
35天,版本之子变路人甲:AI榜单太残酷!
35天,版本之子变路人甲:AI榜单太残酷!o1从榜首暴跌至#56,Claude 3 Opus坠入#139。LMSYS榜单揭示残酷真相:大模型的「霸主保质期」只有35天!这不是技术迭代,这是对所有应用层开发者的降维屠杀。
来自主题: AI资讯
7157 点击 2026-01-16 10:54
 搜索
搜索
o1从榜首暴跌至#56,Claude 3 Opus坠入#139。LMSYS榜单揭示残酷真相:大模型的「霸主保质期」只有35天!这不是技术迭代,这是对所有应用层开发者的降维屠杀。

继轻量级强化学习(RL)框架 slime 在社区中悄然流行并支持了包括 GLM-4.6 在内的大量 Post-training 流水线与 MoE 训练任务之后,LMSYS 团队正式推出 Miles——一个专为企业级大规模 MoE 训练及生产环境工作负载设计的强化学习框架。
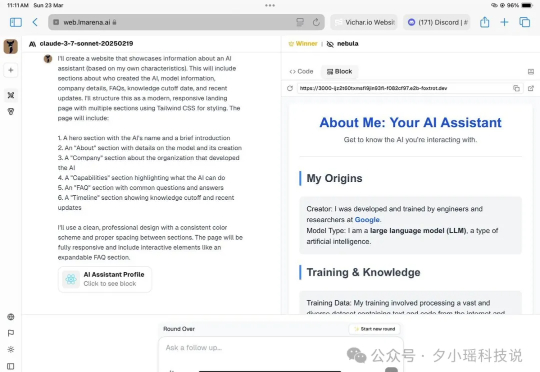
哎!最近推特上的网友在LMSYS Arena 发现了个泄漏的大模型 Nebula,效果据说特别好,打败了o1、o3mini、Claude3.7 Thinking等等模型:网友们通过询问和分析 API,发现这似乎是谷歌正在秘密演练的新推理模型!推测可能是 Google Gemini 2.0 Pro Thinking:

o1模型发布1周,lmsys的6k+投票就将o1-preview送上了排行榜榜首。同时,为了满足大家对模型「IOI金牌水平」的好奇心,OpenAI放出了o1测评时提交的所有代码。

今年 6 月底,谷歌开源了 9B、27B 版 Gemma 2 模型系列,并且自亮相以来,27B 版本迅速成为了大模型竞技场 LMSYS Chatbot Arena 中排名最高的开放模型之一,在真实对话任务中比其两倍规模以上的模型表现还要好。

导读:时隔4个月上新的Gemma 2模型在LMSYS Chatbot Arena的排行上,以27B的参数击败了许多更大规模的模型,甚至超过了70B的Llama-3-Instruct,成为开源模型的性能第一!

一直以来,UC伯克利团队的LMSYS大模型排行榜,深受AI圈欢迎。如今,最有实力的全新大模型排行榜SEAL诞生,得到AI大佬的转发。它最大的特点是在私有数据上,由专家严格评估,并随时间不断更新数据集和模型。

真正与GPT-4o齐头并进的国产大模型来了!刚刚,LMSYS揭开最新榜单,黑马Yi-Large在中文分榜上与GPT-4o并列第一,而在总榜上位列世界第七,紧追国际第一阵营,并登上了国内大模型盲测榜首。
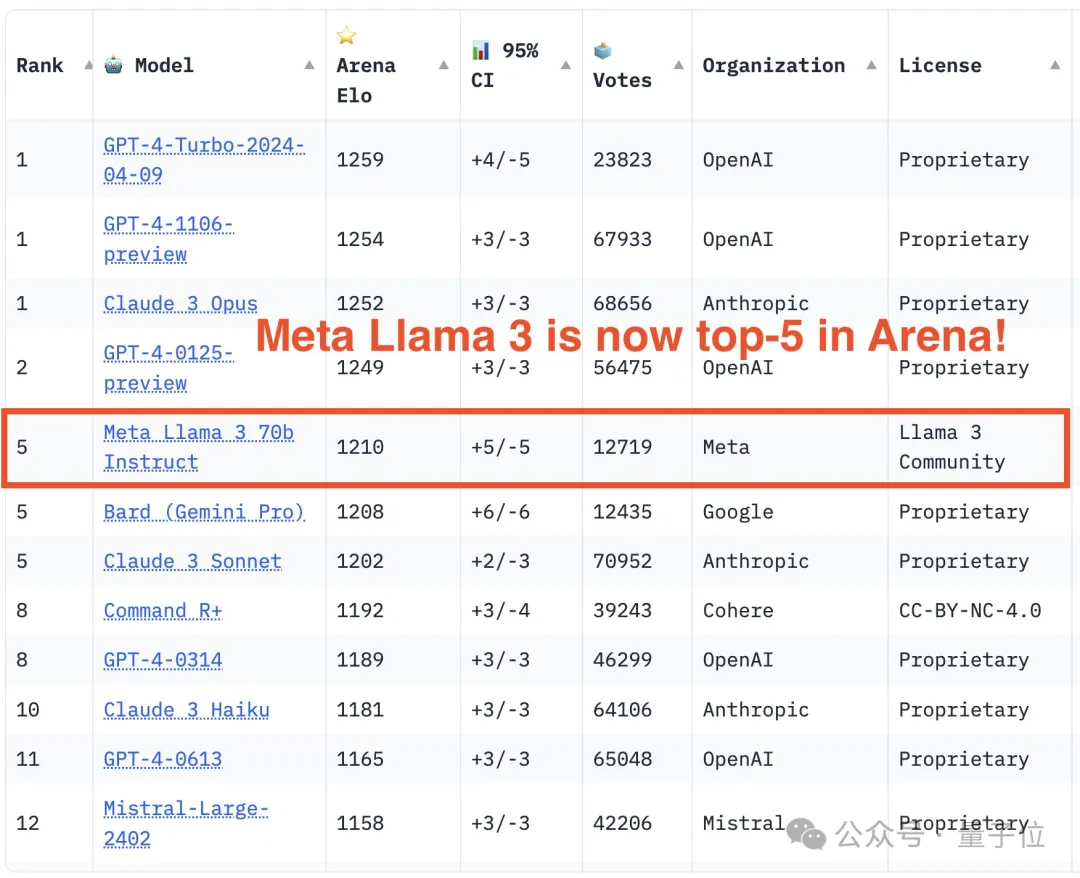
关于Llama 3,又有测试结果新鲜出炉—— 大模型评测社区LMSYS发布了一份大模型排行榜单,Llama 3位列第五,英文单项与GPT-4并列第一。