大模型如何泛化出多智能体推理能力?清华提出策略游戏自博弈方案MARSHAL
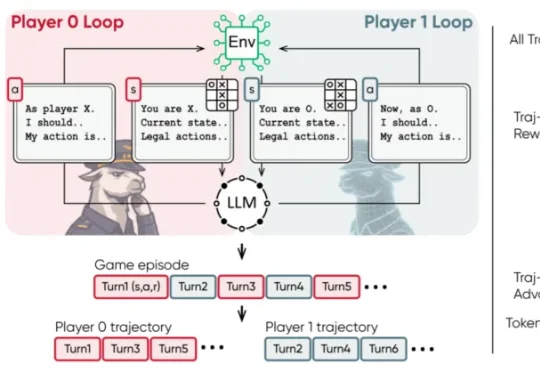
大模型如何泛化出多智能体推理能力?清华提出策略游戏自博弈方案MARSHAL近日,清华大学等机构的研究团队提出了 MARSHAL 框架。该框架利用强化学习,让大模型在策略游戏中进行自博弈(Self-Play)。实验表明,这种多轮、多智能体训练不仅提升了模型在游戏中的博弈决策水
来自主题: AI技术研报
8950 点击 2026-01-10 10:16
 搜索
搜索
近日,清华大学等机构的研究团队提出了 MARSHAL 框架。该框架利用强化学习,让大模型在策略游戏中进行自博弈(Self-Play)。实验表明,这种多轮、多智能体训练不仅提升了模型在游戏中的博弈决策水

当模型学会「左右互搏」的那一刻,平庸的模仿时代结束了,真正的硅基编程奇迹刚刚开始。

来⾃阿⾥巴巴夸克、北京⼤学、中⼭⼤学的研究者提出了⼀种新的解决⽅案:搜索自博弈 Search Self-play(SSP)⸺⼀种⾯向深度搜索 Agent 的⾃我博弈训练范式。其核⼼思路是:让⼀个模型同时扮演两个⻆⾊⸺「出题者」和「解题者」,它们在对抗训练中共同进化,使训练难度随着模型能⼒动态提升,最终形成⼀个⽆需⼈⼯标注的动态博弈⾃我进化过程。
Meta超级智能实验室(MSL)又被送上争议的风口浪尖了。

不用引入外部数据,通过自我博弈(Self-play)就能让预训练大模型学会推理?

o1 模型何以成为企业游戏规则的改变者?
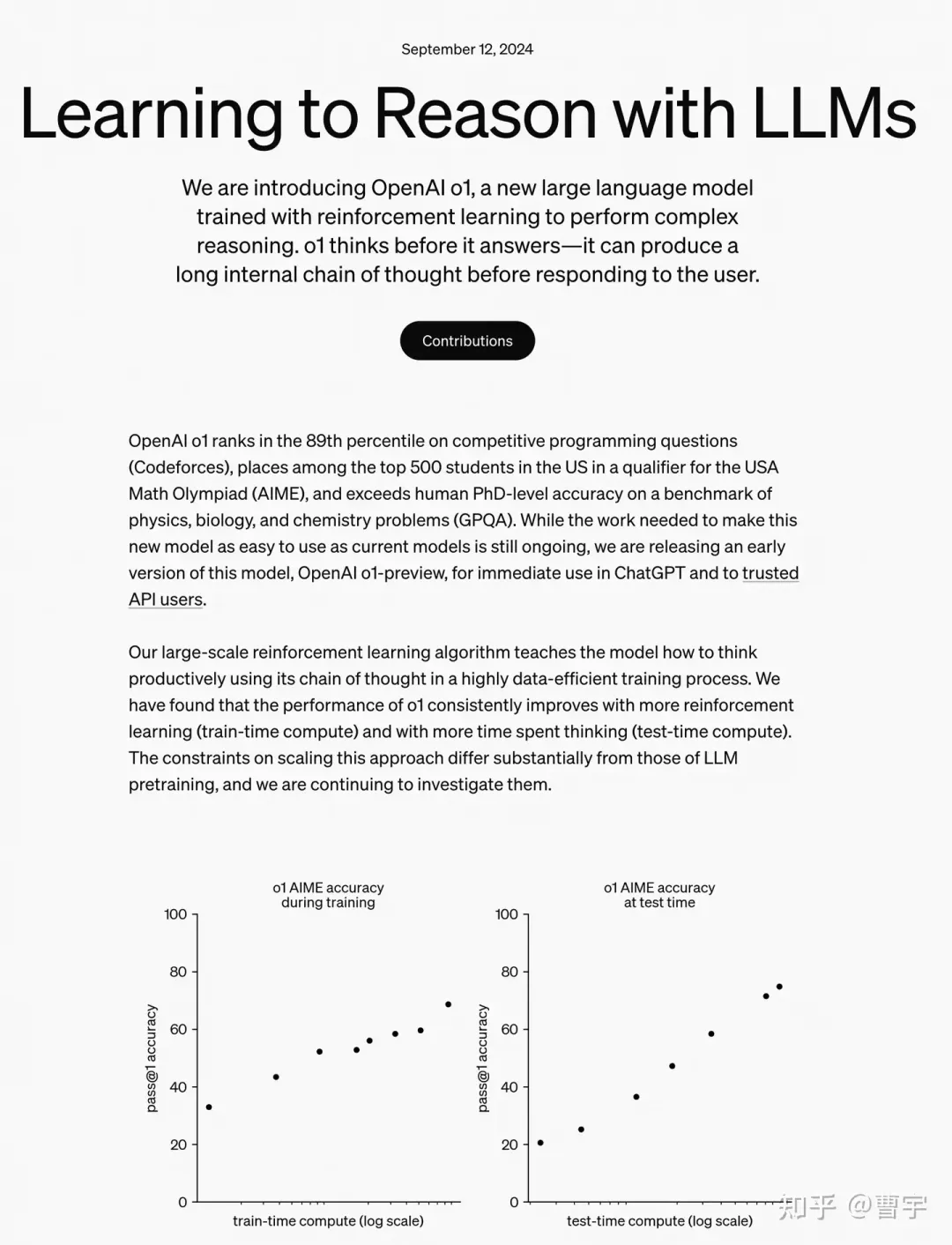
OpenAI的self-play RL新模型o1最近交卷,直接引爆了关于对于self-play的讨论。
Self-play RL 开启 AGI 下半场

本文作者来自于清华大学电子工程系,北京大学人工智能研究院、第四范式、腾讯和清华-伯克利深圳学院。其中第一作者张瑞泽为清华大学硕士,主要研究方向为博弈算法。通讯作者为清华大学电子工程系汪玉教授、于超博后和第四范式研究员黄世宇博士。

头部模型的新一代模型的是市场观测、理解 LLM 走向的风向标。即将发布的 OpenAI GPT-Next 和 Anthropic Claude 3.5 Opus 无疑是 AGI 下半场最关键的事件。