
大模型价格战背后,真正稀缺的不是Token
大模型价格战背后,真正稀缺的不是TokenAnthropic在四月初发布Mythos,距离现在已经近一个月。行业内对于它的讨论,更多的关注点在于“它有多强”,但我更想聊聊它的“发布方式”。
来自主题: AI资讯
9244 点击 2026-05-08 09:53
 搜索
搜索
Anthropic在四月初发布Mythos,距离现在已经近一个月。行业内对于它的讨论,更多的关注点在于“它有多强”,但我更想聊聊它的“发布方式”。
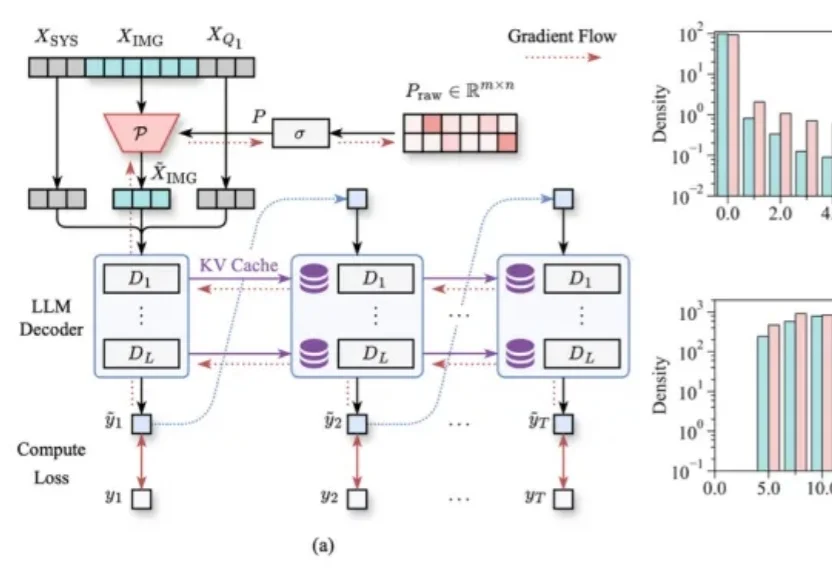
多轮视觉问答,正在成为LVLM推理效率的“照妖镜”。
近日,这家公司宣布此前已再获超7亿元融资。这个融资规模,稳稳位居国内AI原生基础设施企业第一梯队,也是国内底层AI赛道成长速度最惊人的新锐企业之一。

当地时间 5 月 5 日,迈阿密一家名为 Subquadratic 的公司走出隐身模式。CTO Alexander Whedon 在 X 上把首款模型 SubQ 称作“a major breakthrough in LLM intelligence”(LLM 智能领域的重大突破),

今日,云启种子轮领投项目「魔形智能」宣布完成数亿元人民币 Pre-A 轮融资。自成立以来,魔形智能围绕“Token 超级工厂”持续构建技术与交付能力,专注于为全球 AGI 产业提供高性能、高质量、高附加值的 Token 产品。
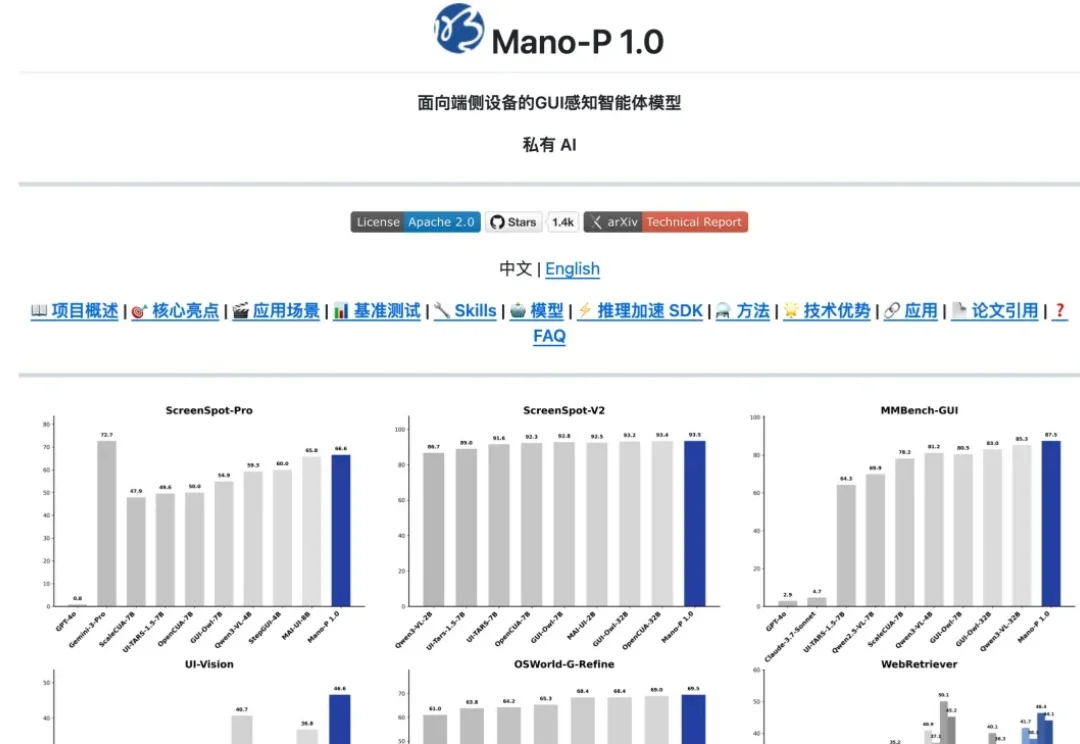
上次给大家分享了一个 CUA 的开源项目,能让 AI Agent 直接操控电脑界面,相当于把任何 App 都变成 Agent 的 Skill。反响还不错。
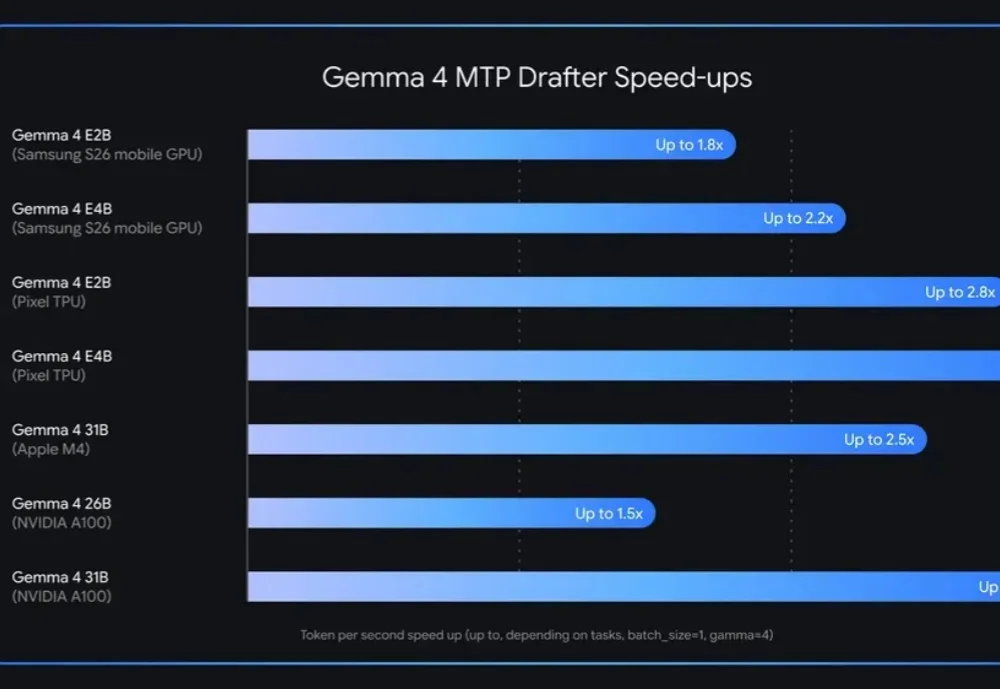
谷歌刚刚给Gemma 4家族更新了一项关键能力:Multi-Token Prediction(MTP)推测解码架构,推理速度最高提升3倍,输出质量不变。

Realtime API 是 OpenAI 的实时语音交互接口,在 24 年的 DevDay 首次亮相,当时还是 beta,调用贵到离谱,音频输出 200 刀/百万 token:OpenAI 凌晨发布:Realtime 实时多模态 API,及其他

迪士尼最近就做了一件「很不迪士尼」的事。它在内网上线了一块看板,名字直白得不像那个出品白雪公主的公司——「AI Adoption Dashboard」。看板上滚动着三个数字:每个员工调用AI的频率、请求次数、token消耗量。Claude是主要追踪对象。
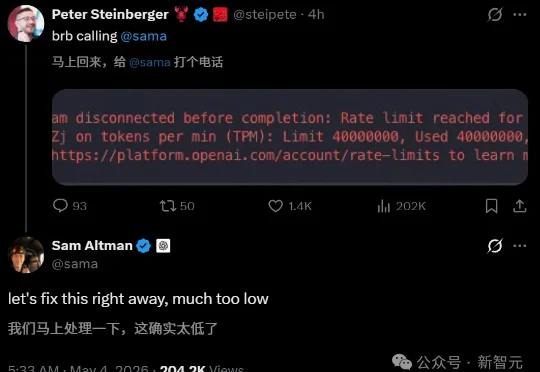
一分钟,4千万token,灰飞烟灭。 「龙虾之父」Peter Steinberger大概没想到,自己会以这种方式上热搜。今年2月他被Sam Altman亲自招入OpenAI,负责「下一代个人代理」的开发。