些年来,以 Stable Diffusion 为代表的扩散模型为文生图(T2I)任务树立了新的标准,PixArt,LUMINA,Hunyuan-DiT 以及 Sana 等工作进一步提高了图像生成的质量和效率。然而,目前的这些文生图(T2I)扩散模型受限于模型尺寸和运行时间,仍然很难直接部署到移动设备上。
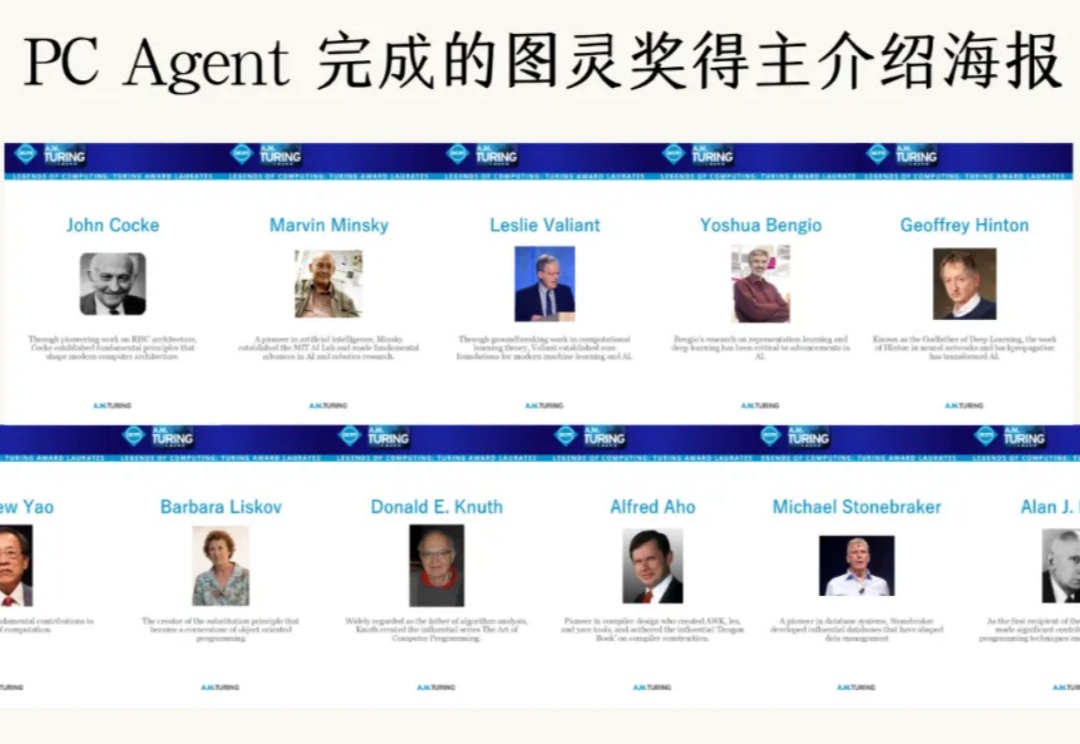
想象这样一个场景:深夜 11 点,你已经忙碌了一天,正准备休息,却想起明天早上还得分享一篇经典论文《Attention Is All You Need》,需要准备幻灯片。这时,你突然想到了自己的 AI 助手 —— PC Agent。

斯坦福HAI的研究员Michael Kratsios,被任命为白宫科技政策办公室主任,及特朗普政府的总统科技助理。从马斯克、AI沙皇到HAI研究员,这几轮任命彰显出:美国开始在国家层面推动科技政策发展,大力发展AI。

在大语言模型和 AIGC 的热潮下,科研人员对构建「视觉对话智能体」(Visual Chat Agent)展现出极大兴趣。其中,可实时交互的人像生成技术(Audio-Driven Real-Time Interactive Head Generation)是实现链路中极为关键的一环。

老iPhone又能再战一年。
从事客服行业的人,经常要应对巨大的心理压力。不仅要迅速处理客户提出的各种问题,还经常会遇到态度恶劣的“麻烦客户”,这往往让一整天的心情都变得糟糕透顶。结果,就是客服岗位的离职率和人员流动率居高不下,企业很难留住合适的人才。

OpenAI 代号为 Orion 的新 AI 项目遇到了一个又一个问题。