
永久底层:硅谷的AI从业者普遍认为,普通人已经“完蛋了”
永久底层:硅谷的AI从业者普遍认为,普通人已经“完蛋了”本文来自微信公众号: 不懂经 ,作者:不懂经也叔的Rust 一 国内一个投资人前不久去了一趟硅谷,然后写了一篇很长的复盘,题目叫《全员token-maxxing,一场没人敢停的军备竞赛》。他叫孟醒,五
来自主题: AI资讯
8084 点击 2026-05-04 19:54
 搜索
搜索
本文来自微信公众号: 不懂经 ,作者:不懂经也叔的Rust 一 国内一个投资人前不久去了一趟硅谷,然后写了一篇很长的复盘,题目叫《全员token-maxxing,一场没人敢停的军备竞赛》。他叫孟醒,五

OpenAI 和 Anthropic 几乎在同一时间发布自己的提示词文档,在 OpenAI 官网,从 GPT-4.1 到 GPT 5.5,每次新模型发布都有一份完整的提示词指南,告诉我们怎么用新的模型。
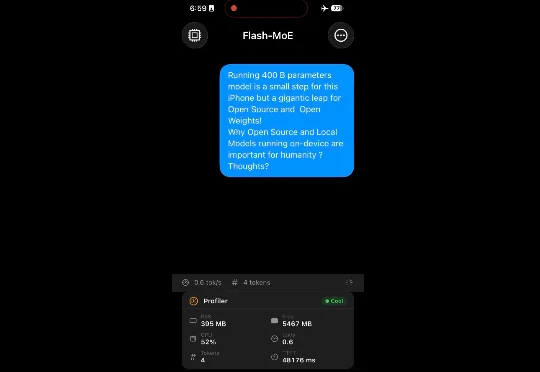
刚看到这个 Demo 的时候着实有些想笑,很久没有见过吐词如此之慢的大模型了。观感上就像「闪电」老师。尽管只有每秒 0.6 个 tokens 的输出速率,这依旧是一个令人不可思议的工作。因为这是一个跑在 iPhone 17 Pro 上的 400B 大模型!

刚刚的消息,Cloudflare 联合 Stripe 发布了一份新协议,Agent 现在可以独立成为 Cloudflare 的客户。它能自己创建账户、订阅付费方案、注册域名、拿到 API token,然后直接部署代码

在前不久的 AI TECH DAY 上,斑马智能又新发布了“元神 AI 汽车机器人大脑”,同时推出 AutoOmni 全模态端模型产品矩阵与“龙虾上车”方案 AutoClaw,构成所谓的“一脑双引擎”升级。这不只是一轮产品迭代,更像在做一次预判:汽车正在从功能的集合机器,变成一个可以持续进化、还能主动协作的的智能体系统。

来自华为泰勒实验室、北京大学和上海财经大学的研究团队提出了 SHAPE(Stage-aware Hierarchical Advantage via Potential Estimation),给推理链装上了一套「里程碑 + 推理税」机制——不仅告诉模型每一步推得对不对,还让它为啰嗦付出代价。结果是:准确率平均提升 3%,token 消耗直降 30%。
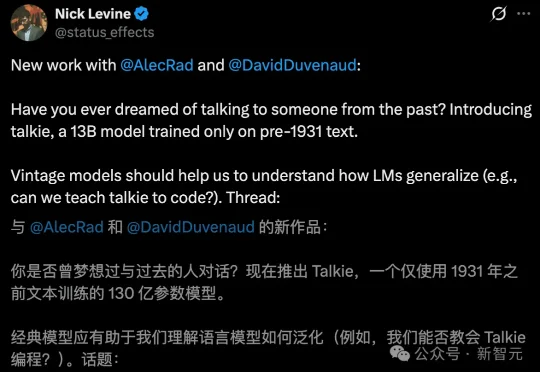
你敢信?一个活在95年前的AI,竟写出了Python代码。GPT之父下场,用2600亿Token炼出了一个「老古董」AI——「talkie」。
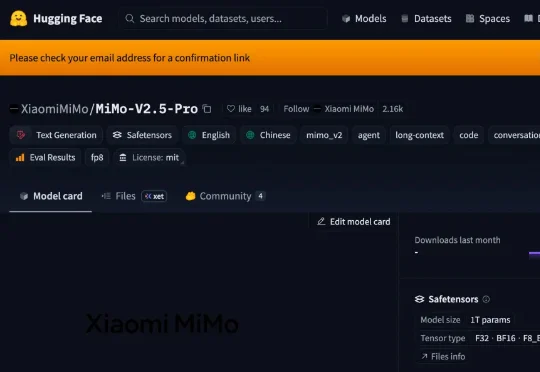
刚刚,小米开源罗福莉带队研发的MiMo-V2.5系列模型,采用MIT协议,允许商用推理部署与二次训练,无需额外授权。此前,该系列模型于4月23日开启公测,包括MiMo-V2.5-Pro、MiMo-V2.5两款模型。模型具备更强Agent能力,支持100万上下文,且Token效率大幅提升。
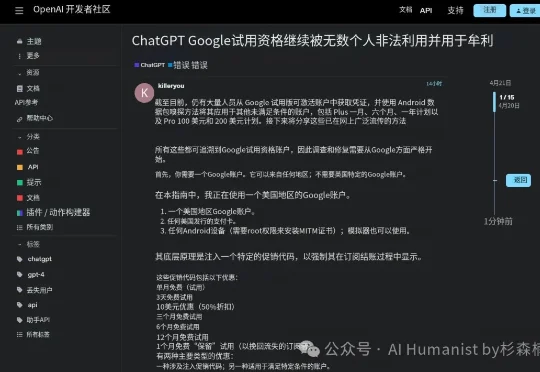
2026 年 4 月 21 日凌晨,OpenAI 开发者社区论坛上出现了一条帖子,Token 经济,人类史上「第一个叛徒」由此出现了:发帖的人叫 Killeryou。如果你混过中文技术社区,应该对这个名字不陌生。他过去两年一直活跃在 AI 工具的薅羊毛前线,属于那种既会写爬虫也会开店的角色。

昨晚,DeepSeek-V4又降价了,全系两款模型输入缓存命中的价格直接降至首发价格1/10。最新调价后,DeepSeek-V4-Flash每百万tokens输入(缓存命中)价格为0.02元,DeepSeek-V4-Pro为0.025元。