Cell | 想做多模态和可解释性一定要看,这篇论文不仅方法可圈可点,图也绘制的非常漂亮!
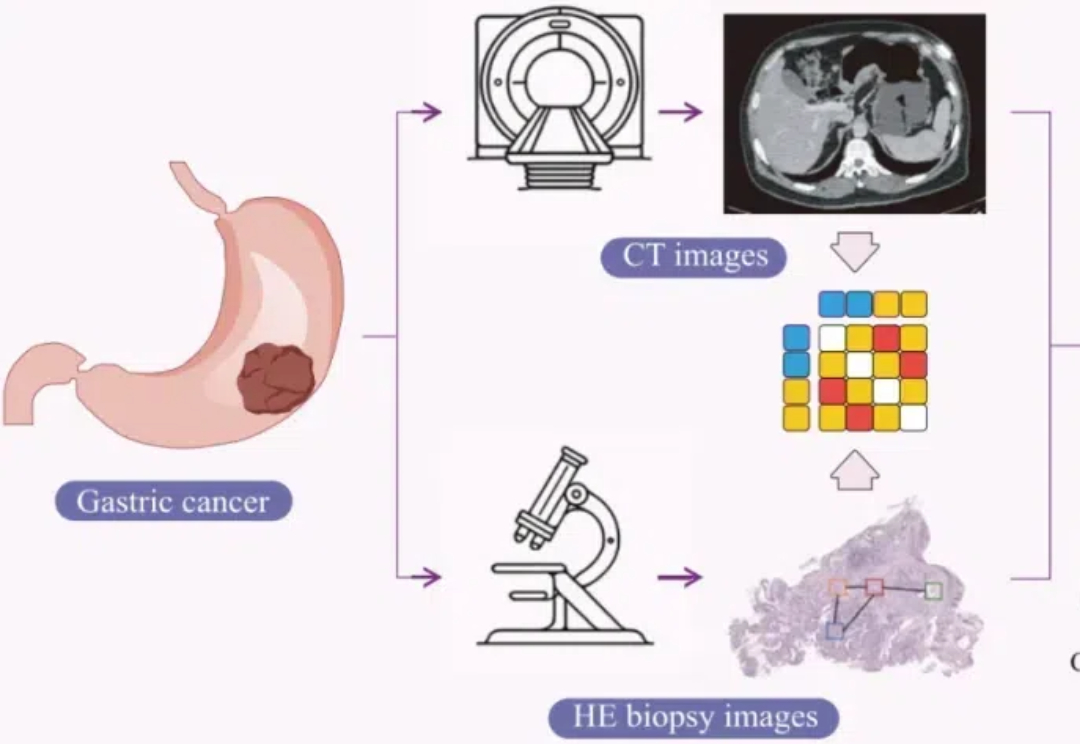
Cell | 想做多模态和可解释性一定要看,这篇论文不仅方法可圈可点,图也绘制的非常漂亮!Cell Reports Medicine近期的研究结合CT和病理图像,提出一种可解释的人工智能框架用于预测胃癌患者新辅助化疗的疗效。
来自主题: AI技术研报
8291 点击 2024-12-09 10:58
 搜索
搜索
Cell Reports Medicine近期的研究结合CT和病理图像,提出一种可解释的人工智能框架用于预测胃癌患者新辅助化疗的疗效。
Claude团队三巨头同时接受采访,回应一切。 整整5个小时,创始人Dario Amodei、Claude性格设计师Amanda Askell、机制可解释性先驱Chris Olah无所不谈,透露了关于模型、公司和行业的很多内幕和细节。

近日,中科大王杰教授团队(MIRA Lab)和华为诺亚方舟实验室(Huawei Noah's Ark Lab)联合提出了可生成具有成千上万节点规模的神经电路生成与优化框架,具备高扩展性和高可解释性,这为新一代芯片电路逻辑综合工具奠定了重要基础。论文发表在 CCF-A 类人工智能顶级会议 Neural Information Processing Systems(NeurIPS 2024)。

北京大学的研究人员开发了一种新型多模态框架FakeShield,能够检测图像伪造、定位篡改区域,并提供基于像素和图像语义错误的合理解释,可以提高图像伪造检测的可解释性和泛化能力。
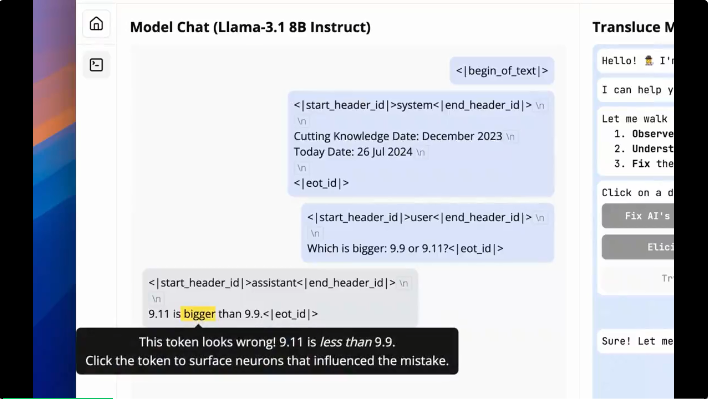
大模型分不清“9.9和9.11哪个更大”的谜团,终于被可解释性研究揭秘了!
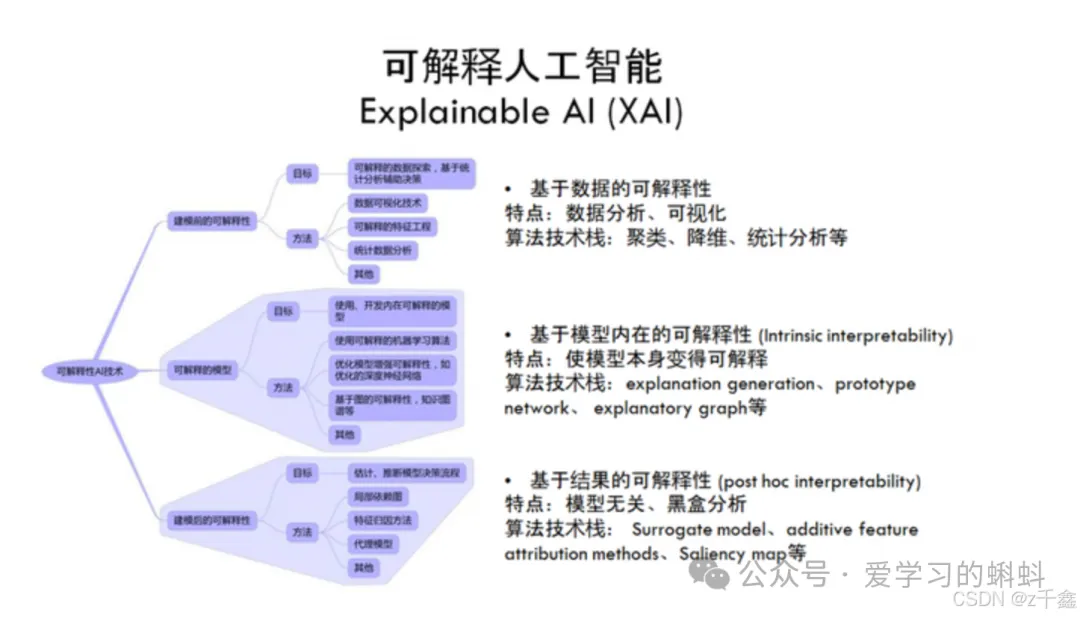
在当今人工智能(AI)和机器学习(ML)技术迅猛发展的背景下,解释性AI(Explainable AI, XAI)已成为一个备受关注的话题。

Goodfire于2024年在旧金山成立,研发用于提高生成式AI模型内部运作可观察性的开发工具,希望提高AI系统的透明度和可靠性,帮助开发者更好地理解和控制AI模型。

神经网络是一种灵活且强大的函数近似方法。而许多应用都需要学习一个相对于某种对称性不变或等变的函数。图像识别便是一个典型示例 —— 当图像发生平移时,情况不会发生变化。等变神经网络(equivariant neural network)可为学习这些不变或等变函数提供一个灵活的框架。

随着人工智能技术的广泛应用,人们认为AI可以避免人类常见的认知偏差。然而,AI本身可能会表现出类似于人类的偏差,例如锚定效应。本文通过回顾“系统1”和“系统2”两个思维模式,探讨AI在这两种模式中的运作方式,分析AI产生认知偏差的原因,并通过具体实验展示AI在面对锚定效应时的表现。本文进一步探讨如何在理解这些局限性的基础上,合理利用AI来改善人类决策质量,并强调AI透明性和可解释性的重要性。

让模型具有更加广泛和通用的认知能力,是当前人工智能(AI)领域发展的重要目标。目前流行的大模型路径是基于 Scaling Law (尺度定律) 去构建更大、更深和更宽的神经网络提升模型的表现,可称之为 “基于外生复杂性” 的通用智能实现方法。然而,这一路径也面临着一些难以克服的困境,例如高昂的计算资源消耗和能源消耗,并且在可解释性方面存在不足。