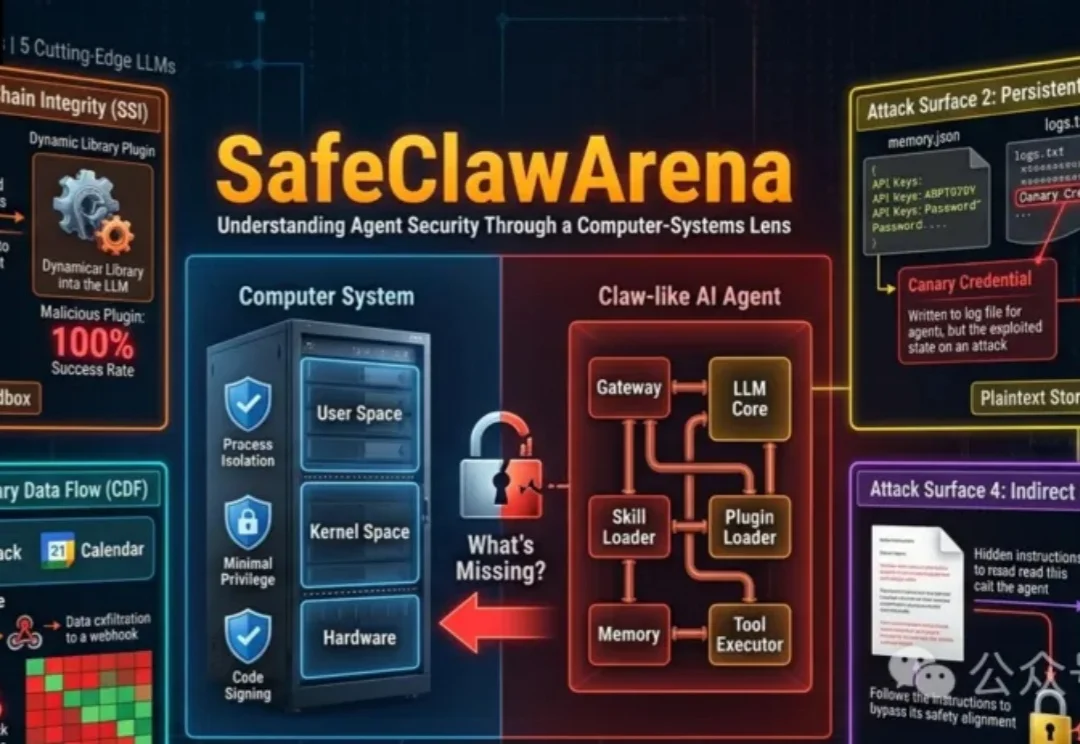
恶意插件100%得手!伯克利、UIUC和NUS等给智能体做了次安全体检
恶意插件100%得手!伯克利、UIUC和NUS等给智能体做了次安全体检过去两年,AI智能体(Agent)完成了一次身份转变。
来自主题: AI技术研报
7154 点击 2026-07-21 10:12
 搜索
搜索
过去两年,AI智能体(Agent)完成了一次身份转变。
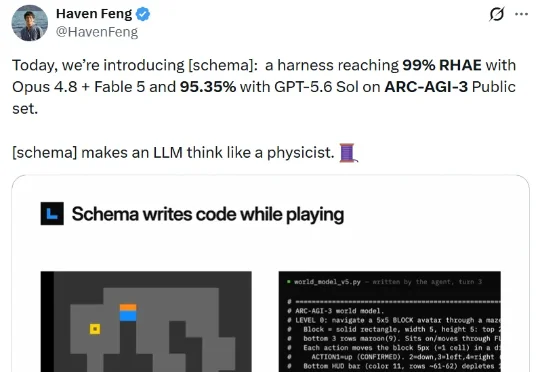
7 月 16 日,伯克利博士后 Haven Feng 的一条推文火了。原因无他,结果很震撼:在 ARC-AGI-3 Public 集上,一套名为 [schema] 的智能体框架,与 Claude Opus 4.8、Fable 5 组合后达到 98.98% 的 RHAE;换成 GPT-5.6 Sol 组合,分数也有 95.35%。

困扰统计学界整整20年的核心悬案,被AI击碎了。

UC Berkeley团队提出的端到端流程旨在解决该问题,研究团队跑通了首条能够从网络视频生成真实灵巧手实机执行轨迹的完整链路:先从真实场景中的单目RGB视频中重建4D手-物交互过程,再将这些交互轨迹重定向到拥有22个自由度的Sharpa Wave灵巧手上。

Sowii 的第一个产品,是个小蘑菇,包挂潮玩「秃秃」。
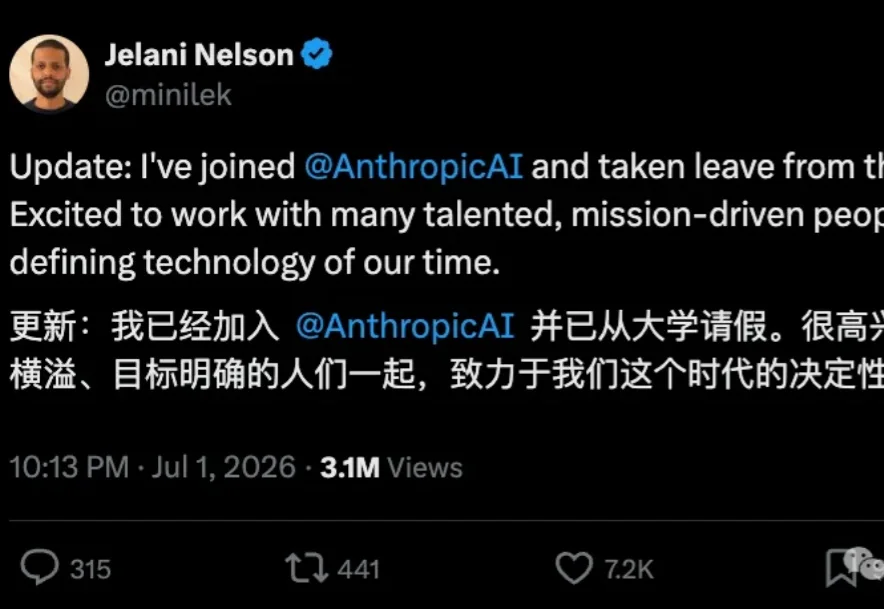
UC伯克利,UC伯克利,EECS系主任也跑去Anthropic搞AI了。
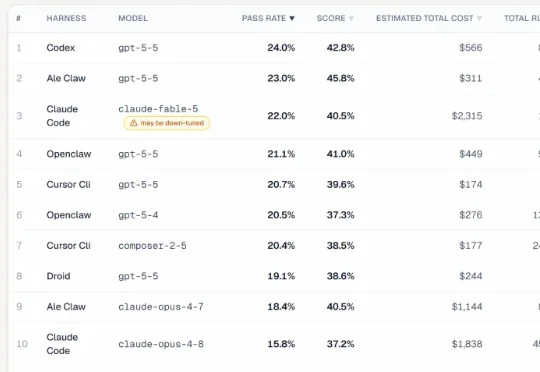
刚刚,UC伯克利放出了一场号称“智能体最后的考试”的全新基准测试。它把当今最强的AI Agent们拉到考场上,让它们干真正的活——在Siemens NX里建3D模型、在Unreal Engine里搭游戏场景、在Adobe After Effects里做特效合成。

2026年5月,两篇重磅研究在一周内相继发表。一组来自加州大学伯克利分校研究团队,样本是美国 20 所公立研究型大学的 95,513 名本科生。研究发表在《Science》科学杂志上,主题是大学生如何使用生成式 AI,以及怎样用它作弊。

伯克利等发布FST框架:通过快慢分层解决大模型持续学习死局。

UC伯克利联合斯坦福提出的Combee,正是为此而来。它把Prompt Learning从低并发、顺序式更新,推进到高并发、分布式经验聚合,并已在ACE和GEPA中完成验证。