
“计算机视觉被GPT-4o终结了”(狗头)
“计算机视觉被GPT-4o终结了”(狗头)一夜之间,CV被大模型“解决”了(狗头)。万物皆可吉卜力之后,GPT-4o原生多模态图像生成更多玩法被开发出来。万物皆可吉卜力之后,GPT-4o原生多模态图像生成更多玩法被开发出来。
来自主题: AI资讯
8743 点击 2025-03-30 10:43
 搜索
搜索
一夜之间,CV被大模型“解决”了(狗头)。万物皆可吉卜力之后,GPT-4o原生多模态图像生成更多玩法被开发出来。万物皆可吉卜力之后,GPT-4o原生多模态图像生成更多玩法被开发出来。
GPT4o的多模态生图前天上线之后。经过两天的发酵,含金量还在不断提升。
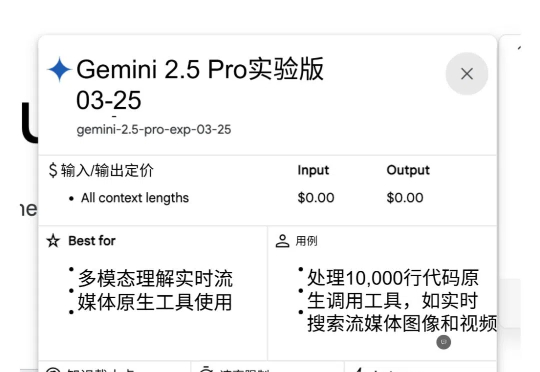
又双叒,抢在OpenAI直播之前,谷歌Gemini 2.5系列来了。首个版本Pro Experimental一登场就抢下大模型竞技场第一名,并且整整比GPT-4.5高出40分Gemini 2.5同样是推理模型,用Jeff Dean的说法是:
在ChatGPT上,当你画图的选项变成这个的时候,就说明用的不是Dalle3了,而是4o。目前,有两个渠道可以使用4o Image Generation。一个事ChatGPT,一个是单独的那个Sora的网站。
在引发全球关注的同时,全球资本对中国科技资产的重新评估与 AI 投资的底层逻辑也悄然发生转变。尤其是在大模型领域,过去巨额投入却屡次推迟的ChatGPT5和本就步入下半场的国内六小龙,将直面 DeepSeek这匹黑马的强劲冲击。中国AI企业在DeepSeek突破了“算力禁运”之后,正面临高质量数据稀缺的挑战,尤其是高质量、低成本、多种类、多模态的数据,将成为未来 AI 产业发展的核心关键。
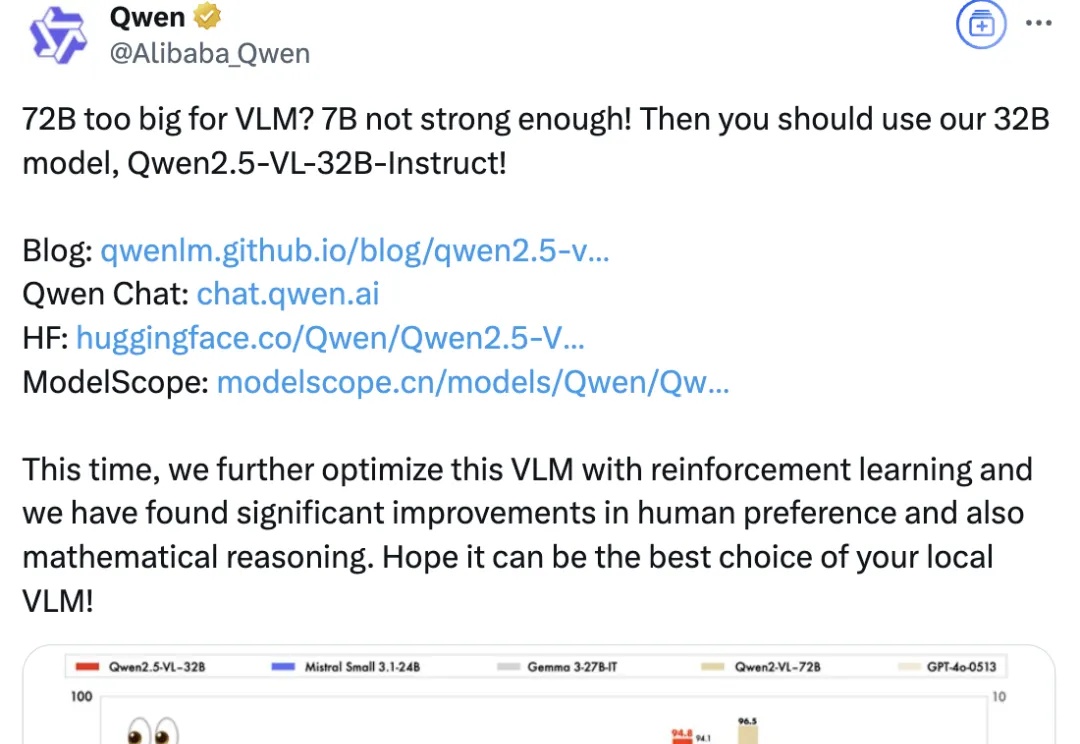
就在DeepSeek-V3更新的同一夜,阿里通义千问Qwen又双叒叕一次梦幻联动了——
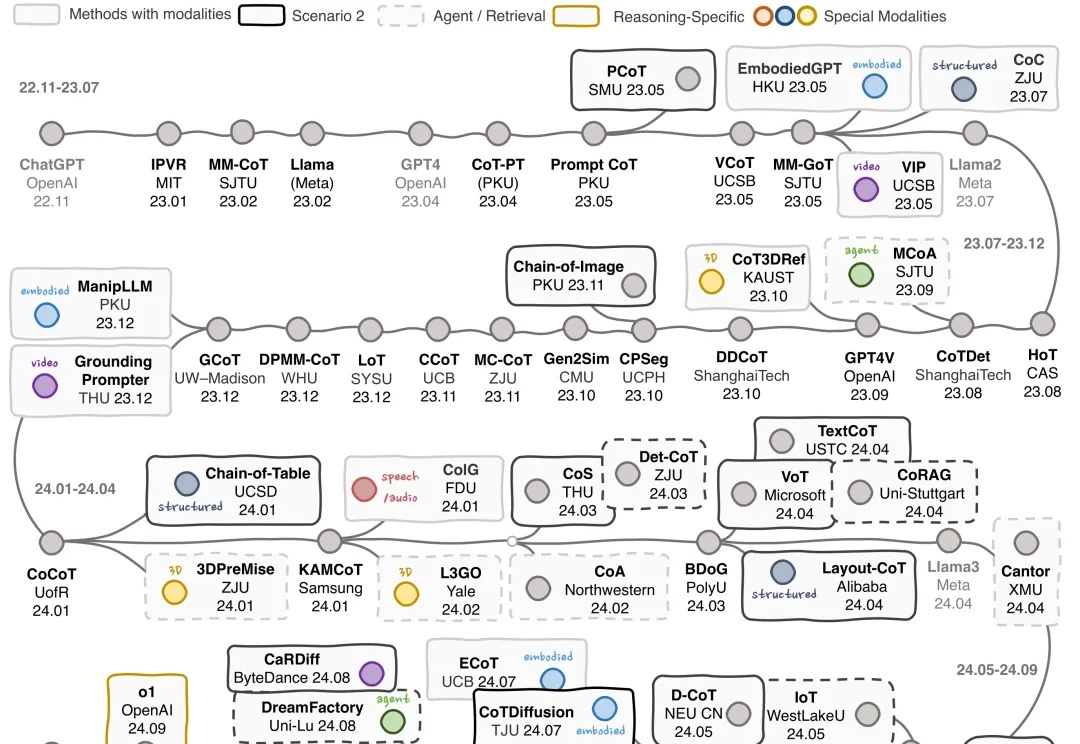
多模态思维链(MCoT)系统综述来了!
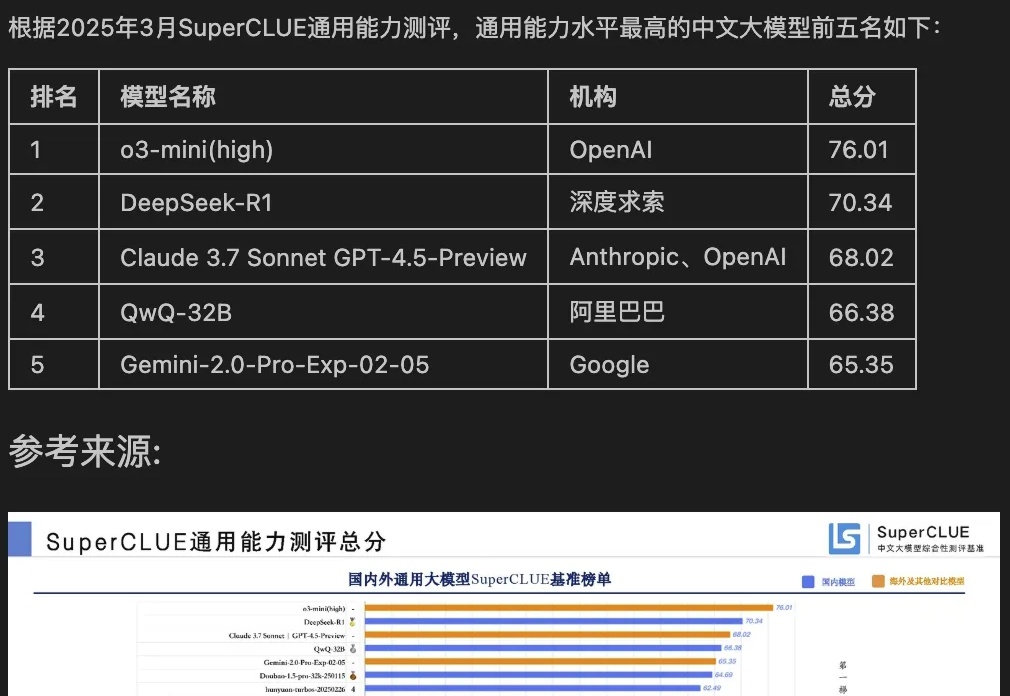
RAG应用的一大复杂性体现在其多样的原始知识结构与表示。特别在企业场景下,混合多种媒体形式且具有复杂布局的文档随处可见,比如一份PPT:
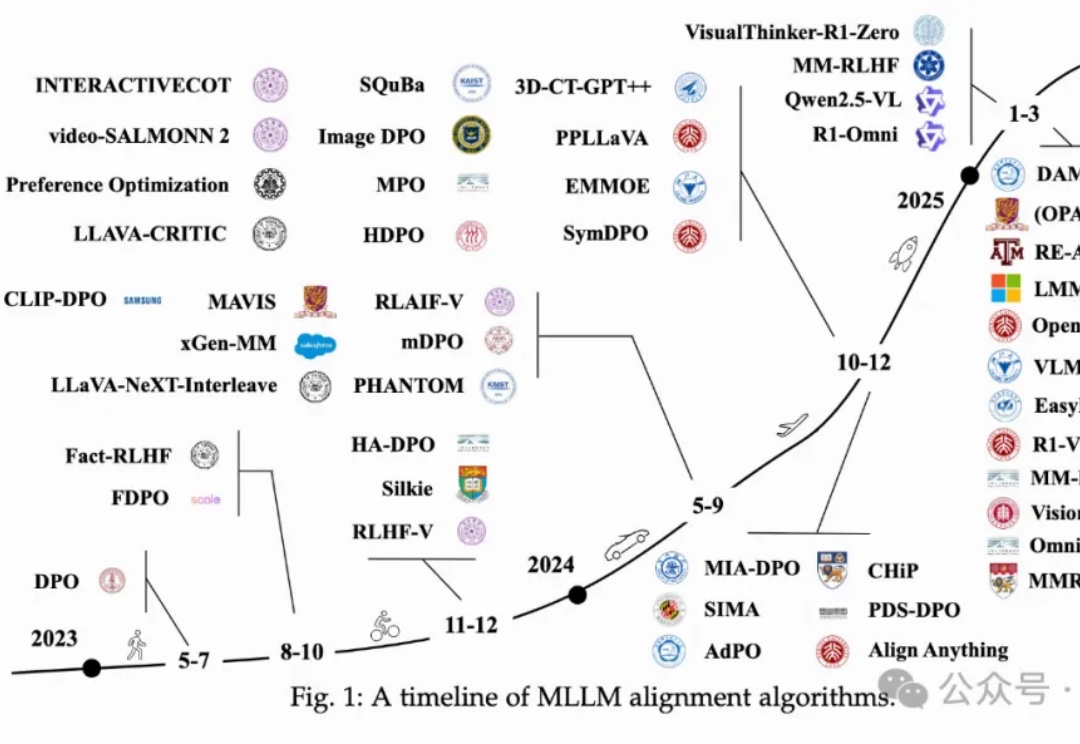
万字长文,对多模态LLM中对齐算法进行全面系统性回顾!

国产厨电龙头老板电器出品的全球首个烹饪大模型「食神」升级,不光接入了DeepSeek,还拓展了多模态。像推荐菜谱、指导烹饪已经是常规操作。在此基础上,它还能一眼看出你的健康状况——通过面部识别、分析体检报告,生成长期的健康膳食计划。